
全文链接:tecdat.cn/?p=2155
最近我们被客户要求撰写关于NLP自然语言处理的研究报告,包括一些图形和统计输出。
随着网民规模的不断扩大,互联网不仅是传统媒体和生活方式的补充,也是民意凸显的地带。领导干部参与网络问政的制度化正在成为一种发展趋势,这种趋势与互联网发展的时代需求是分不开的
▼
人民网《地方领导留言板》是备受百姓瞩目的民生栏目,也是人民网品牌栏目,被称为“社情民意的集散地、亲民爱民的回音壁”。
基于以上背景,tecdat研究人员对北京留言板里面的留言数据进行分析,探索网民们在呼吁什么。
数量与情感
朝阳区群众最活跃
图表

从上图可以看出不同地区留言板的情感倾向分布,总的来说,负面情感留言数目和积极情感相差不多,负面情感留言较多,占比46%,积极情感留言占比42%,中立情感的留言占比11%。
从地区来看,活跃在各大媒体的“朝阳区群众”留言数目也是最多的,其次是海淀区,昌平区。因此,从情感分布来看大部分留言还是在反应存在的问题,而不是一味赞美或者灌水。
点击标题查阅往期内容


左右滑动查看更多

01
02

03

04

主题分析
外地户口问题呼声最高
接下来,我们对于语料进行LDA建模,就是从语料库中挖掘出不同主题并进行分析,换言之,LDA提供了一种较为方便地量化研究主题的机器学习方法。
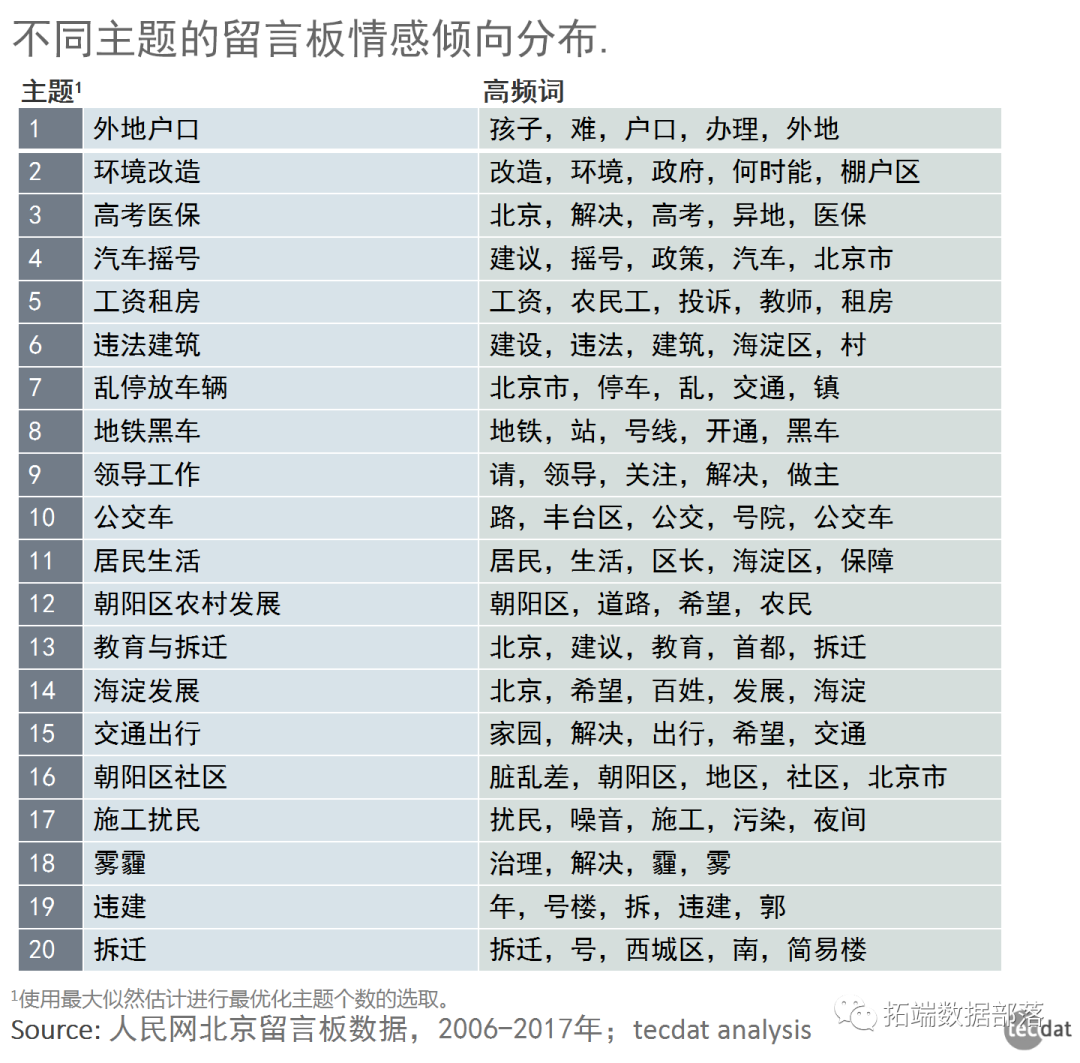
我们使用最大似然估计进行最优化主题个数的选取。当主题个数定为20的时候,似然估计数最大,即留言板数据分为20个主题的可能性比较大。将模型生成的20个主题中的前五个高频词取出,如下表所示。
图表
然后我们将占比最高的前六个主题与它们的情感倾向进行分析。
图表

