
介绍
Pipeline是Kubeflow社区最近开源的一个端到端工作流项目,帮助我们来管理,部署端到端的机器学习工作流。Kubeflow 是一个谷歌的开源项目,它将机器学习的代码像构建应用一样打包,使其他人也能够重复使用。
kubeflow/pipeline 提供了一个工作流方案,将这些机器学习中的应用代码按照流水线的方式编排,形成可重复的工作流。并提供平台,帮助编排,部署,管理,这些端到端机器学习工作流。
概念
pipeline 是一个面向机器学习的工作流解决方案,通过定义一个有向无环图描述流水线系统(pipeline),流水线中每一步流程是由容器定义组成的组件(component)。
当我们想要发起一次机器学习的试验时,需要创建一个experiment,在experiment中发起运行任务(run)。Experiment 是一个抽象概念,用于分组管理运行任务。
- Pipeline:定义一组操作的流水线,其中每一步都由component组成。 背后是一个Argo的模板配置。
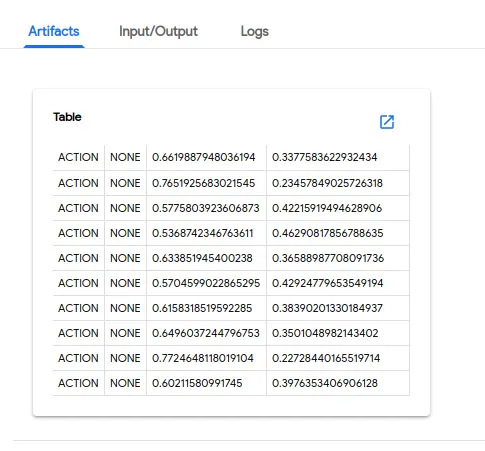
- Component: 一个容器操作,可以通过pipeline的sdk 定义。每一个component 可以定义定义输出(output)和产物(artifact), 输出可以通过设置下一步的环境变量,作为下一步的输入, artifact 是组件运行完成后写入一个约定格式文件,在界面上可以被渲染展示。
- Experiment: 可以看做一个工作空间,管理一组运行任务。
- Run: pipeline 的运行任务实例,这些任务会对应一个工作流实例。由Argo统一管理运行顺序和前后依赖关系。
- Recurring run: 定时任务,定义运行周期,Pipeline 组件会定期拉起对应的Pipeline Run。
Pipeline 里的流程图
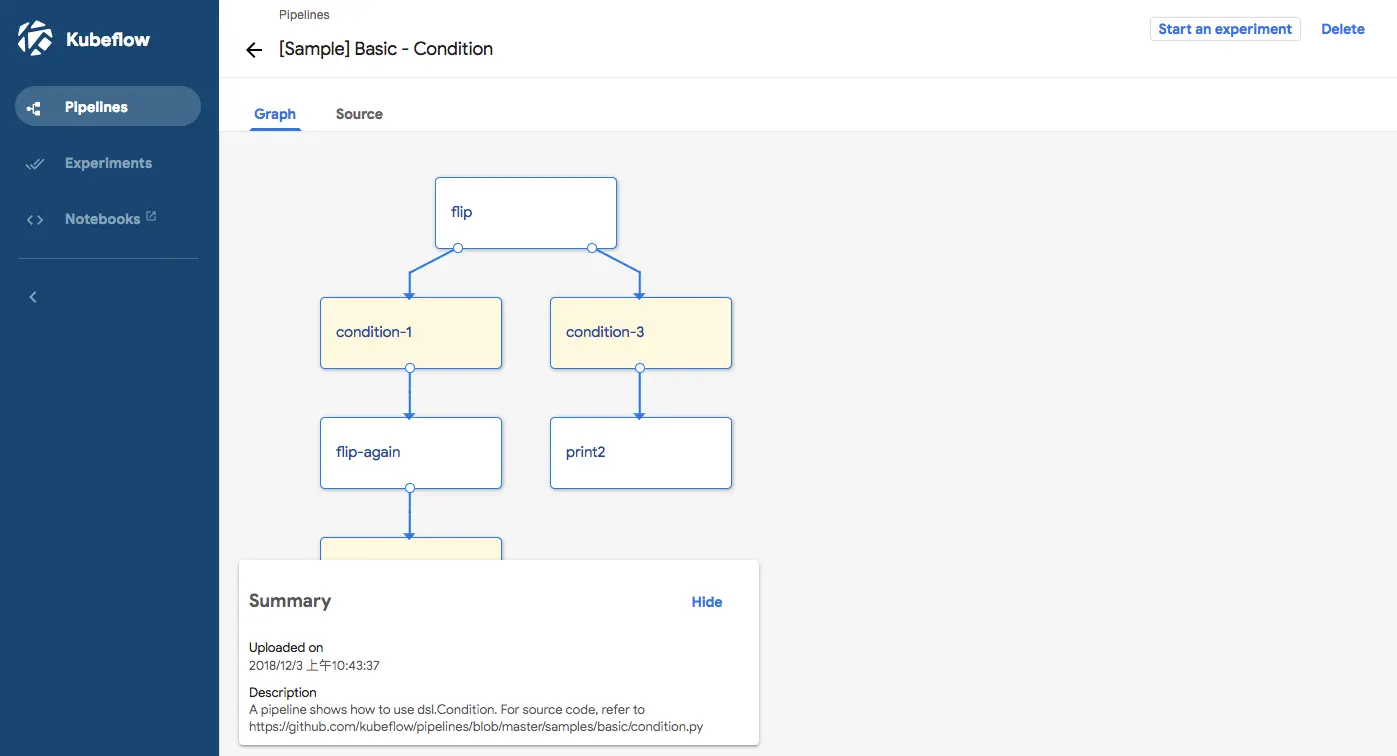
