引言
Selenium 是一个用于测试网页和网络应用的框架。它兼容多种编程语言,并且除了 Chrome 浏览器之外,还能得到其他多种浏览器的支持。Selenium 提供了应用程序编程接口(API),以便与你的浏览器驱动程序进行交互。
实战
现在,我们通过一个简单的网页数据抓取实例来深入了解这个框架。我们的目标是利用 Selenium 抓取一个内容会动态变化的网站,以沃尔玛网站为例。首先,我们需要安装 Selenium。在你的命令行终端中输入以下指令来完成安装。
pip install selenium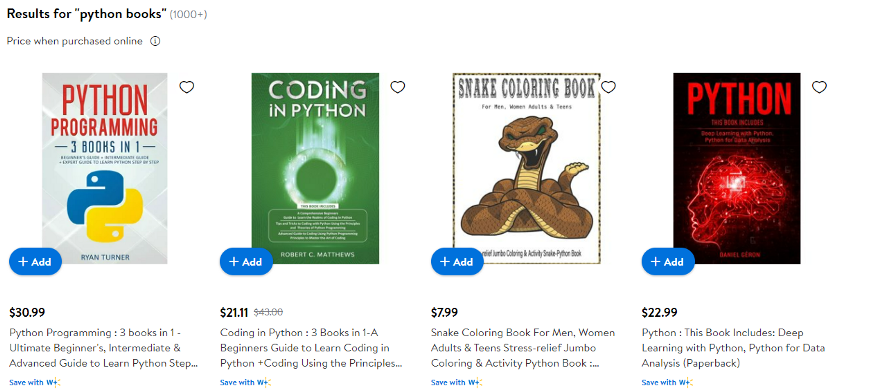
我们的工作是打开这个网站并提取 HTML 代码并打印它。因此,第一步是导入文件中的所有库。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options然后我们将设置selenium提供的选项。我们将设置页面大小,并以无头格式运行它。
以无头形式运行它的原因是为了避免额外使用 GUI 资源。即使在外部服务器上的生产中使用 selenium,也建议您以无头模式使用它,以避免浪费 CPU 资源。这最终会增加您的成本,因为您需要添加更多服务器来实现负载平衡。
options = Options()
options.headless = True
options.add_argument(“ — window-size=1920,1200”)现在,我们将声明我们的驱动程序,您必须使用安装 chromium 驱动程序的路径。
PATH_TO_DRIVER='YOUR_PATH_TO_CHROIUM_DRIVER'
driver = webdriver.Chrome(options=options, executable_path=PATH_TO_DRIVER)
url="https://www.walmart.com/search/?query=python%20books"我们还声明了我们的目标 URL。现在,我们只需要使用它的 .get() 方法来打开驱动程序。
driver.get(url)
time.sleep(4)
print(driver.page_source)我在打印 HTML 之前使用 sleep 方法完全加载网站。我只是想确保在打印之前网站已完全加载。
在打印时,我们使用了 selenium 的 page_source 属性。这将为我们提供当前页面的来源。这就是我们打印结果时得到的结果。

我们已经获取了必要的 HTML 页面内容。和亚马逊类似,沃尔玛也实施了反机器人检测机制,但在进行网页抓取时,还需要进行 JavaScript 的渲染处理。
某些网站之所以需要 JavaScript 渲染,是因为它们需要加载所有的 JavaScript 钩子。当这些钩子全部加载完成后,我们可以通过在浏览器中完全加载页面后提取页面源代码,一次性完成数据抓取。
有些网站为了完整加载需要进行大量的 AJAX 请求。因此,我们通常会采用 JavaScript 渲染的方式来替代传统的 GET HTTP 请求进行抓取。如果你想知道一个网站是否需要 JavaScript 渲染,可以通过检查网站的网络标签来确定。
此外,JavaScript 渲染还能提供一些可能对你将来有用的属性,例如:
driver.title:可以用来获取页面的标题。driver.orientation:可以告诉你设备相对于重力的方向。
使用 Selenium 的好处:
- 它支持多种编程语言,使用非常灵活。
- 可以在测试或生产的早期阶段发现潜在的错误。
- 拥有活跃的社区支持。
- 支持多种浏览器,如 Chrome、Mozilla 等。
- 在进行数据抓取时非常方便。
使用 Selenium 的不足:
- Selenium 不支持图像比较功能。
- 使用起来比较耗时。
- 对于初学者来说,搭建测试环境可能稍显复杂。
本文由mdnice多平台发布