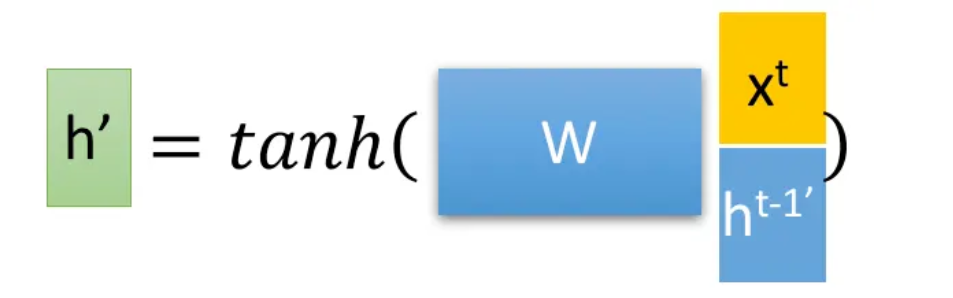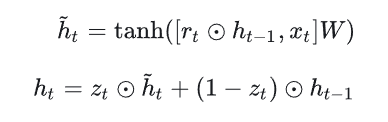本周尝试使用gru模型对相对距离进行预测
gru模型如下:
class GRUModel(nn.Module):
def __init__(self, input_size=6, hidden_size=32, num_layers=2, output_size=1, dropout_prob=0.2):
super(GRUModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.dropout_prob = dropout_prob
# GRU层
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
# Dropout层(在GRU层与全连接层之间)
self.dropout = nn.Dropout(self.dropout_prob)
# 输出层
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# 前向传播GRU
out, _ = self.gru(x, h0)
# 取最后一个时间步的输出(或根据需要聚合输出)
out = out[:, -1, :]
# 通过全连接层得到最终输出
out = self.fc(out)
return out遇到的问题:
出现如下报错
RuntimeError: For unbatched 2-D input, hx should also be 2-D but got 3-D tensor问题就出现在gru模型要求的输入格式为
输入序列:一个形状为 [batch_size, sequence_length, input_size] 的张量
其中 batch_size 是批量中的样本数量,sequence_length 是序列中的时间步长数量,input_size 是每个时间步的输入特征大小。
而当前数据来源输入格式为:
torch.Size([8, 6])
解决方法:使用unsqueeze扩展为三维数据
扩展后数据格式:
torch.Size([8, 1, 6])整体运行效果如下
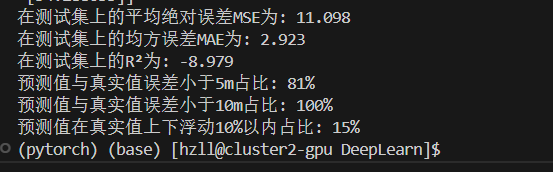
目前使用的是一个二层的gru模型,并通过一个全连接层进行输出。
效果并不是很理想,经过多次调参,发现存在过拟合等问题
于是在GRU层与全连接层之间添加了Dropout层用于解决过拟合的问题
self.dropout = nn.Dropout(self.dropout_prob) def forward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# 前向传播GRU
out, _ = self.gru(x, h0)
# 取最后一个时间步的输出(或根据需要聚合输出)
out = out[:, -1, :]
