近年来,多模态大模型存在的“幻觉”问题一直困扰着科研界。是否还在尝试通过指令微调来解决这个问题?比如下图模型识别图像错误。

现如今,中科大近日发表的一项研究提出了一种全新的方法,以应对这一难题。该方法被命名为“啄木鸟”(Woodpecker)。
“啄木鸟”技术是一个免重训、即插即用的通用架构。方法的核心思想在于,直接从模型给出的错误文本开始,首先“倒推”找出可能产生“幻觉”的部分。随后,该方法会与图像数据对比,从而确定事实并完成修正。
这种方法可以比作是“森林中的医生”啄木鸟,它会寻找树上的虫洞并吃掉里面的虫子。同样,“啄木鸟”技术能够检测并纠正模型的“幻觉”。这种方法将MiniGPT-4的准确性从54.67%提高到了85.33%。mPLUG Ow的准确性从62%提升至86.33%。
如图所示,“啄木鸟”技术在处理难以检测的小对象和复杂计数场景上表现出色。

然而,它是如何进行具体的检测和诊断的?
啄木鸟法”如何治疗多模态LLM模型的幻觉问题?
目前,业内通常采用特定数据对大模型进行指令微调。模型倾向于给出肯定答案,如基于图像的问题“头发是什么颜色”,模型可能默认回答“黑”。为纠正此问题,研究者会为模型提供负样本数据。以这种方式就能解决它“无中生有”的幻觉。
除此之外,也有的会进行架构调整,这两种方式都是重新训练一个新的模型
而“啄木鸟”框架为业界提供了一个全新的解决方案。这个方法分为五个步骤:

1、关键概念提取:
识别模型答案中的主要对象,即最有可能产生“幻觉”的元素。
如描述图中存在自行车、垃圾桶和人等关键概念。

2、问题构造:
围绕获取的关键概念,提出一系列问题来检验“幻觉”。
分为对象层面和属性层面的问题,如询问“图中有几辆自行车?”或“垃圾桶位于什么位置?”。
在这种情况下,由于属性问题的依赖性上下文较强,作者还提供了一些带有上下文的例子,以引导模型,使得提出的问题更具意义。
3、视觉验证:
利用专家模型回答上述问题,为后续校正提供依据。
关于对象问题,使用GroundingDINO进行对象检测,确定关键目标的存在性和数量。
对属性问题,采用BLIP-2模型,由于传统VQA模型输出答案长度有限,减少“幻觉”问题。
4、视觉断言生成:
基于前两步的问题与视觉信息,合成结构化的“视觉断言”。

5、“幻觉”纠正:
根据上步的视觉断言比对模型原始输出,生成新的答案。
具体来说就是使用GPT-3.5-turbo进行关键概念提取、提问和纠正。
为确保纠正效果,研究者还采用了两种策略:
(1)将简短的“是”或“否”回答与“啄木鸟”给出的答案组合,避免模型仅给出简化答案。
(2)在校正中,将原始问题添加到LLM,使其更好地理解文本和任务要求。
新方法“啄木鸟法”能降低30%的幻觉
整个方法看起来很简单,那到底是什么效果呢?
研究者在POPE、MME和LLaVA-QA90三个数据集上对此法进行了全面的定量和定性分析。作为比较的基线模型,他们选择了四个当前主流的多模态大模型:MiniGPT-4、mPLUG Owl、LLaVA和Otter。
**
可以看到,“啄木鸟法”为多数模型带来了显著的性能提升,并大大减少了模型仅回答“yes”的频率。**特别是在随机设置中,此方法使MiniGPT-4和mPLUG-Owl的准确率分别提高了30.66%和24.33%。

进一步,在MME数据集上,“啄木鸟法”有效地减少了模型在对象和属性层面上的“幻觉”。例如,LLaVA模型在颜色属性的得分从78.33分提升到了155分。然而,在位置属性上的提升较为有限,可能的原因包括VQA模型BLIP-2在位置推断能力上的局限性。
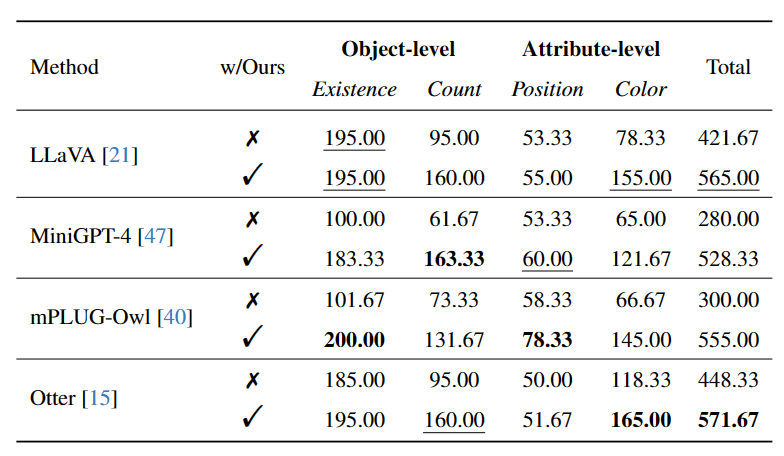
为了更为客观地评估修正效果,研究者采用了开放评估的方法。通过使用OpenAI最近发布的视觉接口,研究者利用GPT-4V直接为修正前后的图片描述进行评分,主要评价标准包括:
准确度:描述内容与实际图片内容的符合程度。
细节程度:描述的细节丰富度。
实验结果如下表所示(满分为10):

实验结果显示,“啄木鸟法”修正后的图片描述准确性得到了显著提升,证明该框架能有效地修正幻觉问题。同时,该方法也增强了描述的细节丰富度,为读者提供了更为具体的位置信息。
GPT-4V辅助的评测样例如下图所示: