
前言
现如今,分布式文件系统可谓是琳琅满目,多种多样,有hdfs,gfs,zfs,fastdfs,go-fastdfs等,怎么选择合适自己的分布式文件系统呢?在这篇文章中,我们不讲……额,我只想表达一下我在研究go-fastdfs过程中踩的坑。
go-fastdfs
首先,什么是go-fastdfs?是fastdfs的弟弟吗?是fastdfs的go语言实现吗?具体请参考go-fastdfs 其实我也是在调研这款产品,里面简约设计,便利的操作让我蠢蠢欲动想去试试,好不好用只有自己试过才知道对吧。在此之前,我本人是有过使用fastdfs的经验的,对此,简单说下两款产品的不同,更加纤细的描述请自行参考官方github。语言层面,fastdfs是采用C语言编写,而go-fastdfs是采用go语言编写,其次,fastdfs提供多个客户端,不过底层使用TCP进行通信,也正是如此,本人在做这块的时候,采用的是RPC的方式对fastdfs-java-client做了一层封装,官方提供的client内部也有不少的坑哦!惊不惊喜?意不意外?然后在业务层Servlet/Controller调用RPC的方式和fastdfs进行通信,从而实现文件上传等操作,对于文件的读取和下载,是结合ngx_fastdfs_module的Nginx模块,使用Nginx提供基于http的服务。go-fastdfs则可以直接提供http服务,包括上传,实际上go-fastdfs就是一个高性能的web服务器,从而上传文件的话更加便利了,也就是说,它并没有什么特定的客户端,只要支持http,都可以作为客户端的存在。
Tus协议
Tus又是什么鬼?其实就是一个断点续传的协议啦,这是一个比较轻量级的协议,具体可以参考tus官方网站。这个协议以前我也没听说过的,以前做断点续传都是自己实现,其实原理也不难的,就是前端上传的时候文件分块上传,上传结束后告诉后端,然后再合并文件块。如果中间暂停了,下次再传递的时候,将上一次中断的文件块进行丢弃,文件指针移动到上次传输中的文件块的起始位置,读取文件分块上传。有了tus之后,就不需要那么麻烦啦。
下面看一下tus的流程,图片来源segmentfault。
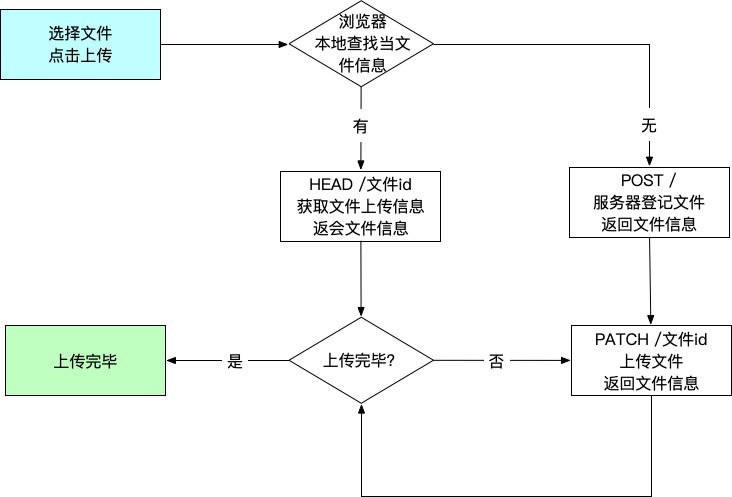
多的就不啰嗦啦,请参考官方网站哈。 言归正传,下面开始说一下我遇到的坑以及如何解决的。
踩坑之旅
踩坑之前准备工作
- 安装好go-fastdfs,最好安装在linux环境
- 检查下防火墙什么的
- 启动go-fastdfs的fileserver,并且修改生成的配置文件,默认情况下是在conf/cfg.json
- 这里用的是java,因此可以选择一个自己喜欢的IDE,我选IDEA,因为我喜欢!创建一个maven工程
- 这里使用到hutool,为什么不用别的工具类?因为我喜欢!版本最好选最新版吧。tus-java-client用的是0.4.1
坑一、301重定向问题
tus上传的时候,应该是要替换url的,先得到一个301的url然后替换,如果说错了,请指正。那么问题来了,启动程序之后,就一直301,根本没给我替换,是不是因为我是老实人就想欺负我?
