
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题。Tapdata 在解决 PostgreSQL 增量复制问题过程中,获得了一些不错的经验和思考,本文将分享 Tapdata 自研的 TAP-CDC-CACHE,和其他几种市面常见的解决方案的优势和特性。
前言
TAPDATA 的数据复制产品里, 提供了对于 PostgreSQL 的实时数据采集功能, 在客户落地使用时, 遇到了包括 对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂 等等问题, 在解决这些问题的过程中, 我们逐渐对增量事件应该具备一个缓存中间件有了清晰的认识, 并在之后的时间里做了相应的实现
本文从我们在解决 PostgreSQL 增量复制的问题出发, 在一步步寻找解决方案的过程中, 分享一下我们最终解决方案的过程和对这个问题的一些思考
PG 增量数据捕获的几种常见方案
万变不离其宗, PostgreSQL 捕获增量事件的原理与 Mysql, MongoDB 等数据库类似, 其本质都是基于事务日志进行回放, 这种日志在 PG 里被称为 Write-Ahead Logging(WAL), 通过对 WAL 的解析, 可以得到数据库的逻辑事件变更, 下游的各种消费者可以在这个基础上完成数据复制, 流计算等等各种需求
在具体的实现上, 通常有以下三种技术选型
基于复制槽的解码与查询
针对开发者进行数据逻辑复制的需求, PostgreSQL 开放了对于 WAL 的订阅接口, 开发者需要创建一个名为复制槽的结构, 并指定其解码插件, 之后只需要轮询这个复制槽, 即可获取最新的以事务为最小粒度的数据变更
常见的解码器有 decoderbufs, wal2json, pgoutput 等等, TAPDATA 支持的插件, 其对应的数据库版本与特点如下:

除此之外, 还有一些其他插件, 比如: decoding-json, decoder_json, jsoncdc, wal2mongo, postgres-decoderbufs, Bottled Water, osm-logical, pglogical, transicator 等等各式各样的输出格式, 用户可以按照自己的需求选择合适的插件, 也可以自己开发对应的解码器
以 wal2json 为例, 具体的使用命令如下:
## 创建一个 slot, 命名为 tapdata, 用来接收 CDC 事件, 并使用 wal2json 解析
select * from pg_create_logical_replication_slot('tapdata', 'wal2json');
## 查看 slot 基本信息
select * from pg_replication_slots where slot_name='tapdata';
## 从 slot 读取数据, 并清理读过的数据
## 方法支持的参数的为:
## 1. slot 名字, 必选
## 2. 一个 lsn 位置, 必选, 读取到这个位置为止, 剩下的此次查询不返回
## 3. 一个 limit 数字 n, 必选, 最多读取 n 条为止, 剩下的此次查询不返回, 与 lsn 满足任意一条即停止读取
## 4. options, 可选, 控制一些输出的数据内容, 具体可以查看: https://pgpedia.info/p/pg_logical_slot_get_changes.html
select * from pg_logical_slot_get_changes('tapdata', NULL, NULL)
## 从 slot 读取数据, 保留读过的数据, 参数与 pg_logical_slot_get_changes 完全一致
select * from pg_logical_slot_peek_changes('tapdata', NULL, NULL)
## select 支持使用 xid, lsn 等条件进行过滤, 比如限制返回的条目数为 10, 并且 lsn > '1/47CB8450', 可如下写
select * from pg_logical_slot_peek_changes('tapdata', NULL, NULL) where lsn > '1/47CB8450' limit 10
## 由于 pg_logical_slot_peek_changes 不清理数据, 在需要清理 lsn 时, 可以使用 pg_replication_slot_advance
## 将 lsn 推进到指定位置, 并清理之前的记录
select * from pg_replication_slot_advance('tapdata', '1/47CB8450')这个方案的优势是使用便捷, 创建复制槽后, 可以方便使用 SQL 查询增量数据
方案的问题有很多, 我们遇到的列举在下面:
- 虚拟 CDC 表不包含任何索引, 使用 where 条件查询性能很糟糕
- 使用 pg_logical_slot_get_changes 会清除已经读取的数据, 无法实现多任务的数据复用, 只能创建多个互不关联的 slot 支持下游使用
