
本文分享自天翼云开发者社区《VictoriaMetrics常见性能问题排查》,作者:YT20
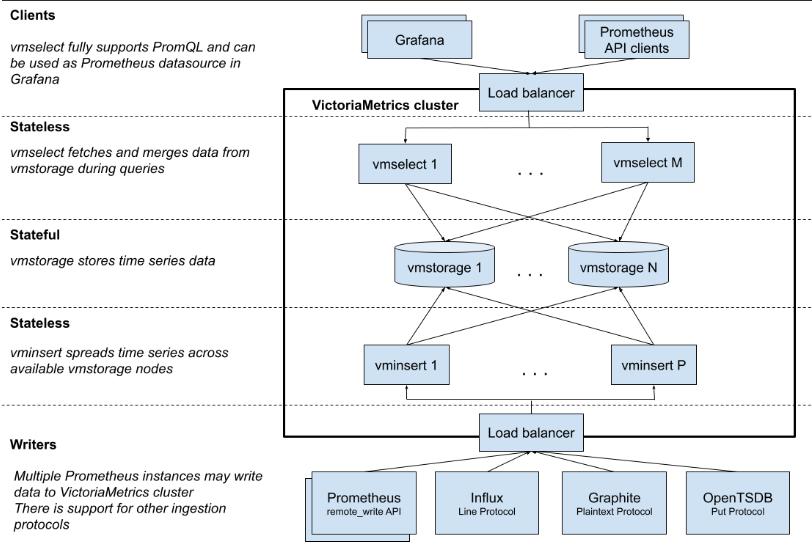
集群架构 VM集群由以下子模块组成 vmstorage: 存储原始数据,并根据指定时间范围和标签过滤条件等返回查询数据集 vminsert: 接收数据写入,并根据指标名和标签按一致性hash分发至集群中vmstorage节点 vmselect:执行查询请求,从数据所在的vmstorage节点获取数据 每个模块可以独立扩缩容。其中vmstorage各节点之间不互相通信,属于share nothing架构。如此可以增加集群可用性,也简化了集群维护、扩容。
慢摄入 VM慢摄入的常见原因如下:
- 内存不足(活跃时序数据缓存) vmstorage在内存中维护一个缓存,用于快速检索每个传入指标的内部序列ID。此缓存名为storage/tsid。VM会根据运行vmstorage的主机上的可用内存自动确定此缓存大小。如果缓存大小不足以容纳活跃时序数据的所有条目,则VM会从磁盘加载并重建缺失的条目并将其放入缓存中。这需要消耗额外的CPU时间和磁盘IO。
VM官方的Grafana仪表板包含了慢摄入(slow inserts)图表,其中显示了数据摄入过程中的storage/tsid缓存未命中率。如果图表显示慢摄入比例高于5%持续10分钟以上,则很可能当前的活跃时序数据与storage/tsid缓存大小不匹配了。
针对这个问题,有以下方法可以处理: 1)增加运行VM的主机上的可用内存,直到慢摄入比例低于5%:要么增加每个现有vmstorage节点的可用内存,要么向集群中添加更多的vmstorage结点。 2)减少活动时序数据的数量。VM官方Grafana仪表板包含一个显示活动时序数量的图表。最近版本的VM提供了cardinality explorer,可以有助于确定和修复高cardinality的数据源。
高周转率(Churn Rate) 在VM指标中,Churn Rate即旧时序数据被新时序数据取代的速率。当VM发现新的时序样本时,它需要为其在内部索引(即indexdb)中注册,以便在后续的select查询中快速定位。在内部索引中注册新时序的过程,比已经注册过的时序添加新样本的过程慢一个数量级。因此VM在高周转率情况下的数据摄入速率会比预期要慢许多。 VM官方Grafana仪表盘提供了Churn Rate图表,显示了过去24小时内注册的新时序数据的平均数量。如果这个数字超过了活动时序的数量,那就需要排查并修复高周转率的来源。高周转率最常见的问题来源是取值经常变化的标签。生产上应尽量避免这样的标签。cardinality explorer可以帮助识别这样的标签。
资源不足 VM官方Grafana仪表板包含资源利用率图表,显示内存利用率、CPU利用率、磁盘IO利用率和可用磁盘控件。为确保VM有足够的空闲资源来合理处理工作负载潜在高峰,建议在生产上保留一定的空闲资源,比如50%空闲CPU、50%空闲内存、20%可用磁盘空间。 如果VM组件没有足够的空闲资源,就会导致在工作负载增长时其性能显著下降。例如: 1)如果CPU空闲率接近0,则VM摄入数据时会出现较大延迟 2)如果空闲内存接近0%,则运行VM组件的OS可能没有足够的内存用于page cache。VM依靠page cache对最近摄入的数据进行快速查询。如果OS没有足够的可用内存用于page cache,则需要从磁盘中重新读取请求的数据,显著增加磁盘IO,并降低查询和数据接收速度。 3)如果可用磁盘空间低于20%,则VM无法对写入数据执行后台合并。这导致磁盘上的数据文件数量增加,从而降低了数据接收和查询的速度。
网络延迟 运行集群版VM时,需要保证vminsert和vmstorage之间网络延时要足够低。vminsert负责将写入数据成批打包并串行传给vmstorage,即只有前一个数据包回复ack以后才会发下一个。如果vminsert和vmstorage网络延迟高(比如跨地区部署),则数据摄入速率必然受限。
VM官方Grafana仪表板包含了vminsert组件的connection saturation图表。如果这个图表达到100%(1秒内),则vminsert和vmstorage之间的网络延迟必然有问题。另一个导致这个指标100%的可能性是vmstorage资源不足了。
- 混合部署影响 生产上要确保VM组件运行在相对独立的环境中,起码要保证环境内没有其他资源消耗大户程序。如果与其他非常耗资源的程序混合部署,则很难仅通过VM官方Grafana仪表板发现,此时需要检查运行VM的实例的资源利用率。
慢查询
VM可通过-search.logSlowQueryDuration命令行标记设置慢查询时间阈值(默认5s),并提供了/api/v1/status/top_queries接口来给返回执行时间最长的查询请求。排查解决VM慢查询问题的常用方法有:
1)直接扩容:为VM添加更多的CPU和内存,因此可以更快地执行慢查询请求;如果使用集群版本的VM,那么将vmselect节点迁移到具有更多CPU和内存的机器有助于提高慢查询请求的速度。查询性能总是受到处理查询的一个vmselect的资源的限制。例如,如果vmselect上的2 vCPU不能足够快地处理查询,那么将vmselect迁移到具有4vCPU的机器应该会将繁重的查询性能提高2倍。如果VM的官方Grafana仪表板上的Concurrent select图上接近极限,那么更倾向于向集群中添加更多的vmselect节点。有时,添加更多的vmstorage节点也有助于提高慢查询请求的速度。
2)重写慢查询请求,使它们变得更快。但仅仅通过观察很难确定查询请求是否缓慢。VM提供了查询跟踪功能,可以帮助确定慢查询的来源。另请参阅本文,其中解释了如何确定和优化慢速查询。
在实践中,由于子查询的使用不当,会生成许多慢查询请求。如果不清楚子查询是如何工作的,建议避免子查询。在不知道的情况下创建子查询很容易。例如,rate(sum(some_metric))根据MetricsQL查询的隐式转换规则隐式转换为子查询rate ( sum ( default_rollup ( some_metric[1i] ) ) [1i:1i] )。此查询很可能不会返回预期的结果,应该改为使用sum(rate(some_metric))。




