
引言
随着JDK的发展以及JIT的不断优化,我们很多时候都可以写读起来易读但是看上去性能不高的代码了,编译器会帮我们优化代码。之前大学里面学单片机的时候,由于内存以及处理器性能都极其有限(可能很多时候考虑内存的限制优先于处理器),所以很多时候,利用位运算来节约空间或者提高性能,那么这些优秀的思想,放到目前的Java中,是否还有必要这么做呢?我们逐一思考与验证下(其实这也是一个关于Premature optimization的界定的思考)
1. 乘法与左移位
左移一位,相当于乘以2,左移n位,相当于乘以2的n次方。
1 << 1 == 1 * 2 //true
1 << n == 1 * pow(2, n) // true
public int pow(int i, int n) {
assert n >= 0;
int result = 1;
for (int i = 0; i < n; i++) {
result *= i;
}
return result;
}
看上去,移位应该比乘法性能快。那么JIT与JVM虚拟机是否做了一些优化呢?优化分为两部分,一个是编译器优化,另一个是处理器优化。我们先来看看字节码是否一致判断是否有编译优化,例如直接将乘以2优化成左移一位,来编写两个函数:
public void multiply2_1() {
int i = 1;
i = i << 1;
}
public void multiply2_2() {
int i = 1;
i *= 2;
}
编译好之后,用javap -c来看下编译好的class文件,字节码是:
public void multiply2_1();
Code:
0: iconst_1
1: istore_1
2: iload_1
3: iconst_1
4: ishl
5: istore_1
6: return
public void multiply2_2();
Code:
0: iconst_1
1: istore_1
2: iload_1
3: iconst_2
4: imul
5: istore_1
6: return
可以看出左移是ishl,乘法是imul,从字节码上看编译器并没有优化。那么在执行字节码转换成处理器命令是否会优化呢?是会优化的,在底层,乘法其实就是移位,但是并不是简单地左移
我们来使用jmh验证下,添加依赖:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.22</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.22</version>
</dependency>
<!-- https://mvnrepository.com/artifact/site.ycsb/core -->
<dependency>
<groupId>site.ycsb</groupId>
<artifactId>core</artifactId>
<version>0.17.0</version>
</dependency>
实现思路:
被乘数的选择:被乘数固定为1,或者是一个极小值或者极大值或者是稀疏值(转换成2进制很多位是0),测试结果没啥太大的参考意义,所以我们选择2的n次方减某一数字作为被乘数
乘数生成的性能损耗:乘数是2的随机n次方,生成这个的方式要一致,我们这里要测试的仅仅是移位还有乘法运算速度,和实现复杂度没有关系。 实现代码:
