Lethe
【SIGMOD'20】论文阅读笔记
Lethe: A Tunable Delete-Aware LSM Engine
https://dl.acm.org/doi/10.114...
简介
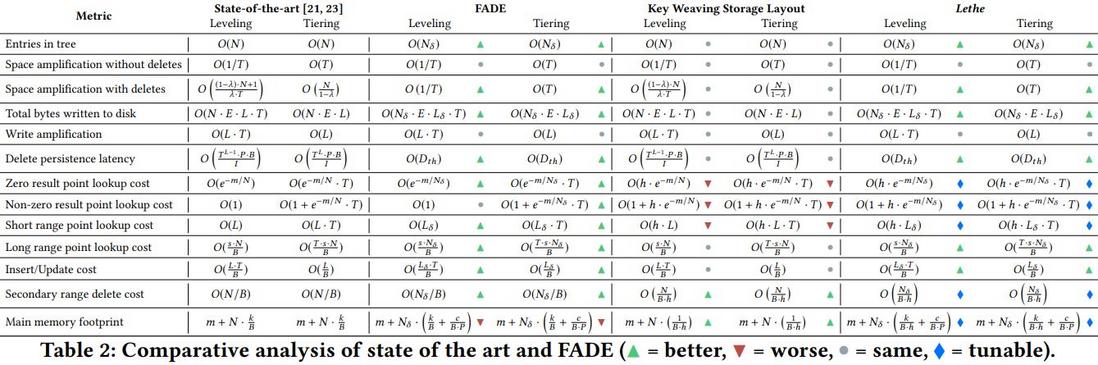
FADE + KiWi。使用非常小的额外元数据、新的delete-aware压缩策略、新的存储布局。
背景
LSM-tree逻辑删除的问题:(逻辑删除:插入tombstone,使目标键的旧条目失效)
- 空间放大:保留了失效的条目,而增加了tombstone
- 读代价:可能读到大量失效的
- 写放大:失效的条目被重复压缩
- 隐私问题:存在unbounded delete persistence latency。
- 持久性删除延迟。逻辑删除不保证持久性删除。持久性删除延迟取决于系统的设计、负载特征,这在执行期间是难以控制的,延迟可能是无限的。(持久性删除延迟:从插入tombstone到完成最底层压缩的时间)
- 非排序键上的大范围删除很棘手,如sort key是id,删除键是时间戳,需要全树压缩,代价巨大。
Lethe
- FADE(fast deletion):保证在有限时间内完成持久性删除。根据包含的无效条目的数量、最古老tombstone的年龄、与其他文件重叠的范围,对文件进行压缩排序,来决定何时对何文件进行压缩、在阈值内清除无效条目。
- KiWi(key weaving storage layout):实现高效的secondary range delete。引入delete tiles的概念。一个delete tile有多个页,一个文件有多个tile。同一文件内,delete tile 间按sort key 排序,tile内的页与页间按 delete key 排序,页内按sort key 排序。在页面级使用布隆过滤器,在sort key和删除键上设置栅栏指针,KiWi通过从delete tile删除整个页面,来实现secondary range delete。假阳性的增加是一个常量。
- Lethe融合FADE和KiWi,实现持久性删除和系统其他性能之间,可调的平衡。
结果
支持任何用户自定义的持久性删除延迟阈值,更高的写吞吐量(1.17-1.41x),更低的空间放大(2.1-9.8x),(代价是写放大提高4%-25%)。支持secondary delete key上高效删除,且不需牺牲写性能、不需全树合并。
FADE
新的压缩策略。添加额外信息:最古老tombstone的年龄$a^{max}$、失效条目估算值$b$。
TTL
$D_{th} $:delete persistence thresold
$d_i$: 第$i$ 层文件分配到的小TTL,$\sum \limits_{i=0}^{L-1} d_i = D_{th} $, 越大层的应分配越多的TTL(通常用指数增长的分配)
$d_i = T \cdot d_{i-1} , i \in [1,L-1] $ $ d_0 = D_{th} \cdot \frac{T-1}{T^{L-1}-1} $
要保证在$D_{th}$ 时间内到达最底层
在每个缓冲flush之后,要更新$d_i$

元数据
LSM引擎存储的元数据包括:文件创建的时间戳、每个文件条目的分布状况(以直方图形式)
如RocksDB,条目序列号(seqnum)、条目的数目(num_entries)、point tombstone的数目(num_delete)。
$a_f^{max}$ :文件f的最古老的tombstone的年龄,使用当前系统时间和最古老的tombstone的时间的差值算出来。存储需要一个时间戳(8字节)。要保证 $a_f^{max} < D_{th} $。用seqnum来计算