从上图可以看出大家关于6大主题的讨论:
主题1反应孩子,外地户口办理的问题是最多的,反应了外地落户北京相关的难题(e.g.父母在京工作20多年,儿女上学却因户口问题不能进入好的高校就读)。
主题2是反应环境改造及棚户改造(e.g.棚户房屋破旧、墙面潮湿、上下水管道老化腐烂现象严重经常造成跑冒滴漏,遇到雨雪天气,道路积水、泥泞不堪,大院居民尤其是老人小孩出行非常不便)。
主题3是反应高考和医保(e.g.外地人衷心的希望政府能关注一下孩子在北京的高考问题)。
主题4是汽车摇号政策(e.g.现行的摇号方案是不可行,治标不治本.有的摇号是一个人摇不上,全家人都出动;有的是想买车根本摇不号;有的是不想买车就摇上了)。
主题5是反应工资和租房问题(e.g.我是外地退休教师。因为孩子在北京工作,故到北京帮助孩子料理家务,以支持孩子工作。因为北京房价昂贵,我们买不起大房,三代人只能挤着住。我想问问市长,我们是否也能住公租房)。
主题6是违法建筑(e.g.XX雅苑许多一层业主私搭乱建成风,且物业无能,造成极大的安全隐患)。
地区、主题与情感得分
接下来我们分析了不同主题和地区的情感倾向分布。从下图可以看出,主题3高考和医保、主题6 违法建筑、主题13教育拆迁的留言内容中积极情感占较大比例。
图表

我们发现在不同主题中情感得分最高的地区中海淀区最多,其次是朝阳区和大兴区。同时也可以发现,情感得分最高的是在主题11居民生活下的朝阳区留言内容。总的来说,根据积极情感的内容分布来看,主题3高考和医保、主题6 违法建筑、主题13教育拆迁的留言内容中表现出较好的反馈。

本文摘选 《 数据聆听人民网留言板的那些网事 》 ,点击“阅读原文”获取全文完整资料。
点击标题查阅往期内容
Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组数据集
自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据
R语言对NASA元数据进行文本挖掘的主题建模分析
R语言文本挖掘、情感分析和可视化哈利波特小说文本数据
Python、R对小说进行文本挖掘和层次聚类可视化分析案例
用于NLP的Python:使用Keras进行深度学习文本生成
长短期记忆网络LSTM在时间序列预测和文本分类中的应用
用Rapidminer做文本挖掘的应用:情感分析
R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究
R语言对推特twitter数据进行文本情感分析
Python使用神经网络进行简单文本分类
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
R语言文本挖掘使用tf-idf分析NASA元数据的关键字
R语言NLP案例:LDA主题文本挖掘优惠券推荐网站数据
Python使用神经网络进行简单文本分类
R语言自然语言处理(NLP):情感分析新闻文本数据
Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言对推特twitter数据进行文本情感分析
R语言中的LDA模型:对文本数据进行主题模型topic modeling分析
R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)