@Benchmark @Warmup(iterations = 0) @Measurement(iterations = 300) public void multiply2_n_shift_not_overflow(Generator generator) { int result = 0; int y = 0; for (int j = 0; j < generator.divide.length; j++) { //被乘数x为2^n - j int x = generator.divide[j] - j; int ri = generator.divide.length - j - 1; y = generator.divide[ri]; result += x * y; //为了和移位测试保持一致所以加上这一步 result += y; } }
@Benchmark @Warmup(iterations = 0) @Measurement(iterations = 300) public void multiply2_n_mul_not_overflow(Generator generator) { int result = 0; int y = 0; for (int j = 0; j < generator.divide.length; j++) { int x = generator.divide[j] - j; int ri = generator.divide.length - j - 1; //为了防止乘法多了读取导致性能差异,这里虽然没必要,也读取一下 y = generator.divide[ri]; result += x << ri; //为了防止虚拟机优化代码将上面的给y赋值踢出循环,加上下面这一步 result += y; } }
测试结果:
Benchmark Mode Cnt Score Error Units
BitUtilTest.multiply2_n_mul_not_overflow thrpt 300 35882831.296 ± 48869071.860 ops/s
BitUtilTest.multiply2_n_shift_not_overflow thrpt 300 59792368.115 ± 96267332.036 ops/s
可以看出,左移位相对于乘法还是有一定性能提升的
2. 除法和右移位
这个和乘法以及左移位是一样的.直接上测试代码:
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public void divide2_1_1(Generator generator) {
int result = 0;
for (int j = 0; j < generator.divide.length; j++) {
int l = generator.divide[j];
result += Integer.MAX_VALUE / l;
}
}
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public void divide2_1_2(Generator generator) {
int result = 0;
for (int j = 0; j < generator.divide.length; j++) {
int l = generator.divide[j];
result += Integer.MAX_VALUE >> j;
}
}
结果:
Benchmark Mode Cnt Score Error Units
BitUtilTest.divide2_n_div thrpt 300 10219904.214 ± 5787618.125 ops/s