$b_f$:文件f因tombstone而失效的条目的估算值。用num_entries, num_delete来计算。$ b_f = p_f + rd_f $。$p_f$:文件f 精确的point tombstone的数目,$rd_f$:由于文件f的range tombstone而失效的(整个数据库)条目的估计数目。使用系统的直方图来预估。
压缩策略
- 压缩触发策略。当前的:某一层饱和(大于阈值大小),触发压缩。FADE增加一条:文件的TTL满了后,即使该层没有饱和,也触发压缩。
- 文件选择策略。当前的:随机选择文件,或者选择与下一层重叠最小的(以减小归并成本)。
FADE的文件选择三种模式:
- The saturation-driven trigger and overlap-driven file selection (SO)。类似于当前的,针对写放大优化。
- The saturation-driven trigger and delete-driven file selection (SD)。选择$b$ 最高的文件,保证更多tombstone被压缩,针对空间放大优化。
- The delete-driven trigger and delete-driven file selection (DD)。选择有过期tombstone的文件。
打成平手:
- 在SD/DD模式下打成平手,则选择具有更古老的tombstone的文件。
- 在SO模式下打成平手,则选择具有更多tombstone的文件。
- 不同层间打成平手,则选择压缩最小的那一层,以免压缩过程中写阻塞。
- 同层的打成平手,则选择有最古老tombstone的文件。
性能分析
- 空间放大。缓解空间放大。$ S_{amp} = (csize(N) - csize(U) ) / csize(U) $
$ csize(N) $: 积累的条目数量 $ csize(U) $: 积累的唯一的条目数量
- 写放大。$ W_{amp} = (csize(N^+) - csize(N) ) / csize(N) $
$N^+$:写入磁盘的所有条目的数量,包括在压缩后作为未修改的重新写入的条目的数量
总体上减少写放大。
- 读性能。由于压缩了无效条目和点tombstone,减少了布隆过滤器需哈希的条目数,降低了假阳率(FPR)。查询可以查更少的层。及时压缩也可加速长范围查找。
- 一致性保证。保证在用户定义的时间阈值内完成持久性删除。
- 空删除。探查BF,仅当返回真值时,插入tombstone。
KiWi
排序键和删除键的交织排序。引入delete tiles。牺牲了小量的额外元数据代价、可调的读性能。
布局
![上传中...]()
用$S$ 表示排序键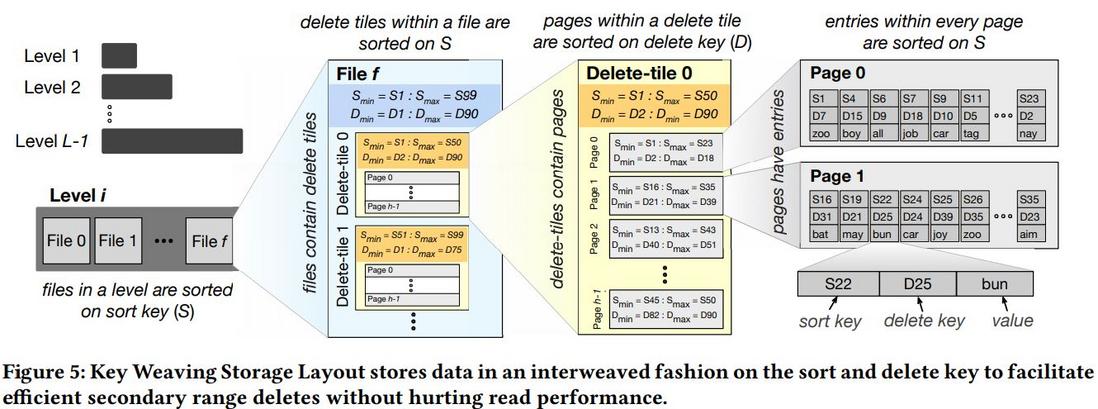
- 层布局。同当前的,即每一层都是包含$S$ 的非重叠范围的文件集合。同一层,若$i < j $,则文件 $ i $ 的所有条目的$S$ 小于文件$j$ 的。
- 文件布局。一个delete tile由多个页组成,一个文件由多个delele tile组成。同一文件,若$k < l $,则delete tile $k$ 的所有条目的$S$ 小于delete tile $ l $ 的。
- delete tile布局。delete tile 的页按删除键排序。同一 delete tile,若$ p < q $,则页 $p$ 的所有$D$ 小于页 $q$的。范围删除时,可以快速清除连续的页(有栅栏指针)。
- 页布局。页内条目按 sort key 排序。
