
Jigsaw pre-training以拼图的方式从检测数据集中生成用于主干网络预训练的数据集,而不需要额外的预训练数据集,如ImageNet。另外为了让网络更好的适应拼图数据,论文提出ERF-adaptive密集分类方法,能够很好地扩大预训练主干网络的有效感受域。整体而言,Jigsaw pre-training方便且高效,性能比使用ImageNet预训练模型效果要好。
来源:晓飞的算法工程笔记 公众号
论文: Cheaper Pre-training Lunch: An Efficient Paradigm for Object Detection

Introduction
目标检测网络一般都使用如ImageNet的大型分类数据集进行主干网络的预训练,借助大规模数据集上学习到的特征表达,能帮助检测算法更快地收敛,但这种方法带来的额外数据集需求和计算消耗是不可忽视的。尽管有一些方法通过改善权值初始化来优化直接训练检测网络的效果,但这种方法通常收敛都比较慢,需要更多的训练时间,主要由于主干网络在直接训练时会面对大量的无效信息,过多的背景会带来冗余的计算消耗,造成收敛过慢且效果不好。
基于上面的分析,论文提出了很“实惠”的预训练方法Jigsaw pre-training,从检测数据集中提取出目标样本和背景样本,根据目标的长宽比以拼图的方式将其组合成一个训练样本进行模型预训练。为了提高预训练网络的有效感受域,论文设计了ERF-adaptive密集分类策略,根据有效感受域(ERF)来给每个特征点指定平滑标签(soft label)。论文的贡献如下:
