P300是大脑认知过程中产生的一种事件相关电位,主要与期待、意动、觉醒、注意等心理因素有关。Sutton等人发现,当人脑受到小概率相关事件的刺激时,脑电信号中会出现一个潜伏期约为300ms的正向波峰,P300因此得名。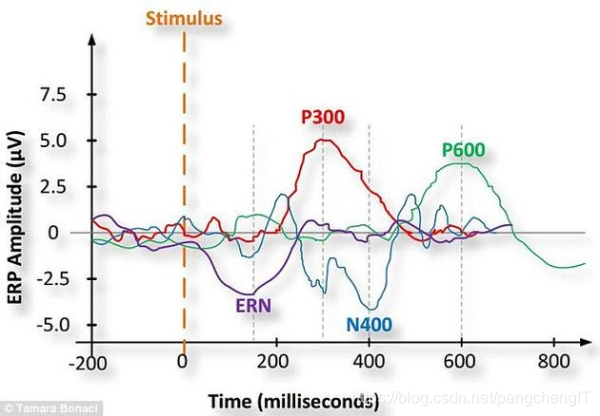
P300脑机接口
在基于P300的oddball刺激范式 BCI 系统研究中,最经典的应用是Farwell和Donchin在 1988年提出并设计的字符拼写器简称为P300 Speller。如下图所示,使用26个英文字母和 1-9个数字以及下划线排列成 6 x 6 的虚拟键盘矩阵。随机高亮字符矩阵的某一行或某一列,一次实验中6 x 6列均被高亮亮一次,一共12次高亮刺激。受试者必须将注意力集中在矩阵中的字符上,以此来选择组成单词的每个字母。当包括此字符的行或者包含此字符的列被高亮时(也就是oddball范式中的靶刺激),要求受试者对此做出反应,予以计数,会产生P300波形;当不包含此字符的行或者列加亮时,被试不做出反应,不予计数,不会产生P300波形,通过解析脑电信号中的P300时序位置,并对照刺激序列的时序,进而确定刺激的行列位置,从而确定出受试者注视的字符,达到根据思维打字的目的。为了有助于保持受试者的注意力,通常要求受试者对目标字符高亮的次数进行计数。值得注意的是重复高亮次数越多,识别准确率越好,但会增加拼写时间。再者每一个字符也可以代表着一个控制指令,从而可以实现36个控制指令。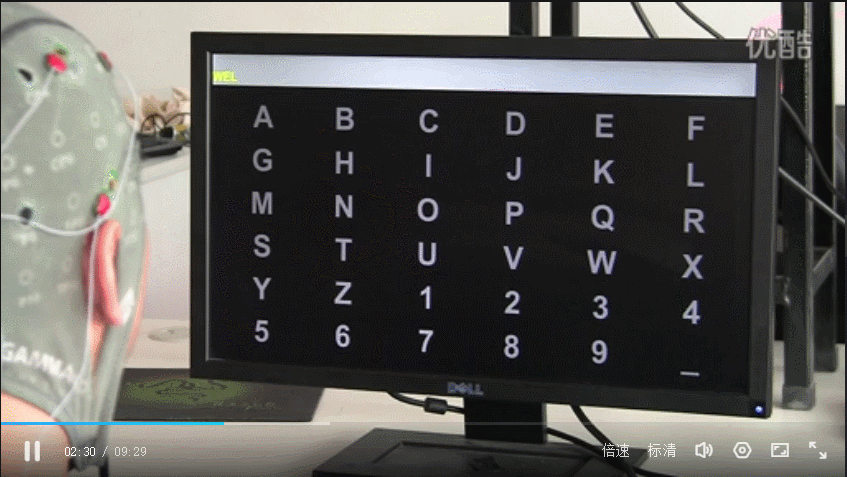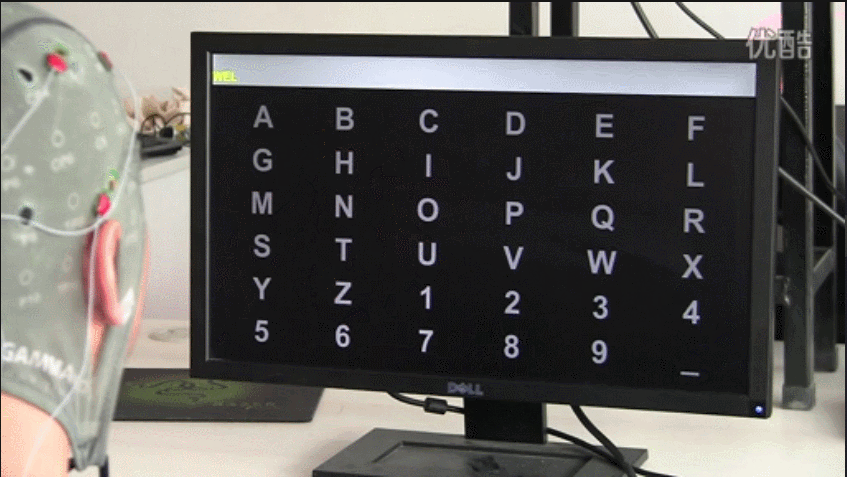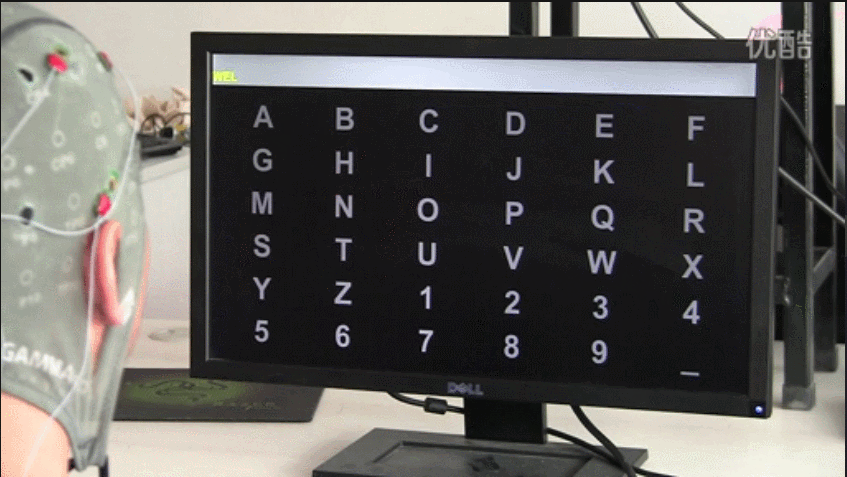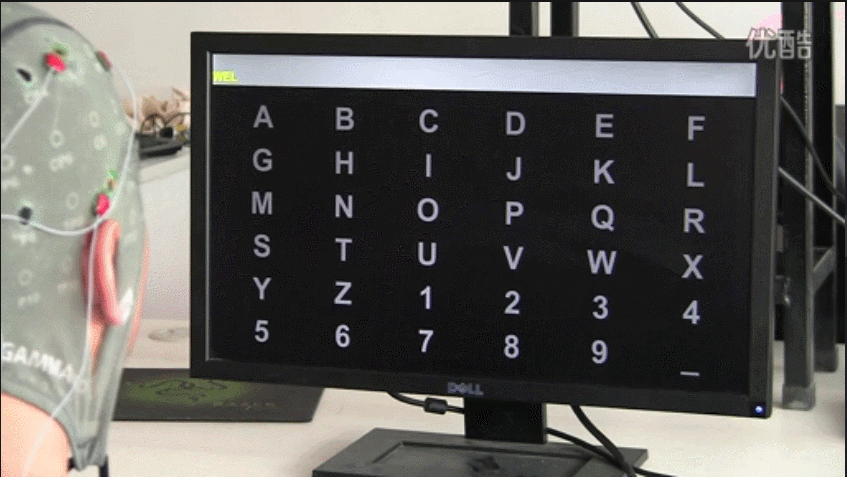
p300数据集
