SparkStreming程序消费kafka数据实时写入ES集群程序报错,以下是dolphinscheduler任务实例的报错日志: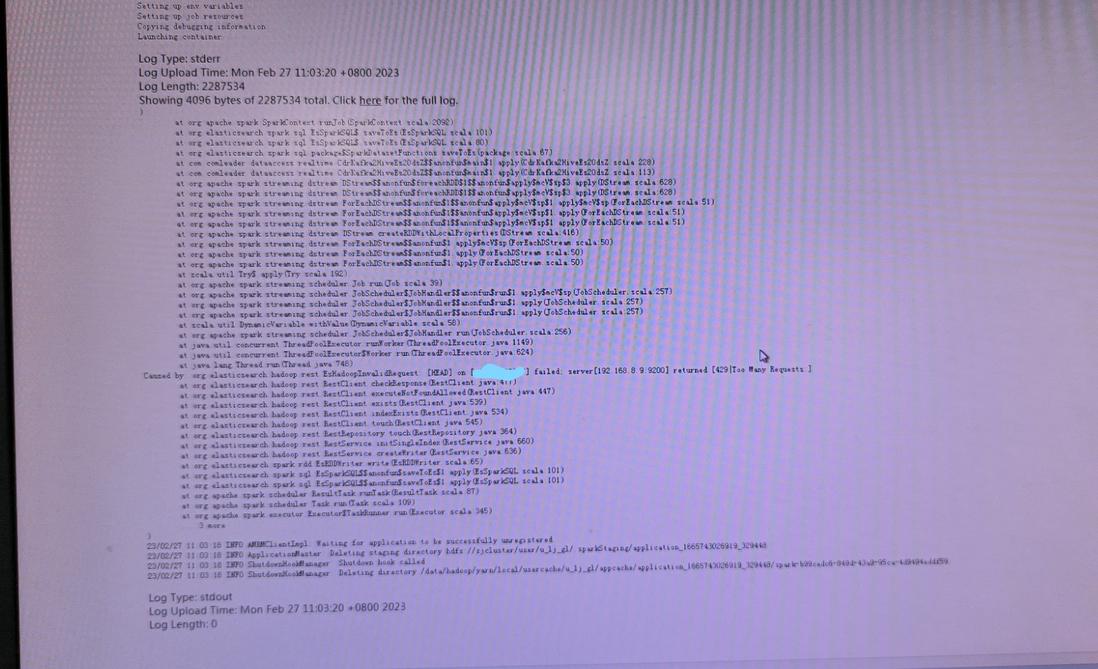
查看代码本程序下游输出不止有ES,还有hive分区表,逻辑上先写hive分区表再写ES,先从逻辑上进行业务拆分,将写hive和写ES进行任务拆分,保证写入hive的数据任务正常。
拆分以后写ES的日志报Elasticsearch 429请求过多错误,查看同事的代码发现索引为每天通过脚本定时创建的,但是并未指定分片和副本数等参数,创建index时候指定以下参数:
"settings":{
"index.refresh_interval":60s,
"number_of_shards":7,
"number_of_replicas":1
}修改后程序每次都可以执行几分钟,但是还是会失败,报错日志如下:
[INFO] 2023-03-07 18:23:14.883 - [taskAppId=TASK-278-489615-614198]:[138] - -> 23/03/07 18:23:14 INFO Client: Application report for application_1665743026919_354608 (state: RUNNING)
[INFO] 2023-03-07 18:23:15.884 - [taskAppId=TASK-278-489615-614198]:[138] - -> 23/03/07 18:23:15 INFO Client: Application report for application_1665743026919_354608 (state: RUNNING)
[INFO] 2023-03-07 18:23:16.885 - [taskAppId=TASK-278-489615-614198]:[138] - -> 23/03/07 18:23:16 INFO Client: Application report for application_1665743026919_354608 (state: RUNNING)
[INFO] 2023-03-07 18:23:17.628 - [taskAppId=TASK-278-489615-614198]:[445] - find app id: application_1665743026919_354608
[INFO] 2023-03-07 18:23:17.628 - [taskAppId=TASK-278-489615-614198]:[238] - process has exited, execute path:/data/dolphinscheduler/exec/process/6/278/489615/614198, processId:13743 ,exitStatusCode:1 ,processWaitForStatus:true ,processExitValue:1
[INFO] 2023-03-07 18:23:17.885 - [taskAppId=TASK-278-489615-614198]:[138] - -> 23/03/07 18:23:17 INFO Client: Application report for application_1665743026919_354608 (state: FINISHED)
23/03/07 18:23:17 INFO Client:
client token: N/A
diagnostics: User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 5, udap-ambari092, executor 5): org.elasticsearch.hadoop.EsHadoopIllegalStateException: Cluster state volatile; cannot find node backing shards - please check whether your cluster is stable
at org.elasticsearch.hadoop.rest.RestRepository.getWriteTargetPrimaryShards(RestRepository.java:262)
at org.elasticsearch.hadoop.rest.RestService.initSingleIndex(RestService.java:688)
at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:636)
at org.elasticsearch.spark.rdd.EsRDDWriter.write(EsRDDWriter.scala:65)
at org.elasticsearch.spark.sql.EsSparkSQL$$anonfun$saveToEs$1.apply(EsSparkSQL.scala:101)
at org.elasticsearch.spark.sql.EsSparkSQL$$anonfun$saveToEs$1.apply(EsSparkSQL.scala:101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1651)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1639)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1638)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1638)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1872)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1821)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1810)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2039)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2060)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2092)
at org.elasticsearch.spark.sql.EsSparkSQL$.saveToEs(EsSparkSQL.scala:101)
at org.elasticsearch.spark.sql.EsSparkSQL$.saveToEs(EsSparkSQL.scala:80)
at org.elasticsearch.spark.sql.package$SparkDatasetFunctions.saveToEs(package.scala:67)
org.apache.spark.streaming.dstream.DStream$$anonfun$foreachRDD$1$$anonfun$apply$mcV$sp$3.apply(DStream.scala:628)
at org.apache.spark.streaming.dstream.DStream$$anonfun$foreachRDD$1$$anonfun$apply$mcV$sp$3.apply(DStream.scala:628)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ForEachDStream.scala:51)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply(ForEachDStream.scala:51)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply(ForEachDStream.scala:51)
at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:416)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply$mcV$sp(ForEachDStream.scala:50)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply(ForEachDStream.scala:50)
at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply(ForEachDStream.scala:50)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.streaming.scheduler.Job.run(Job.scala:39)
at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply$mcV$sp(JobScheduler.scala:257)
at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply(JobScheduler.scala:257)
at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply(JobScheduler.scala:257)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58)
at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.run(JobScheduler.scala:256)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.elasticsearch.hadoop.EsHadoopIllegalStateException: Cluster state volatile; cannot find node backing shards - please check whether your cluster is stable
at org.elasticsearch.hadoop.rest.RestRepository.getWriteTargetPrimaryShards(RestRepository.java:262)
at org.elasticsearch.hadoop.rest.RestService.initSingleIndex(RestService.java:688)
at org.elasticsearch.hadoop.rest.RestService.createWriter(RestService.java:636)
at org.elasticsearch.spark.rdd.EsRDDWriter.write(EsRDDWriter.scala:65)
at org.elasticsearch.spark.sql.EsSparkSQL$$anonfun$saveToEs$1.apply(EsSparkSQL.scala:101)
at org.elasticsearch.spark.sql.EsSparkSQL$$anonfun$saveToEs$1.apply(EsSparkSQL.scala:101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