- 提出高效且通用的预训练范式,仅需检测数据集,消除了额外的预训练数据需求。
- 设计了样本提取规则,以拼图策略和ERF-adaptive密集分类来高效地进行主干网络的预训练,提高了训练效率和最终性能。
- 在不同的检测框架验证了Jigsaw pre-training的有效性,展示其通用型。
Methodology
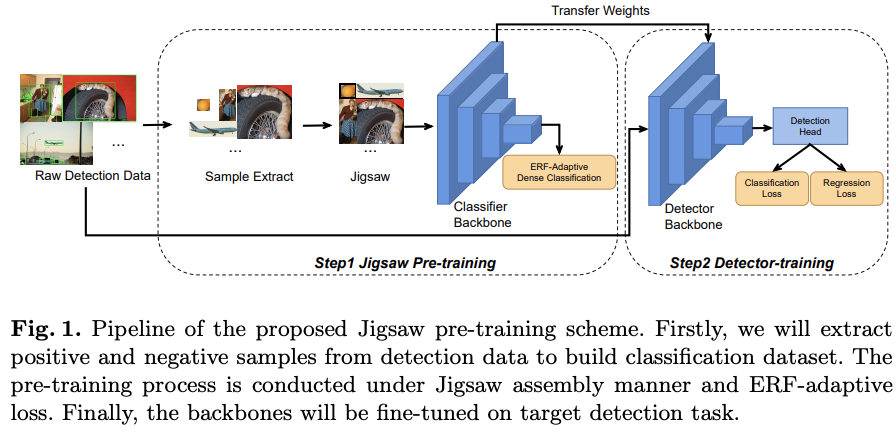
Jigsaw pre-training方法如图1所示,能够用于各种目标检测框架中。给定检测数据集$\mathcal{D}$,从中提取正负目标保存为分类数据集,这些目标以拼图的形式组合并用于检测器主干网络的预训练,训练使用论文提出的ERF-adaptive损失。在完成预训练后,以fine-tuned的方式在$\mathcal{D}$上训练目标检测模型。
Sample Selection
在目标检测模型训练中,正负样本平衡是十分重要的。为了高效的预训练,论文小心地将原图提取的目标划分为正负样本,正负样本的提取都有其对应的规则。
Positive samples
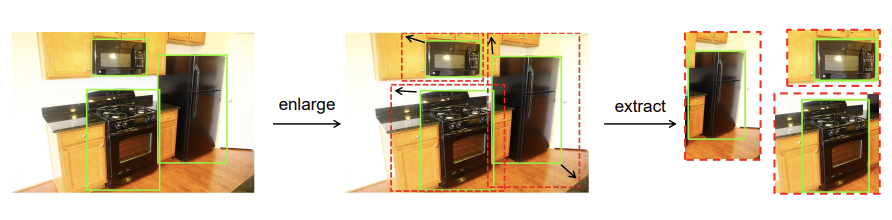