组件的Artifact

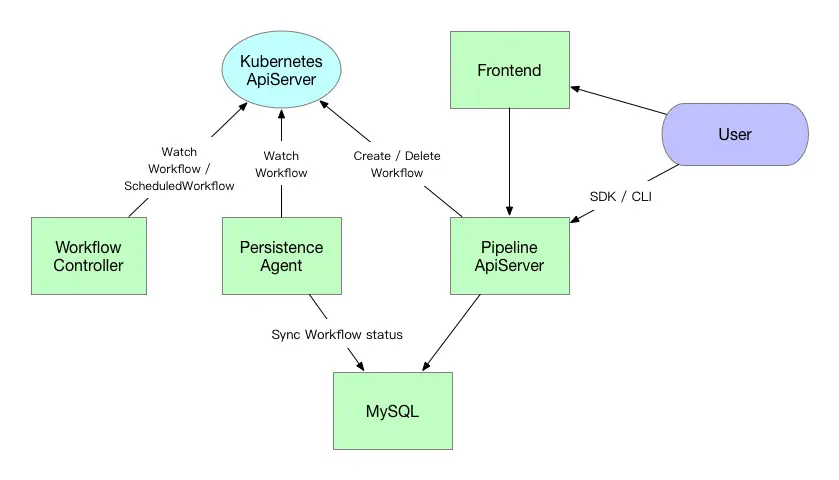
模块
Pipeline 的组件比较简单,大致分为5个部分。
- MySQL: 用于存储Pipeline/Run 等元数据。
- Backend: 一个由go编写的后端,提供kubernetes ApiServer 风格的Restful API。处理前端以及SDK发起的操作请求。 Pipeline/Experiment 之类的请求会直接存入MySQL元数据。和Run 相关的请求除了写入MySQL以外还会通过APIServer 同步操作Argo实例。
- CRD Controller: Pipeline 基于Argo扩展了自己的CRD ScheduledWorkflow, CRD Controller 中会主要监听ScheduledWorkflow和Argo 的Workflow 这两个CRD变化。处理定期运行的逻辑。
- Persistence Agent: 和CRD Controller 一样监听Argo Workflow变化,将Workflow状态同步到MySQL 元数据中。它的主要职责是实时获取工作流的运行结果。
- Web UI:提供界面操作。 从Backend 中读取元数据,将流水线过程和结果可视化,获取日志,发起新的任务等。
其他工具
除了以上核心模块以外, Pipeline提供了一系列工具,帮助更好构建流水线。
- SDK, 用于定义pipeline和component,编译为一个argo yaml模板,可以在界面上导入成pipeline。
- CLI 工具,替代Web UI,调用Backend Api 管理流水线
- Jupyter notebook。 可以在notebook中编写训练代码,也可以在notebook中通过sdk管理Pipeline。
本文作者:萧元
本文为云栖社区原创内容,未经允许不得转载。