... 3 more
ApplicationMaster host: 192.18.10.1
ApplicationMaster RPC port: 0
queue: default
start time: 1678184482121
final status: FAILED
tracking URL: http://179:8088/proxy/application_1665743026919_354608/
user: data
Exception in thread "main" org.apache.spark.SparkException: Application application_1665743026919_354608 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1269)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1627)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:900)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:192)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:217)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
23/03/07 18:23:17 INFO ShutdownHookManager: Shutdown hook called
23/03/07 18:23:17 INFO ShutdownHookManager: Deleting directory /tmp/spark-efd3f080-2790-4f79-a038-dfd67759952b
23/03/07 18:23:17 INFO ShutdownHookManager: Deleting directory /tmp/spark-b066f7a0-615c-446d-be8b-225a997a5f2d
搜索"please check whether your cluster is stable"异常,并未找到有效的解决方案,在github上的ES源码中大致能看到此提示大致为ES申请资源时候获取的返回值为空时抛出此异常。
远程让运维登录到服务器中,查看ES的日志:
[2023-03-08T00:02:32,209][DEBUG][o.e.a.a.c.n.i.TransportNodesInfoAction] [udap_es01] failed to execute on node [UOMhau3rTmmVwi_IZL_9Jg]
org.elasticsearch.transport.RemoteTransportException: [host201][192.168.8.1:9300][cluster:monitor/nodes/info[n]]
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [<transport_request>] would be [7974463642/7.4gb], which is larger than the limit of [7969862451/7.4gb], real usage: [7974456176/7.4gb], new bytes reserved: [7466/7.2kb], usages [request=0/0b, fielddata=0/0b, in_flight_requests=7466/7.2kb, accounting=3182387216/2.9gb]
at org.elasticsearch.indices.breaker.HierarchyCircuitBreakerService.checkParentLimit(HierarchyCircuitBreakerService.java:342) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.common.breaker.ChildMemoryCircuitBreaker.addEstimateBytesAndMaybeBreak(ChildMemoryCircuitBreaker.java:128) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.transport.InboundHandler.handleRequest(InboundHandler.java:170) [elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.transport.InboundHandler.messageReceived(InboundHandler.java:118) [elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.transport.InboundHandler.inboundMessage(InboundHandler.java:102) [elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.transport.TcpTransport.inboundMessage(TcpTransport.java:663) [elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.transport.netty4.Netty4MessageChannelHandler.channelRead(Netty4MessageChannelHandler.java:62) [transport-netty4-client-7.4.0.jar:7.4.0]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:374) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:360) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:352) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.codec.ByteToMessageDecoder.fireChannelRead(ByteToMessageDecoder.java:328) [netty-codec-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:302) [netty-codec-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:374) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:360) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:352) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.logging.LoggingHandler.channelRead(LoggingHandler.java:241) [netty-handler-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:374) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:360) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:352) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.ssl.SslHandler.unwrap(SslHandler.java:1475) [netty-handler-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.ssl.SslHandler.decodeJdkCompatible(SslHandler.java:1224) [netty-handler-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.ssl.SslHandler.decode(SslHandler.java:1271) [netty-handler-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:505) [netty-codec-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:444) [netty-codec-4.1.38.Final.jar:4.1.38.Final]
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:283) [netty-codec-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:374) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:360) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:352) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1421) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:374) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:360) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:930) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:163) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:697) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeysPlain(NioEventLoop.java:597) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:551) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:511) [netty-transport-4.1.38.Final.jar:4.1.38.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:918) [netty-common-4.1.38.Final.jar:4.1.38.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) [netty-common-4.1.38.Final.jar:4.1.38.Final]
at java.lang.Thread.run(Thread.java:830) [?:?]问题原因找到:ES集群设置的JVM内存过小导致程序执行几分钟就会失败,修改ES集群的jvm.options 文件
-Xms16G
-Xmx16G保存后,elasticsearch -d重启集群后任务正常。