根据GT bbox从原图提取区域,考虑到上下文信息对特征表达的学习有帮助,随机扩大bbox大小来包含更多的上下文信息。具体做法为移动bbox的左上角和右下角,最大可扩展为原边长的两倍,若bbox超过原图边界则进行裁剪,如上图所示。
Negative samples
为了让预训练模型更适应检测场景,从背景区域提取一些负样本。首先随机生成一些候选区域,然后获取$IoU(pos, neg)=0$的所有负样本,这样正负样本就是互斥的。在论文的实验中,正负样本的比例为10:1。
Jigsaw Assembly

有很多方法能够处理样本进行预训练,比如warping以及padding,但warping会破坏原本的上下文信息和形状,而padding会加入无意义的填充像素,带来额外的计算时间和资源消耗。为了更有效地进行预训练,论文基于目标的尺寸和长宽比,采用拼图的方式处理样本,每次拼四个目标。在获得所有样本后,根据长宽比将他们分为3组:
- Group S(square):长宽比在0.5到1.5直接
- Group T(tall):长宽比小于0.5
- Group W(wide):长宽比大于1.5
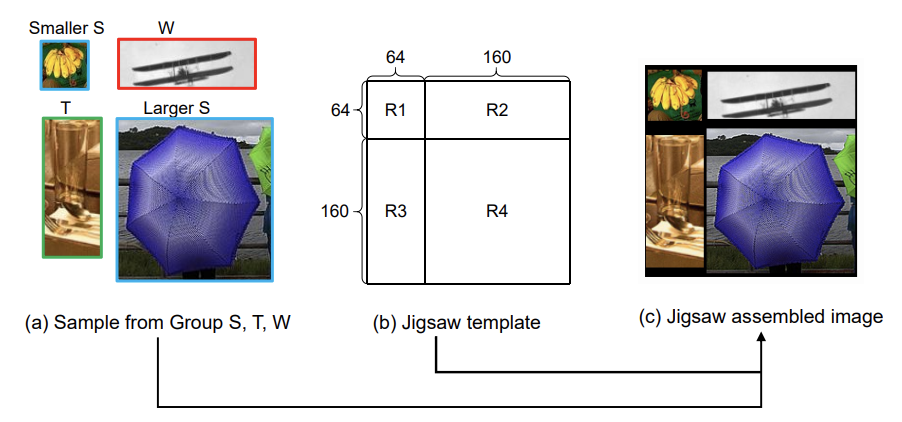
如上图所示,每次拼图随机选择两个S样本、1个T样本和1个W样本填充到预设的区域中。较小的S样本放置于左上角,较大的S样本放置于右下角,而T样本和W样本分别放置于左下角和右上角。若样本大小不符合预设的拼图区域大小不一致,根据其大小选择填充或随机裁剪,根据实验结果,不会对目标进行缩放和warping。