# 在GRU输出后应用dropout
out = self.dropout(out)
# 通过全连接层得到最终输出
out = self.fc(out)
return out可以发现有了较大的改善,但经过多次调试准确率也并没有达到很高的水平。
之后尝试采用GRU与Cnn模型进行组合来做优化
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=8, kernel_size=3, stride=1, padding=1),
nn.Tanh(),
nn.MaxPool1d(2),
nn.Conv1d(in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.Tanh(),
nn.MaxPool1d(2),
nn.Flatten()
)
self.lstm = nn.GRU(
input_size=16,
hidden_size=32, # RNN隐藏神经元个数
num_layers=2, # RNN隐藏层个数
batch_first=True,
dropout=0.2
)
self.out = nn.Linear(32, 1)
同样,为了适配gru模型的输出,使用nn.Flatten()将cnn输出结果展平为三维数据。
调参后可以得到很好的效果: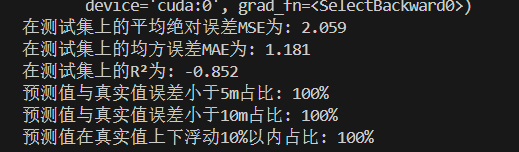
模型结构如下所示: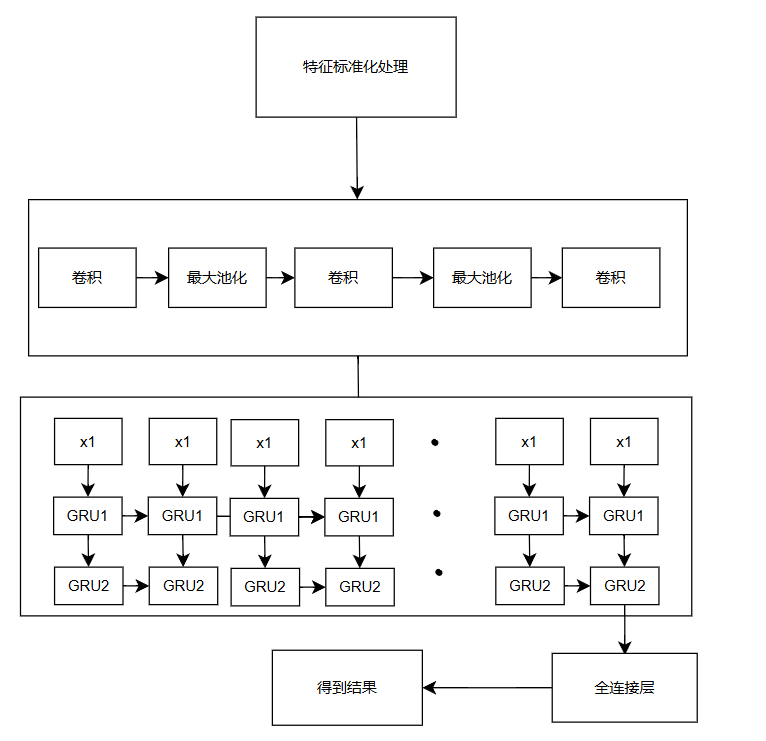
并且GRU-CNN模型在更精细的判定下(如误差在1%以内)则比LSTM-CNN模型表现更优秀
LSTM-CNN:
GRU-CNN:
下图是Gru的内部结构: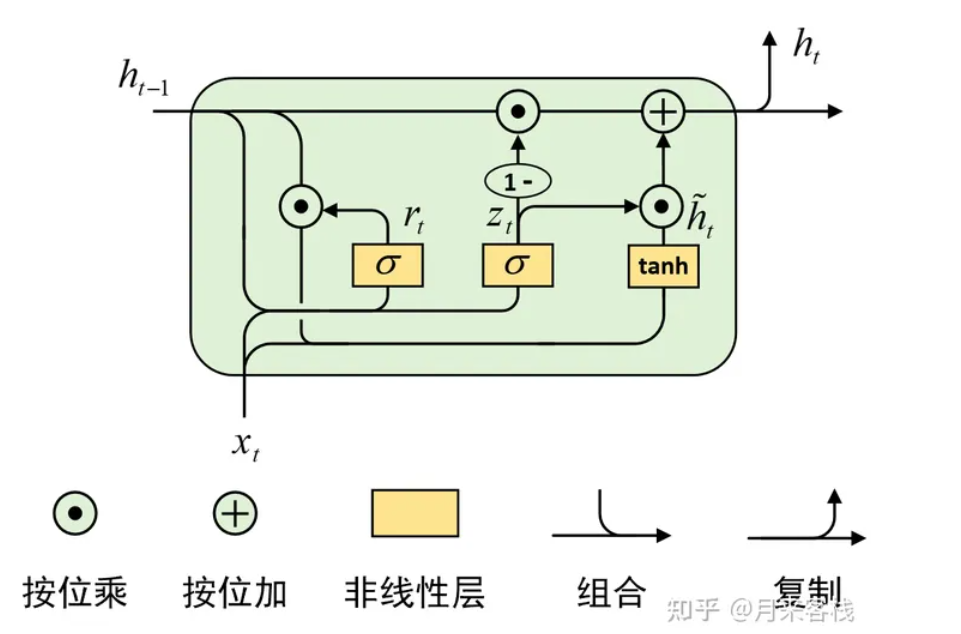
我们先通过上一个传输下来的状态Ht-1和当前节点的输入Xt来获取两个门控状态
有一个当前的输入Xt,和上一个节点传递下来的隐状态 Ht-1,这个隐状态包含了之前节点的相关信息。
结合Xt和Ht-1,GRU会得到当前隐藏节点的输出Yt和Ht传递给下一个节点的隐状态,其中r为控制重置的门控(reset gate),z为控制更新的门控(update gate)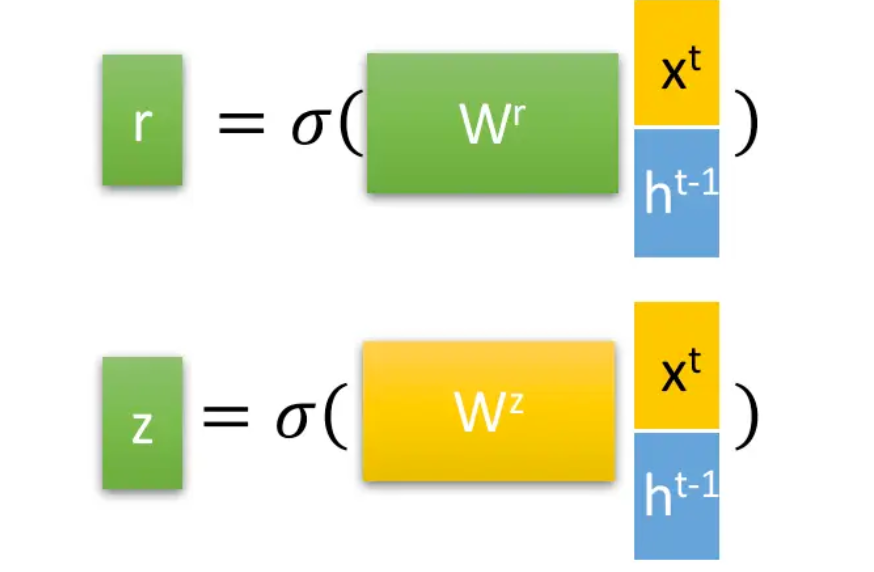
上图可转化为公式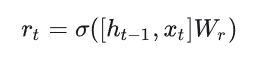
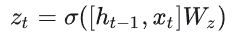
其中σ为Sigmoid函数,[]表示将两个向量进行堆叠组合,其中重置门后续用于对历史记忆状态进行筛选,
更新门的输出结果将同时作用于对历史信息和当前时刻信息的筛选,只是两者为互补关系。
最后,当前时刻的输入同经过重置门后的历史记忆状态经过一个非线性层后便得到了当前时刻的新输入信息,然后再将更新门作用的结果相加便得到了当前时刻GRU的输出ht