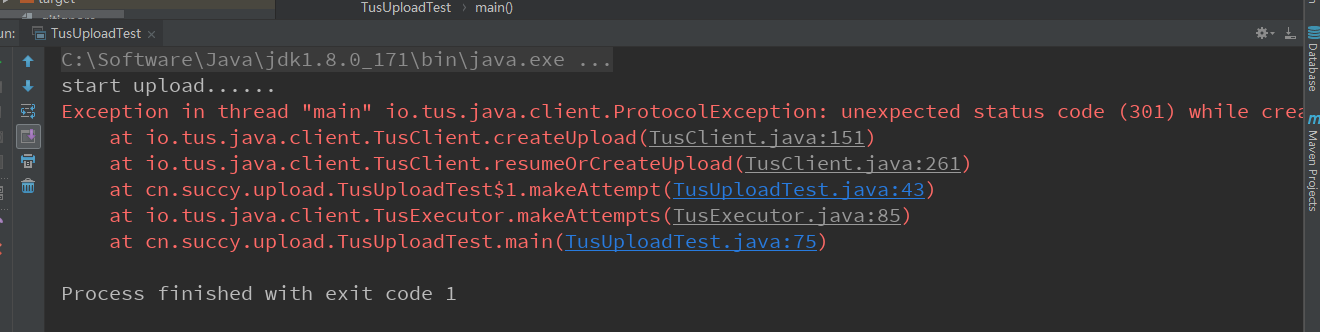
正在我百思不得其解的时候,调试了一波tus-java-client的源码,终于找到了答案。在TusClient.java里面,有隐藏的玄机,请看下面
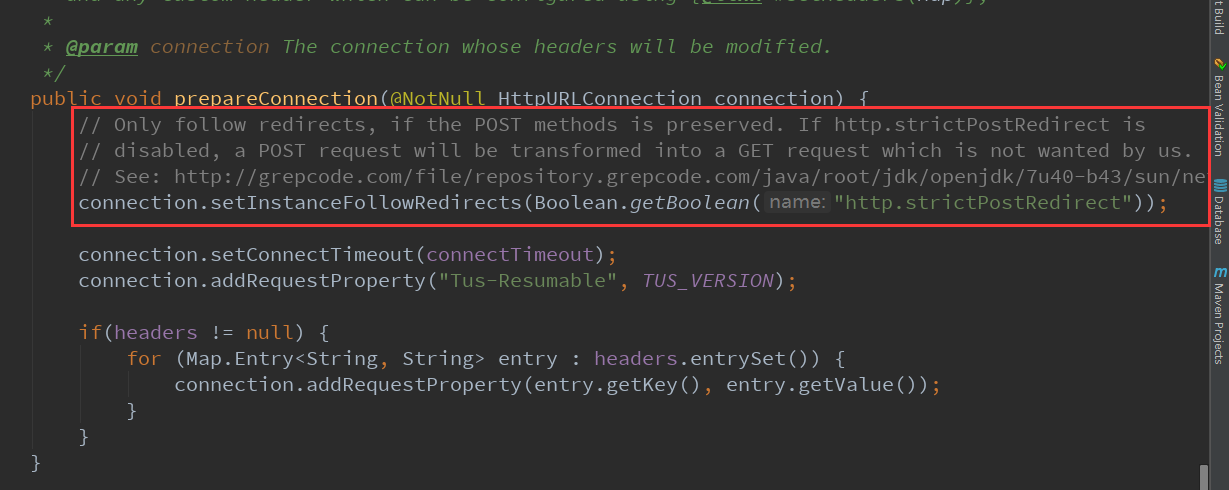
根据上面的图,在实例化TusClient之前,先System.setProperty("http.strictPostRedirect", Boolean.toString(true));就可以了

坑二、中断上传之后,重新上传
按照道理说,断点续传应该是支持中断的,并且中断之后下一次从中断位置读取文件流上传,但是事实上并不是这样子的,而是从0开始上传,为什么呢?同样道理,经过一番摸索之后,发展在源码中找到了答案。
代码中会有一个TusURLStore的接口,主要是用来存放重定向后得到的url的信息,官方默认实现是基于内存的,底层是一个HashMap,因此,看到这个之后,豁然开朗。难怪中断之后再重新上传还是从0开始,原来是基于内存存储。具体代码贴一下,如下所示
public class TusURLMemoryStore implements TusURLStore {
private Map<String, URL> store = new HashMap<String, URL>();
@Override
public void set(String fingerprint, URL url) {
store.put(fingerprint, url);
}
@Override
public URL get(String fingerprint) {
return store.get(fingerprint);
}
@Override
public void remove(String fingerprint) {
store.remove(fingerprint);
}
}
知道这个套路之后,我们就很容易应对啦,比如说用redis啦。只要实现TusURLStore接口,底层使用redis存储就可以解决了。
坑三、分片断点上传完成后,重新上传同一个文件从零开始上传
上面已经分析了Tus-java-client可以使用redis等介质保存断点续传的url,这样子就不会因为停止进程之后丢失数据。不过当上传完成之后,又发现一个小问题,那就是重复上传同一个文件的时候,发现还是从0开始上传的,按照本人的理解,如果已经上传结束了,再上传同一个文件的时候,应该直接100%。如果本人的理解有误,请各位看官批评指正。
针对这个问题,进一步查看了tus-java-client的源代码。tus客户端是构造一个新的上传对象还是构造一个可恢复的上传对象取决于是否可以获取到一个url。如下所示,在一个叫resumeOrCreateUpload的方法里面,先尝试获取一个resumeUpload对象。如果没有则抛出异常,从而构造一个upload对象
public TusUploader resumeOrCreateUpload(@NotNull TusUpload upload) throws ProtocolException, IOException {
try {
return resumeUpload(upload);
} catch(FingerprintNotFoundException e) {
return createUpload(upload);
} catch(ResumingNotEnabledException e) {
return createUpload(upload);
} catch(ProtocolException e) {
// If the attempt to resume returned a 404 Not Found, we immediately try to create a new
// one since TusExectuor would not retry this operation.