BitUtilTest.divide2_1_shift thrpt 300 44536470.740 ± 113360206.643 ops/s
可以看出,右移位相对于除法还是有一定性能提升的
3. “取余”与“取与”运算
对于2的n次方取余,相当于对2的n次方减一取与运算,n为正整数。为什么呢?通过下图就能很容易理解:
十进制中,对于10的n次方取余,直观来看就是: 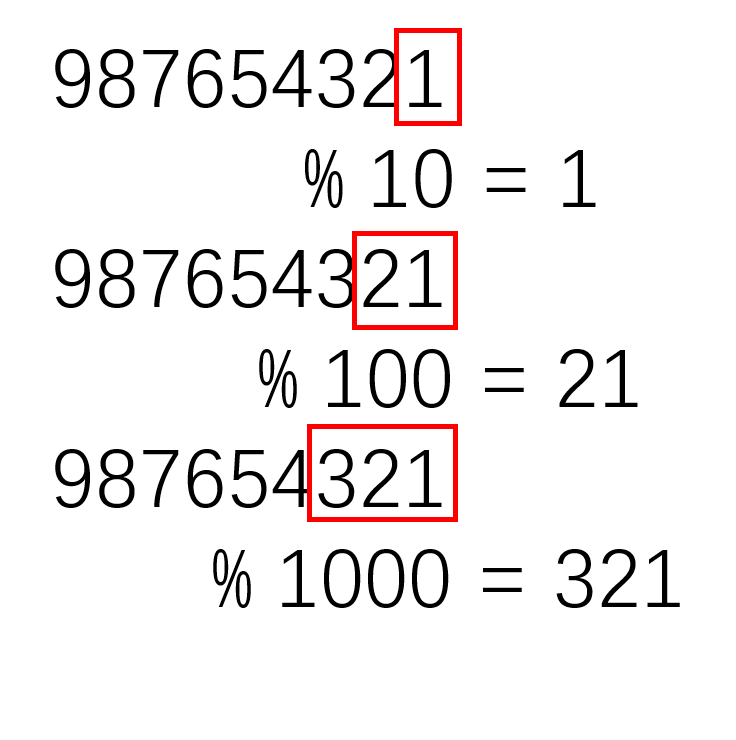 其实就是将最后n位取出,就是余数。 对于二进制,是一样的:
其实就是将最后n位取出,就是余数。 对于二进制,是一样的: 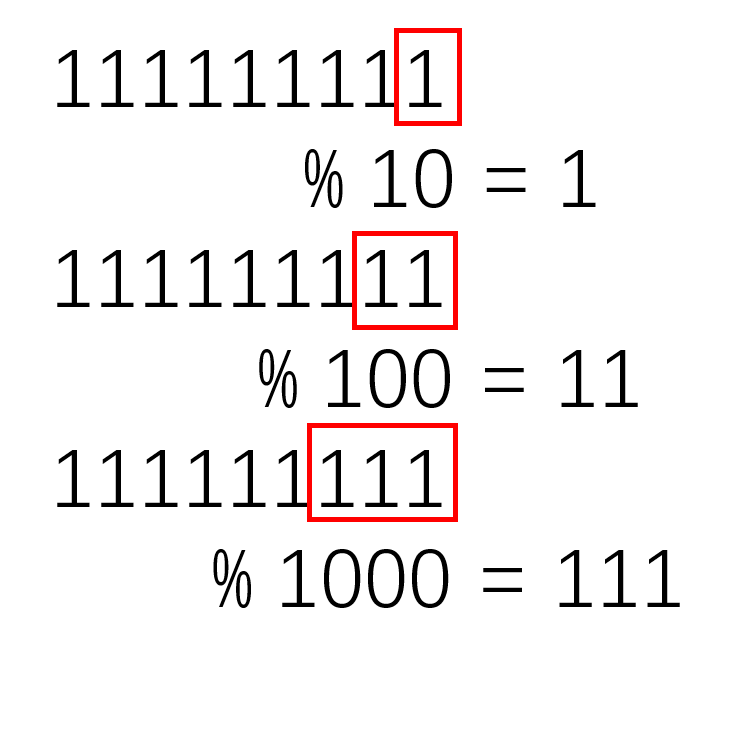 这个运算相当于,对于n-1取与:
这个运算相当于,对于n-1取与: 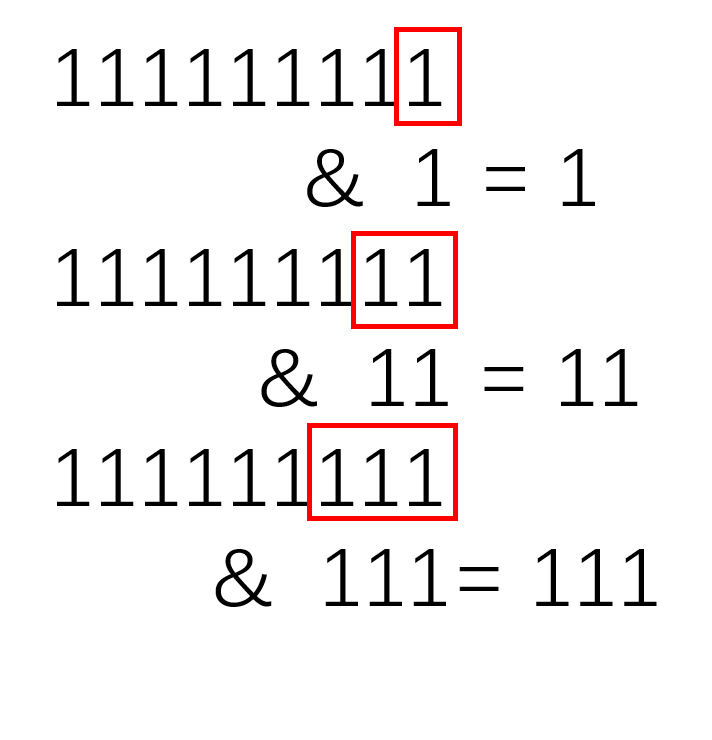
这个是一个很经典的位运算运用,广泛用于各种高性能框架。例如在生成缓存队列槽位的时候,一般生成2的n次方个槽位,因为这样在选择槽位的时候,就可以用取与代替取余;java中的ForkJoinPool的队列长度就是定为2的n次方;netty中的缓存池的叶子节点都是2的n次方,当然这也是因为是平衡二叉查找树算法的实现。
我们来看下性能会好多少:
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public void mod2_n_1(Generator generator) {
int result = 0;
for (int j = 0; j < generator.divide.length; j++) {
int l = generator.divide[j];
result += Integer.MAX_VALUE % l;
}
}
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public void mod2_n_2(Generator generator) {
int result = 0;
for (int j = 0; j < generator.divide.length; j++) {
int l = generator.divide[j];
result += Integer.MAX_VALUE & (l - 1);
}
}
结果:
Benchmark Mode Cnt Score Error Units
BitUtilTest.mod2_n_1 thrpt 300 10632698.855 ± 5843378.697 ops/s
BitUtilTest.mod2_n_2 thrpt 300 80339980.989 ± 21905820.262 ops/s
同时,我们从这里也可以引申出,判断一个数是否是2的n次方的方法,就是看这个数与这个数减一取与运算看是否是0,如果是,则是2的n次方,n为正整数。 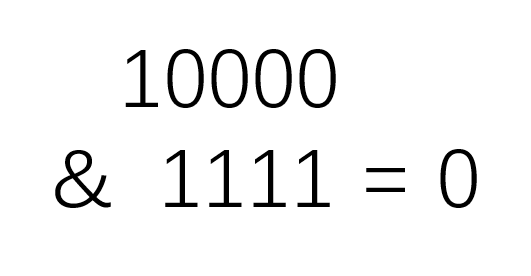
进一步的,奇偶性判断就是看对2取余是否为0,那么就相当于对(2-1)=1取与。
4. 求与数字最接近的2的n次方
这个广泛运用于各种API优化,上文中提到,2的n次方是一个好东西。我们在写框架的很多时候,想让用户传入一个必须是2的n次方的参数来初始化某个资源池,但这样不是那么灵活,我们可以通过用户传入的数字N,来找出不大于N的最大的2的n次方,或者是大于N的最小的2的N次方。
抽象为比较直观的理解就是,找一个数字最左边的1的左边一个1(大于N的最小的2的N次方),或者是最左边的1(小于N的最大的2的N次方),前提是这个数字本身不是2的n次方。