- slot 数量受数据库配置限制, 无法动态调整
- 遗忘的 slot 会持续膨胀, 占用数据库存储资源
- slot 不支持过滤, 繁忙的数据库上数据量巨大, 即使在下游进行逻辑过滤, 其占用的带宽也难以避免
- 只可以在 主节点 使用, 在发生主从切换时, 机制会失效
- 不支持 DDL(结构变更, 比如表字段增加) 事件捕获, 只支持 DML(数据增删改) 事件捕获
- 不支持无唯一标记的 DML 事件捕获, 唯一标记可以是主键, 也可以是唯一索引
- 需要源库日志开启到 logic 级别, 增大了存储占用
- 不支持回溯获取历史数据变更, 只能获取到开启 slot 之后的变更
即便问题如此之多, 但是由于其使用的便捷性, 对其进行二次开发的成本很低, 依然成为各大数据集成组件里的首选方案, 这其中包括 debezium, flink-cdc, datax, flinkx 等等
手动管理日志解析
为了解决这些问题, 我们需要能直接解析 WAL 的插件方案
Oracle 数据库有一个叫做 Logminer 的插件, 可以方便对数据库 Redo Log 进行逻辑解析, 对 PostgreSQL 也有一个类似的插件叫 Walminer, 项目地址在: movead/WalMiner
在使用上, 与手动管理的 Oracle Logminer 基本一致, 其具体的使用命令如下:
## 列出 WAL 文件
select walminer_wal_list()
## 添加 WAL 文件或者 WAL 文件目录到待解析
select walminer_wal_add('/opt/test/wal')
## 解析日志
select walminer_all()
## 解析指定时间的 WAL 日志
select walminer_by_time(starttime, endtime)
## 解析指定 lsn 范围的 WAL 日志
select walminer_by_lsn(startlsn, endlsn)
## 查看解析结果
select * from walminer_contents
## 销毁解析任务
select walminer_stop()与基于复制槽的解码方案相比, Walminer 有自己的一些优势, 包括:
- 可以解析任意时间段的日志, 不需要提前开启任务
- 不需要将日志级别设置为 logic, 节省空间
- 支持 DML/DDL 事件解析
- 可以对结果表创建索引, 进行基于时间和断点的范围查询
他的劣势有:
- 结果表占用了数据库存储资源
- 日志解析占用了数据库计算资源
- 事件查询占用了数据库计算与带宽资源
- 不支持并发解析, 用户需要自己进行细粒度数据管理
相比复制槽解码插件, Walminer 从根本上解决了很多问题, 并引导我们思考这个方案的通用扩展性
原生裸日志解析
pgwal_dump 是 PostgreSQL 官方提供的 WAL 解析工具, 与 Walminer 相比, 其优势在于不需要安装到数据库中, 且解析不占用数据库资源, 解析后的内容可以输出到文件中供下游消费, 官方提供, 有较好的维护性, 其劣势在于无法使用数据库驱动进行任务管理, 需要额外安装通信 agent 进行任务管理, 且其输出结果无法直接 SQL 查询, 需要自行组织结果数据
除此之外, 其核心功能与 Walminer 基本相同, 可作为备用方案使用
WAL 日志方案的反思
对数据库的设计者来说, 提供数据库事件的回放能力往往基于两个目的:
- 故障恢复
- 主从同步
故障恢复的场景使用低频, 数据实时性要求低, 多手动操作, 对集成性要求不高, pgwal_dump 是一个典型的例子, 对这个工具的集成使用需要额外开发 agent 进行任务管理, 增加了使用成本
主从同步有一个典型的特点是从的数量往往不是很多, 因此所有基于此假设的方案在遇到较多的消费下游时, 会遇到比较严重的性能问题, slot 的方案即是如此, 除此之外, 主从同步往往需要全量数据保持一致, 因此往往不会针对库, 表, 甚至更细致的查询条件进行特异性解析优化, 在使用时往往带来较大的资源浪费
实时数据服务平台的需求打破了上述两个目的假设, 其场景既需要非常高的实时性, 又需要非常好的集成性, 同时对数据的消费数量与业务相关, 繁忙的数据库其消费场景会达到数十, 甚至数百个, 这些数据消费任务对数据的要求各不相同, 具备精细的过滤条件
在实时任务的开发过程中, 将时间回退到某个时间点进行回放是非常常见的调试需求, 已有的方案要么无法实现, 要么以占用较多的数据库资源进行折衷, 在技术上不优雅
针对各种数据库, 以上的困难都不止一次出现在我们面前, 客户在进行任务开发时, 需要小心翼翼设计任务过程, 避免对生产库造成影响, 对用户造成了较大的心智负担
痛定思痛, 作为专注在实时数据开发的产品型公司, 这个问题被客户反复提起, 摆在研发团队面前, 经过多次思考与尝试, 我们使用了自研缓存中间件, 提出了自己的解决方案
TAP-CDC-CACHE
在软件开发领域有一个名言, "All problems in computer science can be solved by another level of indirection", 这个场景也不例外
为了解决这个问题, TAPDATA 对于各种来源的数据增量事件的写入和消费需求, 针对性开发了一个高速大容量的缓存层, 其具备以下基本特性:
- 分布式高可用: 基于 RAFT 的多副本同步机制, 可防止单点故障
- 无外部服务依赖: 部署便捷, 管理方便
- 丰富的存储端数据过滤: 支持多字段, 多级字段, 字段等于, 字段范围, IN Array, 多条件逻辑运算等过滤条件, 运行在服务端, 极大节省带宽和消费端算力
- 支持多生产者/消费者, 支持自动推进, ACK 推进等消费方式
- 高性能: 极致数据吞吐能力, 单节点可满足每秒数百万的事件读写能力
- 大容量: 基于普通磁盘读写能力进行设计, 支持数据压缩, 满足常见业务场景极长时间的历史增量事件存储需求
- 严格顺序保证: 针对同一个数据源的数据, 不使用分区存储, 保证数据的严格有序性, 虽然降低了部分处理性能, 但是对流计算场景来讲, 数据的准确性比性能更为重要
并针对 CDC 场景进行额外优化, 包括:
- 增量事件自动解析: 支持常见数据库事务日志格式, 原生写入, 自动解析并规整输出
- 事件补全: 基于全量数据 1:1 拷贝, 支持将部分不完整的增量事件, 比如没有开启 Full 的 Oracle Redo Log, MongoDB Oplog 缺少前值与完整后值的情况, 对数据进行自动补全, 方便下游进行各种计算处理
- 事件共享: 对一个确定的数据源实例, 只需要对源库进行一份增量事件读取, 下游所有消费者从缓存层获取数据, 避免对源库造成较大压力
- 支持时间和断点位置的双向转换: 通过大范围二级索引查找与精确查找遍历相结合的方式, 转换速度快, 资源消耗少
- 统一数据标准检测: 对 DML/DDL 描述抽象出一套异构数据库通用的描述, 包括统一可扩展的数据类型, 事件标准描述等规则, 并支持在缓存层进行检测, 保证进入下游的数据符合质量要求
- 支持指定范围的 全量+增量 自动合并结果返回, 在批流一体的精确一次数据输出场景, 可以做到对源库的无锁并发数据读取, 并极大简化了连接器的开发过程
这个中间件工作在数据采集层与计算层的中间位置, 屏蔽了数据库增量标准的差异性, 解决了之前方案遇到的各种问题, 为后续对数据的使用提供了足够的功能与性能空间, 为产品提供了独有的竞争力
几个常见的工作模式流程图如下:
典型工作模式
以 Oracle 为例, 开发者只需要将单并发实例级别无过滤的 Logminer Redolog 解析结果发送到缓存层, 后续的标准化, 有序性保证, 过滤器均可自动完成, 如下图所示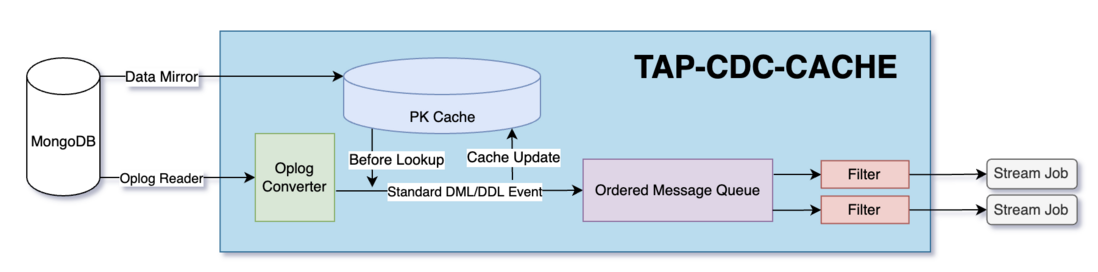
非标准日志补齐
以 MongoDB 为例, MongoDB 的 Update 需要开启反查才能获取完整前值, Delete 操作不支持变更前值获取, 在流计算场景, 只有一个变更主键是不满足后续数据需求的, 比如对双流 JOIN 场景, JOIN 键不为主键时, 一条记录的删除除了需要知晓主键之外, 他的关联键和具体变更的数据也非常重要
针对这个场景, TAP-CDC-CACHE 的工作模式如下:
后言
提到数据流存储, 会有一些同学有为什么不使用 kafka, pulsar, 或者 pravega 这种产品的疑问, 处于解决问题成本最低的考虑, 一开始确实有考虑使用流存储, 与 Stream API 去开发一些处理算子来实现需求, 但是流存储这些开发接口, 本质上是对流做逐条变换, 一些核心的需求, 比如:
- 对不完整事件进行补全
- 合并增量全量数据
- 时间/断点相互转换等问题
这几个问题的技术抽象使用逐条读取流已经很勉强, 实现出来的效果并不好, 我们不得不对一些特定的流做一些二级索引的维护, 这本身又需要单独一个组件来做, 这引入了一些额外的复杂性, 再考虑到:
- 过滤器是非常消耗带宽的操作, 而常见的流存储产品不支持在 broker 进行计算
- 针对场景需求, 我们需要开发较多的 Stream 中间件
我们认识到自己的需求可以被更优雅和专业地解决, 于是有了这个产品的雏形,本质上来讲, TAP-CDC-CACHE 是一个特定场景下优化的数据库。
关于 Tapdata:
Tapdata 是一款基于数据即服务(DaaS)架构理念,面向 OLTP 业务或场景的实时数据服务平台,具备异构数据实时同步、批流一体数据融合、自助式 API 发布等功能。Tapdata 目前已支持近百个数据源和类型,包括市场主流的数据库,API,队列,物联网等,所有操作均是低代码、可视化方式,无需专业的编程能力就可完成数据实时同步、数据映射与合并、数据建模、数据服务 API 开发,数据实时入湖入仓等。申请试用:https://tapdata.net/tapdata-e...
本文作者:Tapdata 技术合伙人肖贝贝,原文地址:https://tapdata.net/TAP-CDC-C...