ERF-adaptive Dense Classification
由于拼图样本可能包含多个类别的目标,因此需要特殊的训练方法,论文先介绍了两种用于对比的策略:
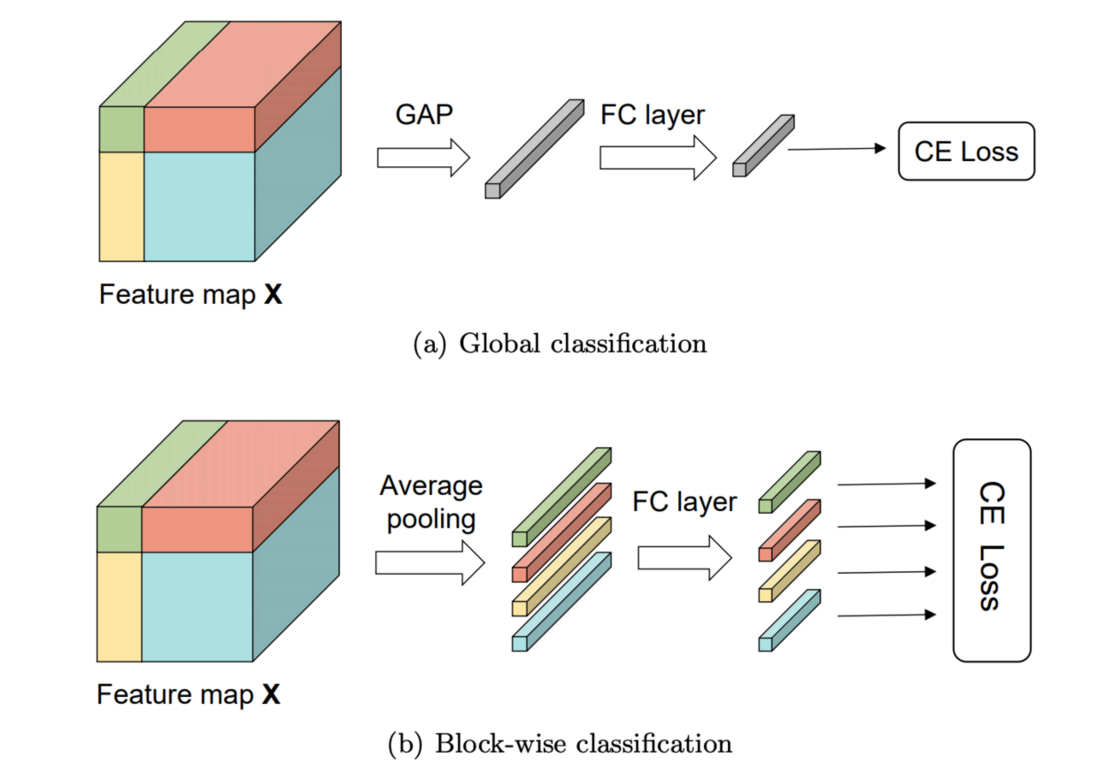
- Global classification,给整张图片一个全局的标签,该标签为4个目标标签的区域大小加权和,有点类似CutMix数据增强方法,最后使用全局池化,进行交叉熵损失更新。
- Block-wise classification,保留每个目标的标签,在池化的时候对每个区域对应的特征进行独立的池化和预测,最后也单独地进行交叉熵损失计算。
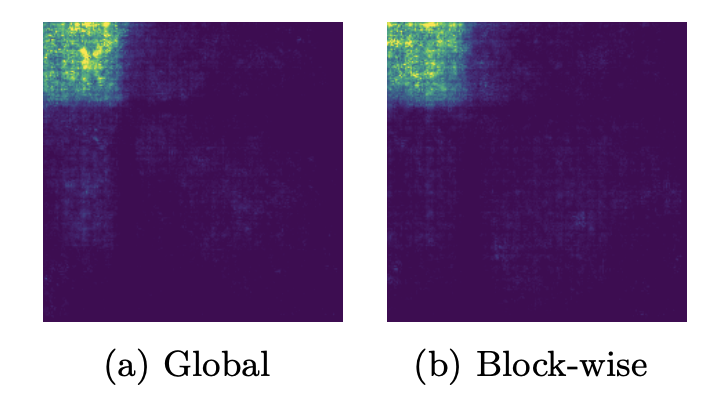
但论文通过可视化左上角区域的有效感受域发现,上面两种方法的左上角区域的有效感受域都集中在了对应小S-sample区域,这种局限的有效感受域可能会降低深度模型的性能。
为了尽量考虑每个像素,论文提出ERF-adaptive密集分类策略,对特征图$X$的每个位置进行分类,而每个位置的soft label基于其对应的有效感受域计算。定义每个区域$R_i$的原标签$y_i$,对于特征图$X$的每个位置$(j,k)$,soft label $\tilde{y}^{j,k}$为4个标签的加权和:
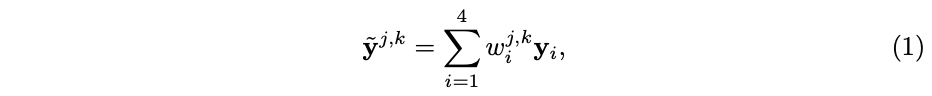
权重$w^{j,k}_i$取决于有效感受域,对于位置$(j,k)$,其对应的输入空间的有效感受域为$G^{j,k}\in \mathbb{R}^{H\times W}$后,权重$w^{j,k}_i$为有效感受域在区域$i$内的权值之和与整体有效感受域权值之和的比值。另外,如果位置$(j,k)$在区域$i$内,设定$w^{j,k}_i$的最小阈值$\tau$,保证$y_i$主导soft label。整体的公式可表示为:
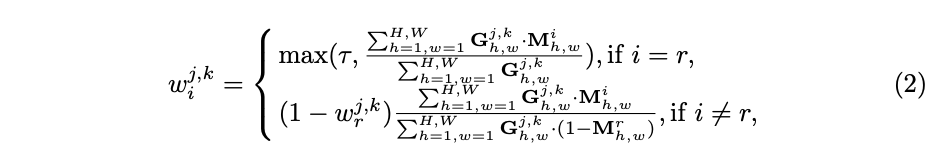
$M^i \in \{ 0,1\}^{H\times W}$为二值掩膜,用来标记ERF在区域$i$中部分。
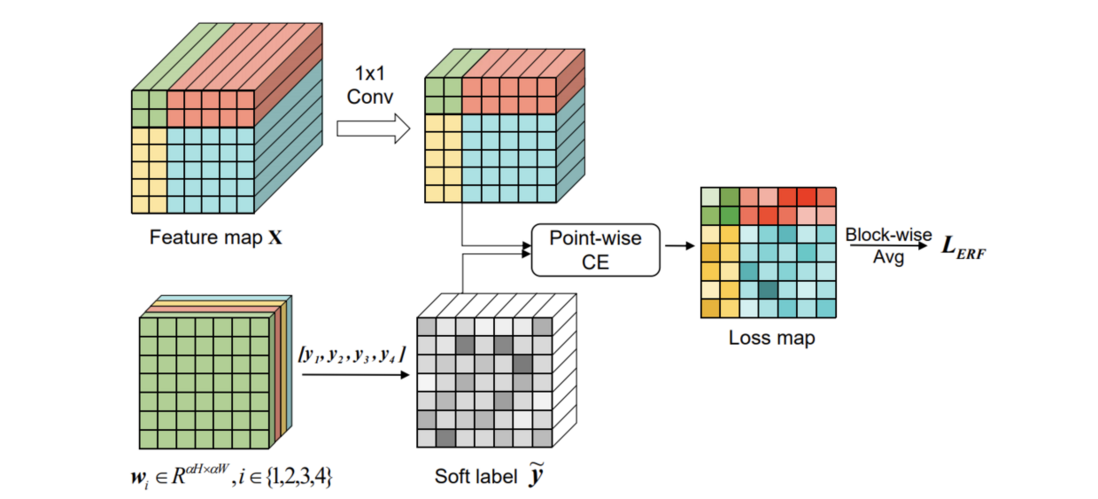
在得到位置$(j,k)$的权重$\{ w^{j,k}_i \}$后,计算每个位置的soft label。在对特征$x^{j,k}$进行稠密分类时,将最后的全连接层替换为$1\times 1$卷积进行预测,最后对预测特征图的每个位置与soft label进行交叉熵损失。为了公平起见,对loss map进行block-wise池化。需要注意的是,权重在每5k次迭代更新一次,而不是每次迭代都更新。

同样是左上角区域对应的有效感受域的可视化,ERF-adaptive有更大的有效感受域。