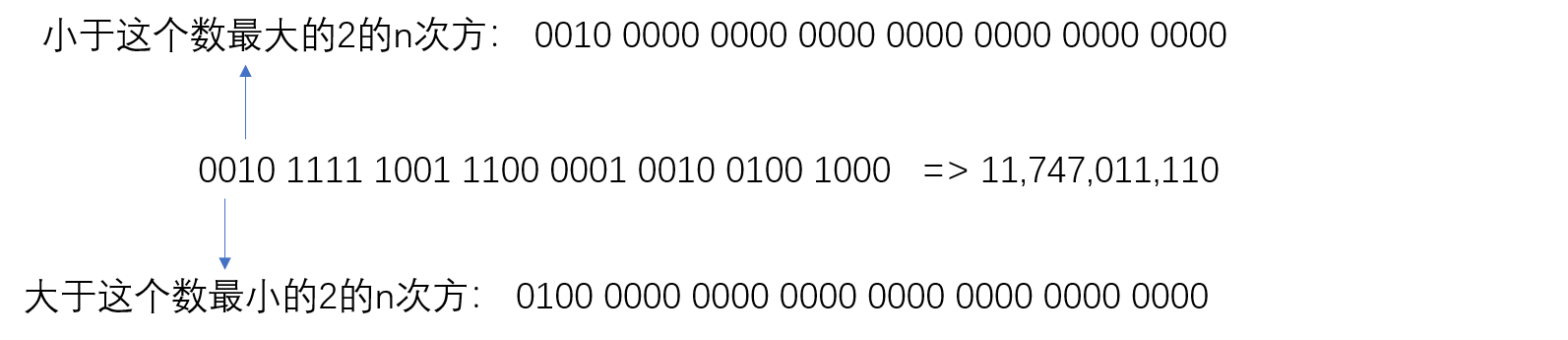
那么,如何找呢?一种思路是,将这个数字最高位1之后的所有位都填上1,最后加一,就是大于N的最小的2的N次方。右移一位,就是小于N的最大的2的N次方。
如何填补呢?可以考虑按位或计算,我们知道除了0或0=0以外,其他的都是1. 我们现在有了最左面的1,右移一位,与原来按位或,就至少有了两位是1,再右移两位并按位或,则至少有四位为1。。。以此类推:
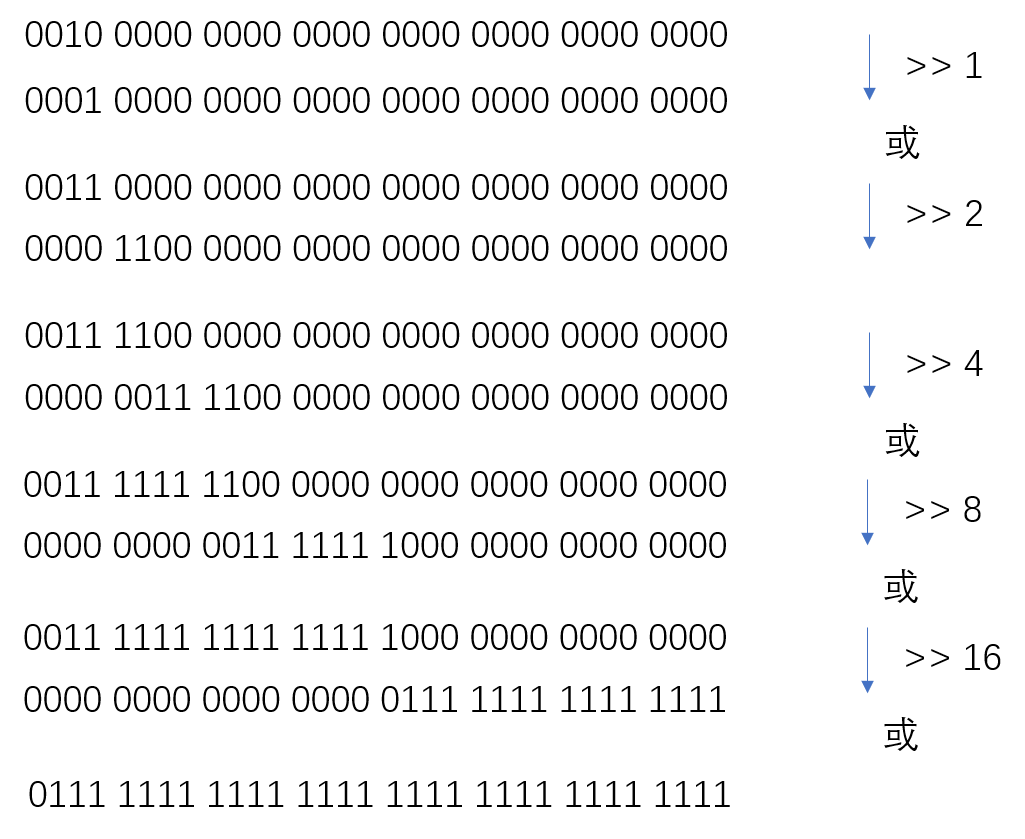
用代码表示是:
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n += 1; //大于N的最小的2的N次方
n = n >>> 1; //小于N的最大的2的N次方
如果有兴趣,可以看一下Java的ForkJoinPool类的构造器,其中的WorkQueue大小,就是通过这样的转换得来的。
5. 交换两个数字
这个在单片机编程中经常会使用这个位运算性质:一个数字异或自己为零,一个数字异或0为自己本身。那么我们就可以利用这个性质交换两个数字。
假设有数字x,y。 我们有x^y^y = x^(y^y)= x^0 = x 还有x^y^y^x^y = 0^y = y 那么我们可以利用:
x = x ^ y;
y = x ^ y; //代入后就是x^y^y
x = x ^ y; //代入后就是x^y^y^x^y
这个方法虽然很巧妙,但是是一种时间换空间的方式; 我们常用的利用另一个变量实现交换是一种空间换时间的方式,来对比下性能:
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public int swap_1() {
int x = Integer.MAX_VALUE, y = Integer.MAX_VALUE / 2;
int z = x;
x = y;
y = z;
return x + y;
}
@Benchmark
@Warmup(iterations = 0)
@Measurement(iterations = 300)
public int swap_2() {
int x = Integer.MAX_VALUE, y = Integer.MAX_VALUE / 2;
x ^= y;
y ^= x;
x ^= y;
return x + y;
}
结果:
Benchmark Mode Cnt Score Error Units
BitUtilTest.swap_1 thrpt 300 267787894.370 ± 559479133.393 ops/s
BitUtilTest.swap_2 thrpt 300 265768807.925 ± 387039155.884 ops/s
测试来看,性能差异并不明显,利用位运算减少了空间占用,减少了GC,但是交换减少了cpu运算,但是GC同样是消耗cpu计算,所以,很难界定。目前还是利用中间变量交换的更常用,也更易读一些。
6. bit状态位
我们为了节省空间,尝尝利用一个数字类型(例如long类型)作为状态数,每一位代表一个状态是true还是false。假设我们使用long类型,则一个状态数可以最多表示64个属性。代码上一般这么写:
public static class Test {
//如果你的field是会被并发修改访问,那么最好还是加上缓存行填充防止false sharing
@jdk.internal.vm.annotation.Contended
private long field;
