
之前在git上下载的voltdb,以及在官网下载的社区版voltdb均不支持持久性事务,和扩展集群,今天下载了企业试用版voltdb,安装过程不再赘述,记录一下我的使用过程
持久性测试
以前的 voltadmin shutdown;之后重新启动voltdb后,仍然不能恢复数据,即使使用recover命令恢复后,也不能再现之前的数据,但是用了企业版的之后,shutdown后重新启动,则会加载之前生成的snapshot,恢复文件
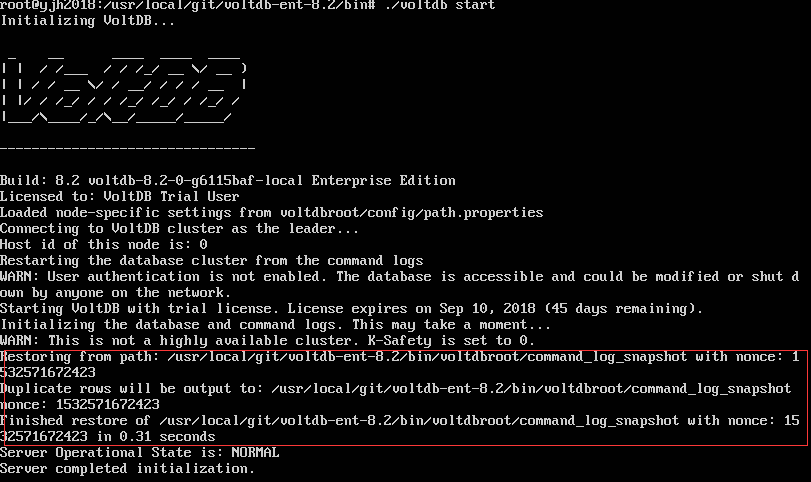
如图所示,会从磁盘中读入snapshot,之前的命令也可以重现,当然,数据库里的内容保存完好
这里列出部分数据
事务测试
voltdb为了避免时间的开销,避免了锁的使用,也就是说无法使用mysql的事务语句

触发器测试
也无法使用触发器

搭建集群
参考官方文档,搭建集群
初始化根目录使用 --config 指定配置文件(记得备份一份),所有的节点必须使用相同的配置文件
voltdb init -D ~/mydb --config=myconfig.xml
启动一个五节点数据库集群,指定voltsvr1作为主机节点。确保运行该命令的节点数与--count 参数中指定的节点数相匹配。
voltdb start -c 5 -H voltsvr1
执行此语句后,voltdb会修改config目录下的cluster.properties文件,hostcount变成5

以下命令(在所有三个服务器上发出)启动三节点集群:
voltdb start --host = svrA,svrB,svrC
在群集上启动VoltDB数据库时,VoltDB服务器进程将执行以下操作:
如果要在选择作为主机节点的节点上启动数据库进程,它将等待来自其余节点的初始化消息。主机是从命令行上的主机列表中选择的,并通过管理群集启动过程在启动期间扮演特殊角色。重要的是,群集中的所有节点都可以解析您指定的主机节点的主机名或IP地址。
如果要在非主机节点上启动数据库,它会向主机发送初始化消息,指示它已准备就绪。在连接了正确数量的节点(在命令行中指定)之前,数据库无法运行。
一旦所有节点都发送了初始化消息,主机就会向其他节点发送一条消息,表明集群已完成。一旦启动过程完成,主机的角色就结束了,它就像集群中的每个其他节点一样成为对等体。它不再执行任何特殊功能。