范围删除
- 可以快速清除满足条件连续的页,不需读、更新。 ( full page drop )。
- 对于那些只有部分条目在删除范围的页,则加载这些页,重写。( partial page drops ) 后续压缩会回收空间。一个 delete tile 有0或1个这样的页,就地编辑的开销。
BF、栅栏指针
- 布隆过滤器。KiWi 在一个页上维护一个$S$ 的布隆过滤器。full page drop 不需重构BF,partial page drop 只需少量CPU开销。
- 栅栏指针。对每个 delete tile,设置栅栏指针,跟踪 tile 内 $S$ 最小的条目,辅助BF进行查找。另有删除栅栏指针,在内存中记录每个页的最小$D$,full page drop 时就不需要加载、读取这些页面。
性能分析
Delete tile 粒度。每个 delete tile 的页数 $h $。随着$h$ 增大,删除 $1/h$大多数为 full drop;读性能下降。$h$ 的选取取决于查找、范围删除的频率,以及BF分配的内存、size ratio。
空间
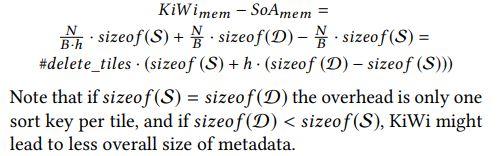
查找
- 点查找。先查 $S$ 的栅栏指针,定位可能包含搜索码的 delete tile 。再用BF过滤器探查,若返回真值,读页进内存,$S$ 上二分查找。若非真值,取下一个tile。
能找到,leveling:$O(1 + h · e ^{−m/N} )$ tiering:$O(1 + T \cdot h · e ^{−m/N} )$
不能找到,leveling:$O(h · e ^{−m/N} )$, tiering:$O(T \cdot h · e ^{−m/N} )$
与state-of-art比,糟糕了一点。
- 范围查找。差不多。见封面。
- secodary范围查找。高效。
trade-off计算
$f$:各负载的占比。
$f_{EPQ}$:点,zero-result查。 $f_{SRQ}$:短范围查。 $f_{SRQ}$: secondary range query。 $f_I$:插入。

用(2)可以按需找到 secondary range delete 和 lookup 的最佳 trade-off。
Lethe
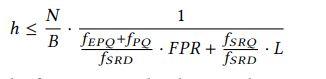
在RocksDB顶层实现。
实验评估
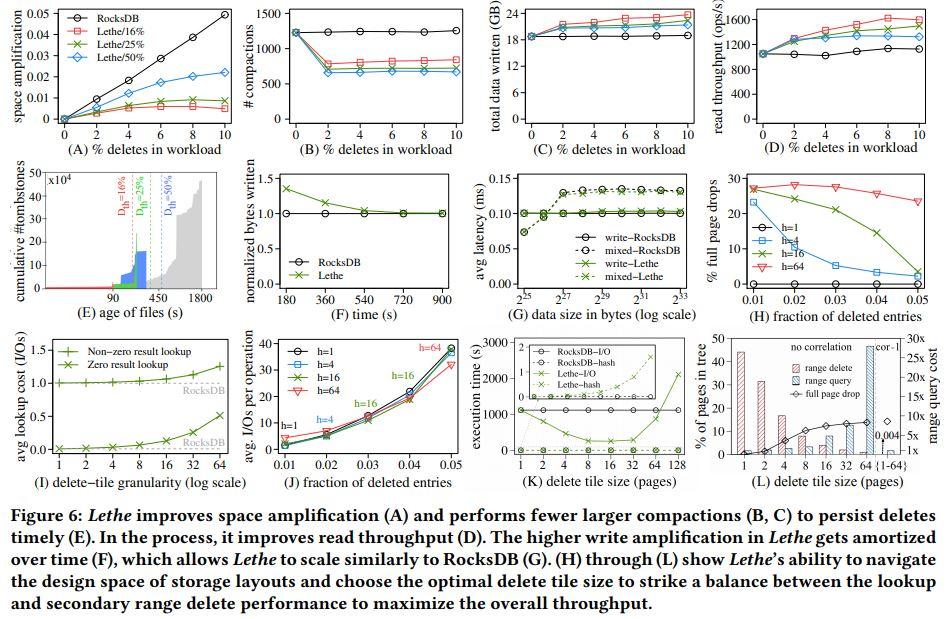
详见论文。
注意:
- C图,Lethe的高于RocksDB,原因是选择过期TTL的文件压缩(DD文件选择策略),这些文件可能与目标层有相当大的重叠。
- F图,一开始,Lethe由于earge merging,写的是RocksDB的1.4倍。但由于压缩清除了无效的条目,过了一段时间后,后续压缩就变少,写的数量与RocksDB持平。可见,Lethe可很快减少写放大。
一点体会
LSM的优化方法众多,取决于RUM的权衡,细节很多。以后要一点点补上这一系列设计智慧。
Lethe着重于保证用户定义阈值内的持久性删除,和快速的大范围secondary range delete,trade-off也是可调的,很有创新性。
一点困惑:F图,似乎效果不尽人意;能否在完成这些功能的同时,及时高并发的外部读写请求?怎么基于Lethe的思想,利用好存储介质本身的特性,做进一步的优化?
代价分析还没完全看懂。论文的定性定量分析方法,也值得一学。
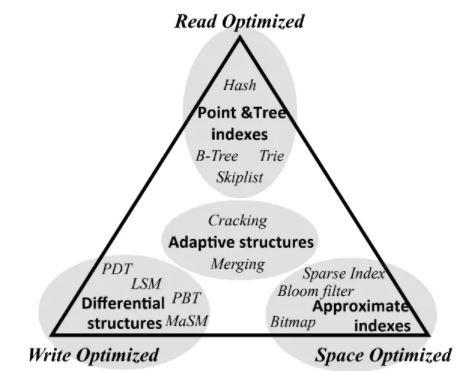
附图RUM的优化(不完整)。