1、整个P300数据由基于Oddball范式的P300字符实验产生,实验过程如下:实验过程由一名被试者完成,字符矩阵的显示周期为2.5s,在这个周期内,字符矩阵的每行或列均被随机地加亮一次,加亮的持续时间为lOOms,两次加亮之间的时间间隔为75ms:对于每个目标字符,受试者需连续重复进行15次实验,即要经历15个字符矩阵显示周期,因此对于一个目标字符,字符矩阵会进行12×15次加亮。
第一节各段的目标字符分别为CAT,DOG,FISH,WATER,BOWL;
第二节各段的目标字符分别为HAT,HAT,GLOVE,SHOES,FISH,RAT;
第三节各段的目标字符为FOOD,MOOT,HAM,PIE,CAKE,TUNA,ZYGOT,4567。
在实验过程中,设备通过位于受试者脑部头皮上的64个采样电极,以240Hz的采样频率记录脑电信号。并将记录的信号分为三节,每节信号又根据英文单词或字符组的不同分成许多段。其中第一节(Session 10)包括5个段,第二节(Session 11)包括6个段,第三部分(Session 12)包括8个段。每段数据存储为一个Matlab数据格式文件,如第一节第四段的实验数据存储为文件“AAS010R04”,第二节第六段的实验数据存储为文件“AAS011R06”。
2、AAS011R06中有多个数组,数据集中的信号存放在signal的2维数组中,64个电极的采样点
p300数据集
MATLAB处理数据集
1、代码包含绘制cat的时域图,字符的时域图。
2、如cat,把64个电极采样结果平均,再把字符c的15个周期取平均,就得到了字符c在一个字符矩阵显示周期的时域图了
load('AAS010R01.mat');
y=sum(signal,2)/64;
t=(0:length(y)-1)/240;
%-------------------------------------------%
figure(1)
plot(t(1:8776),y(1:8776),'g')
hold on
plot(t(8776:17752),y(8776:17752),'r')
hold on
plot(t(17753:26328),y(17753:26328),'b')
title('CAT')
axis([t(1) t(end)+10 -1.2*max(y) 1.2*max(y)]);
%------------------------------------------%
figure(2)
subplot(3,1,1)
y=y/10;
t=(0:length(y)-1)/240;
plot(t,y)
title('CAT:0-5秒')
wow=t(1200);
axis([0 wow -400 400]);
subplot(3,1,2)
plot(t,y)
title('CAT:35-40秒')
axis([35 40 -400 400]);
subplot(3,1,3)
plot(t,y)
title('CAT:70-75秒')
axis([70 75 -400 400]);
%------------------------------------------%
a=1:585;b=8777:9361;c=17553:18137;
z_1=y(a);z_2=y(b);z_3=y(c);
s_1=z_1;s_2=z_2;s_3=z_3;
for k=1:14
a=a+585;b=b+585;c=c+585;
z_1=y(a);z_2=y(b);z_3=y(c);
s_1=s_1+z_1;s_2=s_2+z_2;s_3=s_3+z_3;
end
s_1=s_1/15;s_2=s_2/15;s_3=s_3/15;
v=(0:584)/240;
figure(3)
subplot(3,1,1)
plot(v,s_1)
title('15周期平均后字符c波形')
subplot(3,1,2)
plot(v,s_2)
title('15周期平均后字符a波形')
subplot(3,1,3)
plot(v,s_3)
title('15周期平均后字符t波形')
结果展示