private static final long SWITCH_1_MASK = 1;
private static final long SWITCH_2_MASK = 1 << 1;
private static final long SWITCH_3_MASK = 1 << 2;
public boolean isSwitch1On() {
return (field & SWITCH_1_MASK) == 1;
}
public void turnOnSwitch1() {
field |= SWITCH_1_MASK;
}
public void turnOffSwitch1() {
field &= ~SWITCH_1_MASK;
}
}
这样能节省大量空间,在实际应用中,很多地方做了这种优化。最直接的例子就是,Java对象的对象头:
|-------------------------------------------------------|--------------------|
| Mark Word (32 bits) | State |
|-------------------------------------------------------|--------------------|
| identity_hashcode:25 | age:4 | biased_lock:1 | lock:2 | Normal |
|-------------------------------------------------------|--------------------|
| thread:23 | epoch:2 | age:4 | biased_lock:1 | lock:2 | Biased |
|-------------------------------------------------------|--------------------|
| ptr_to_lock_record:30 | lock:2 | Lightweight Locked |
|-------------------------------------------------------|--------------------|
| ptr_to_heavyweight_monitor:30 | lock:2 | Heavyweight Locked |
|-------------------------------------------------------|--------------------|
| | lock:2 | Marked for GC |
|-------------------------------------------------------|--------------------|
7. 位计数
基于6,有时候我们想某个状态数里面,有多少个状态是true,就是计算这个状态数里面多少位是1.
比较朴素的方法就是:先判断n的奇偶性,为奇数时计数器增加1,然后将n右移一位,重复上面的步骤,直到移位完毕。
高效一点的方法通过:
n & (n - 1)可以移除最后一位1 (假设最后一位本来是0, 减一后必为1,0 & 1为 0, 最后一位本来是1,减一后必为0,0 & 1为 0)移除了最后一位1之后,计数加1,如果结果不为零,则用结果继续第一步。
int n = Integer.MAX_VALUE; int count = 0; while(n != 0) { n &= n -1; count++; }