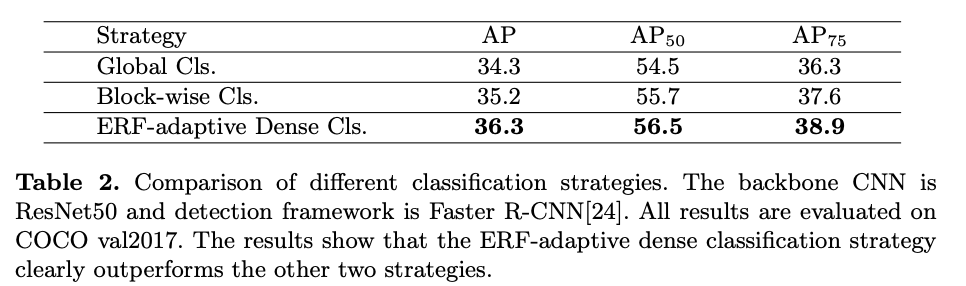
论文也对3种策略的效果进行了对比。
Experiments
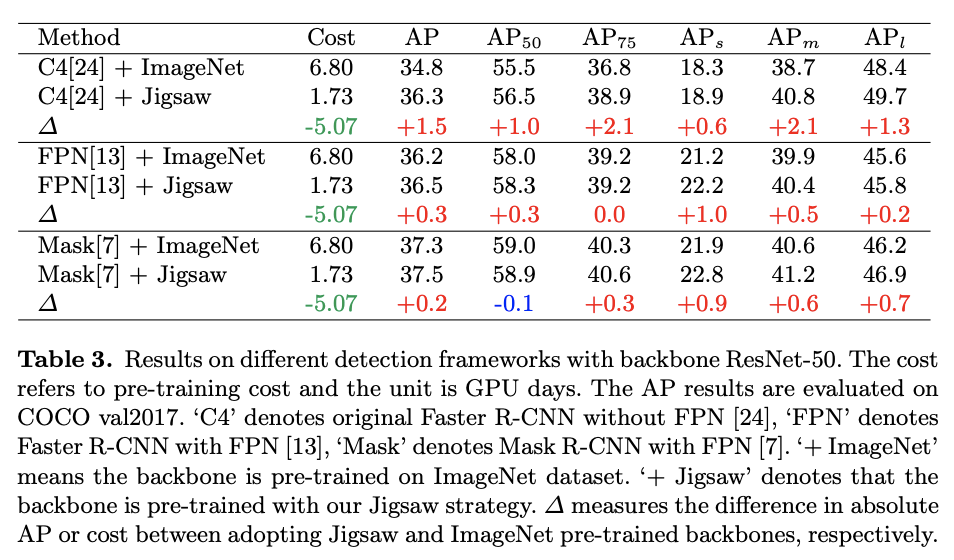
与ImageNet预训练方法对比,Cost为耗时,单位为GPU day。
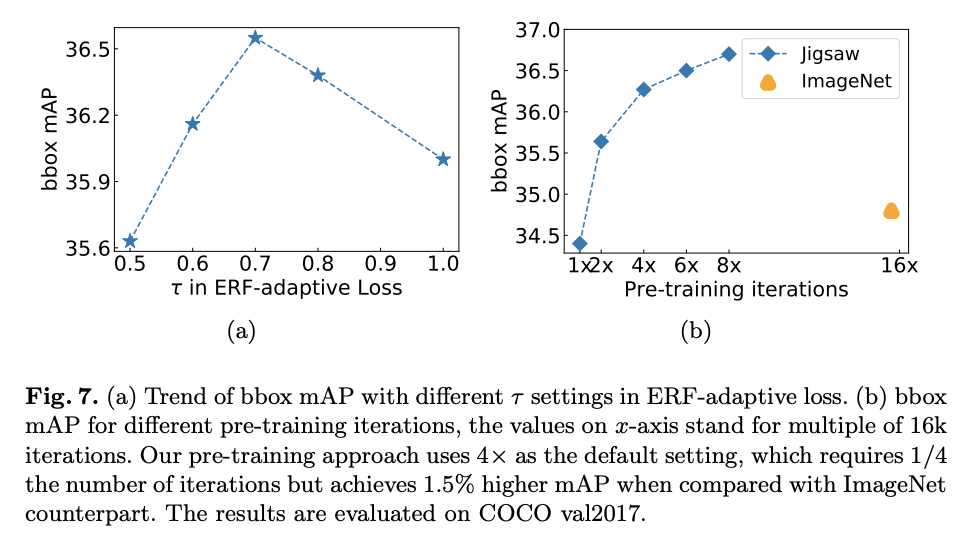
不同训练参数的性能差异。
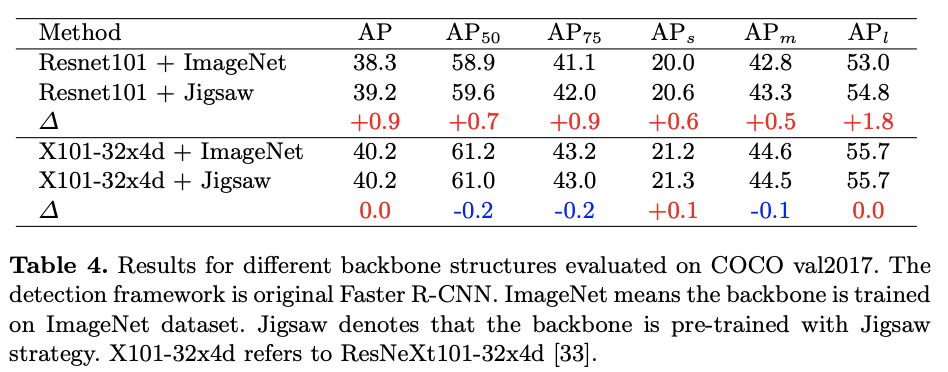
不同主干网络上的效果对比。

在多种检测框架和策略上进行对比。
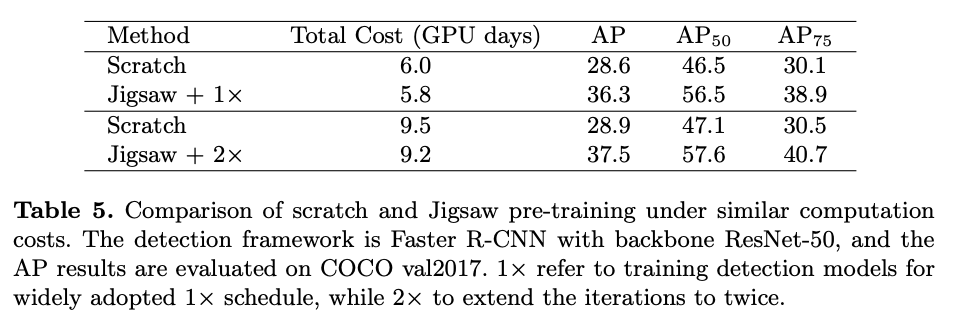
与直接训练方法的对比。
Conclustion
论文提出了一种高效的预训练方法Jigsaw pre-training,该方法以拼图的方式从检测数据集中生成用于主干网络预训练的数据集,而不需要额外的预训练数据集,如ImageNet。另外为了让网络更好的适应拼图数据,论文提出ERF-adaptive密集分类方法,能够很好地扩大预训练主干网络的有效感受域。整体而言,Jigsaw pre-training方便且高效,性能比使用ImageNet预训练模型效果要好。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】