HttpURLConnection connection = e.getCausingConnection();
if(connection != null && connection.getResponseCode() == 404) {
return createUpload(upload);
}
throw e;
}
}
看一下resumeUpload()的实现
public TusUploader resumeUpload(@NotNull TusUpload upload) throws FingerprintNotFoundException, ResumingNotEnabledException, ProtocolException, IOException {
if (!resumingEnabled) {
throw new ResumingNotEnabledException();
}
URL uploadURL = urlStore.get(upload.getFingerprint());
if (uploadURL == null) {
throw new FingerprintNotFoundException(upload.getFingerprint());
}
return beginOrResumeUploadFromURL(upload, uploadURL);
}
上面代码可以看到,uploadURL不为空的时候,会进入一个叫beginOrResumeUploadFromURL的方法。根据 上面的分析,redis保存了uploadURL,并且不会过期,那么顺理成章可以获取这个uploadURL,那么为什么还会从0开始上传呢? 进去看看这个方法应该就知道是怎么回事。
public TusUploader beginOrResumeUploadFromURL(@NotNull TusUpload upload, @NotNull URL uploadURL) throws ProtocolException, IOException {
HttpURLConnection connection = (HttpURLConnection) uploadURL.openConnection();
connection.setRequestMethod("HEAD");
prepareConnection(connection);
connection.connect();
int responseCode = connection.getResponseCode();
// 经过调试,发现从redis获取到的uploadURL尝试连接的时候,返回404,导致抛出了ProtocalException
if(!(responseCode >= 200 && responseCode < 300)) {
throw new ProtocolException("unexpected status code (" + responseCode + ") while resuming upload", connection);
}
String offsetStr = connection.getHeaderField("Upload-Offset");
if(offsetStr == null || offsetStr.length() == 0) {
throw new ProtocolException("missing upload offset in response for resuming upload", connection);
}
long offset = Long.parseLong(offsetStr);
return new TusUploader(this, uploadURL, upload.getTusInputStream(), offset);
}
经过调试之后,发现从redis获取到的uploadURL尝试连接的时候,返回404,导致抛出了ProtocalException,外层的resumeOrCreateUpload方法就有一个捕获这个异常的地方,在这里,会重新获取一个upload对象,从而又进入了一轮新的开始,获取到新的uploadURL之后,更新redis保存的URL,所以才会有了那个奇怪的从0开始。
针对这个问题,本人并不是特别清楚是tus的协议本身就是这样的,还是go-fastdfs服务端就不应该返回404。针对前者,本人会继续研究tus协议,想办法吃透解决;如果是后者,那么只能由go-fastdfs作者协助解决了
附上完整测试代码
public class TusUploadTest {
private static final String UPLOAD_BIG_PATH = "http://172.16.3.100:8051/group1/big/upload";
private static final String UPLOAD_PATH = "http://172.16.3.100:8051/group1/upload";
public static void main(String[] args) throws Exception {
// 下面这个一定要注意,如果不设置为true,将会直接返回301
System.setProperty("http.strictPostRedirect", Boolean.toString(true));
TusClient tusClient = new TusClient();
tusClient.setUploadCreationURL(new URL(UPLOAD_BIG_PATH));
tusClient.enableResuming(new TusRedisUrlStore());
File file = new File("C:\\Document\\Thunder\\linux.x64_11gR2_database_2of2.zip");
final TusUpload upload = new TusUpload(file);
System.out.println("start upload......");
TusExecutor executor = new TusExecutor() {
@Override
protected void makeAttempt() throws ProtocolException, IOException {
TusUploader uploader = tusClient.resumeOrCreateUpload(upload);
uploader.setChunkSize(1024 * 1024);
long start = System.currentTimeMillis();
do {
long totalBytes = upload.getSize();
long bytesUploaded = uploader.getOffset();
double progress = (double) bytesUploaded / totalBytes * 100;
System.out.printf("Upload at %06.2f%%.\n", progress);
} while (uploader.uploadChunk() > -1);
uploader.finish();
String uploadUrl = uploader.getUploadURL().toString();
System.out.println("Upload finished.");
System.out.format("Upload available at: %s\n", uploadUrl);
long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
// 使用hutool进行秒传置换url
String fileId = StrUtil.subAfter(uploadUrl, UPLOAD_BIG_PATH + "/", true);
System.out.println("fileId: " + fileId);
String url = StrUtil.format("{}?md5={}&output=json", UPLOAD_PATH, fileId);
System.out.println("url: "+url);
// 上传大文件的时候(1.xG)需要sleep一下,要不然会有问题
ThreadUtil.sleep(5000);
String result = HttpUtil.get(url);
System.out.println(result);
}
};
executor.makeAttempts();
}
}