一个段数据的实验过程时域图(26328/240=109.7秒)
26328个采样点,240为采样频率,一个字符的输入时间大概为36.56秒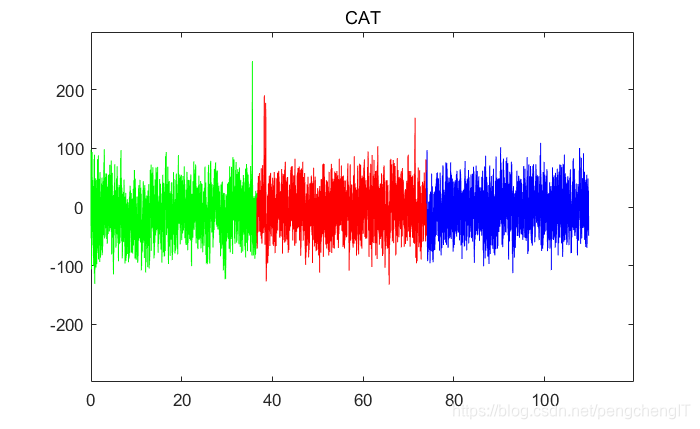
把信号放大,取其中5秒来看(0-5,35-40,70-75秒)
可以明显的观察出突出的p300波形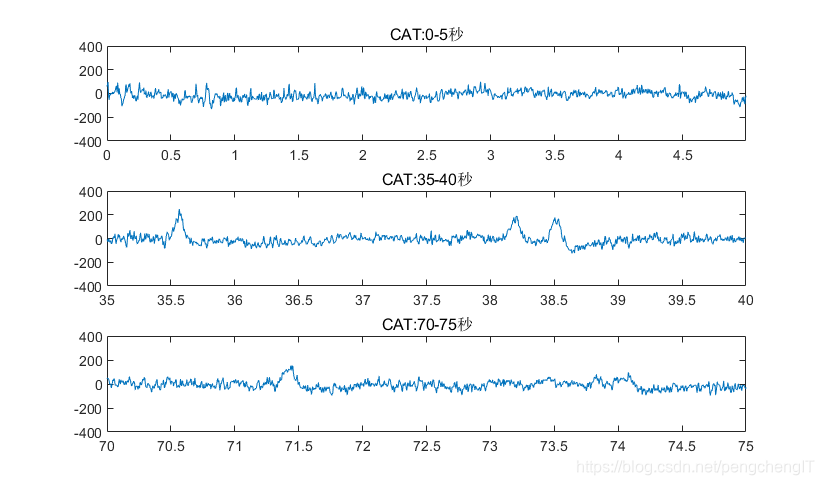
将cat段每个字符的取15个周期的平均值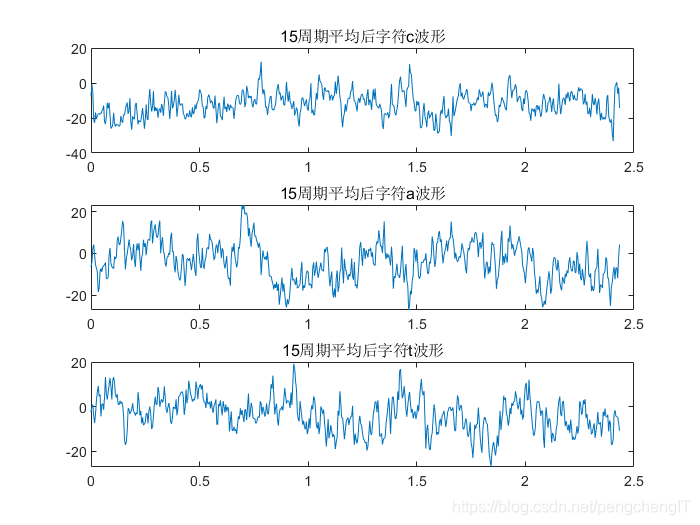
P300频率
它是以delta(0.5-4hz)脑波为主要贡献和theta(4-7.5hz)脑波响应的融合
进一步分析,可以添加滤波部分,可以把上面生成波通过低通滤波器,在MATLAB中filter designer工具箱中生成阻带12hz,通带8hz的滤波器
Hd = lowfilter;
%引入滤波器,Hd包含了lowfilter滤波器的各项参数
d_1 = filter(Hd,s_1);
%通过filter函数将信号y送入参数为Hd的滤波器,输出信号d_1
d_2 = filter(Hd,s_2);
%通过filter函数将信号y送入参数为Hd的滤波器,输出信号d_2
d_3 = filter(Hd,s_3);
%通过filter函数将信号y送入参数为Hd的滤波器,输出信号d_3
figure(4)
subplot(3,1,1)
plot(v,d_1);%画出通过滤波器的信号d_1的波形
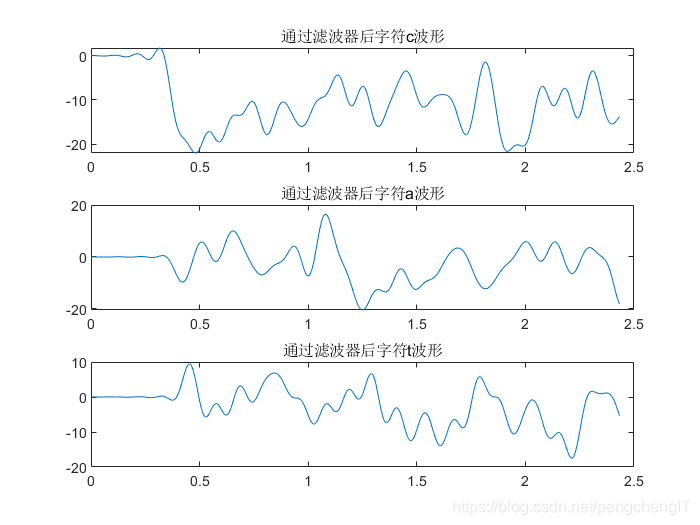
title('通过滤波器后字符c波形')
subplot(3,1,2)
plot(v,d_2);%画出通过滤波器的信号d_2的波形
title('通过滤波器后字符a波形')
subplot(3,1,3)
plot(v,d_3);%画出通过滤波器的信号d_3的波形
title('通过滤波器后字符t波形')
效果展示