
会开发AI的AI:超网络有望让深度学习大众化 超网络(hypernetwork)可以加快训练AI的过程。
编者按:在执行特定类型任务,如图像识别、语音识别等方面,AI已经可以与人类相媲美了,甚至有时候已经超越了人类。但这些AI事先必须经过训练,而训练是个既耗时又耗计算能力的过程,有上百万甚至几十亿的参数需要优化。但最近研究人员做出了能瞬时预测参数的超网络。通过利用超网络(hypernetwork),研究人员现在可以先下手为强,提前对人工神经网络进行调优,从而节省部分训练时间和费用。文章来自编译。译者:boxi。

划重点:
人工智能是一场数字游戏,训练耗时耗力
超网络可以在几分之一秒内预测出新网络的参数
超网络的表现往往可以跟数千次 SGD 迭代的结果不相上下,有时甚至是更好
超网络有望让深度学习大众化
人工智能在很大程度上是一场数字游戏。10 年前,深度神经网络(一种学习识别数据模式的 AI 形式)之所以开始超越传统算法,那是因为我们终于有了足够的数据和处理能力,可以充分利用这种AI。
现如今的神经网络对数据和处理能力更加渴望。训练它们需要对表征参数的值进行仔细的调整,那些参数代表人工神经元之间连接的强度,有数百万甚至数十亿之巨。其目标是为它们找到接近理想的值,而这个过程叫做优化,但训练网络达到这一点并不容易。 DeepMind研究科学家Petar Veličković 表示:“训练可能需要数天、数周甚至数月之久”。
但这种情况可能很快就会改变。加拿大安大略省圭尔夫大学(University of Guelph)的Boris Knyazev和他的同事设计并训练了一个“超网络”——这有点像是凌驾于其他神经网络之上的最高统治者——用它可以加快训练的过程。给定一个为特定任务设计,未经训练的新深度神经网络,超网络可以在几分之一秒内预测出该新网络的参数,理论上可以让训练变得不必要。由于超网络学习了深度神经网络设计当中极其复杂的模式,因此这项工作也可能具有更深层次的理论意义。
目前为止,超网络在某些环境下的表现出奇的好,但仍有增长空间——考虑到问题的量级,这是很自然的。如果他们能解决这个问题,Veličković说:“这将对机器学习产生很大的影响。”。
变成“超网络” 目前,训练和优化深度神经网络最好的方法是随机梯度下降(SGD) 技术的各种变种。训练涉及到将网络在给定任务(例如图像识别)中所犯的错误最小化。 SGD 算法通过大量标记数据来调整网络参数,并减少错误或损失。梯度下降是从损失函数的高位值一级级向下降到某个最小值的迭代过程,代表的是足够好的(或有时候甚至是可能的最好)参数值。
但是这种技术只有在你有需要优化的网络时才有效。为了搭建最开始的神经网络(一般由从输入到输出的多层人工神经元组成),工程师必须依靠自己的直觉和经验法则。这些结构在神经元的层数、每层包含的神经元数量等方面可能会有所不同。
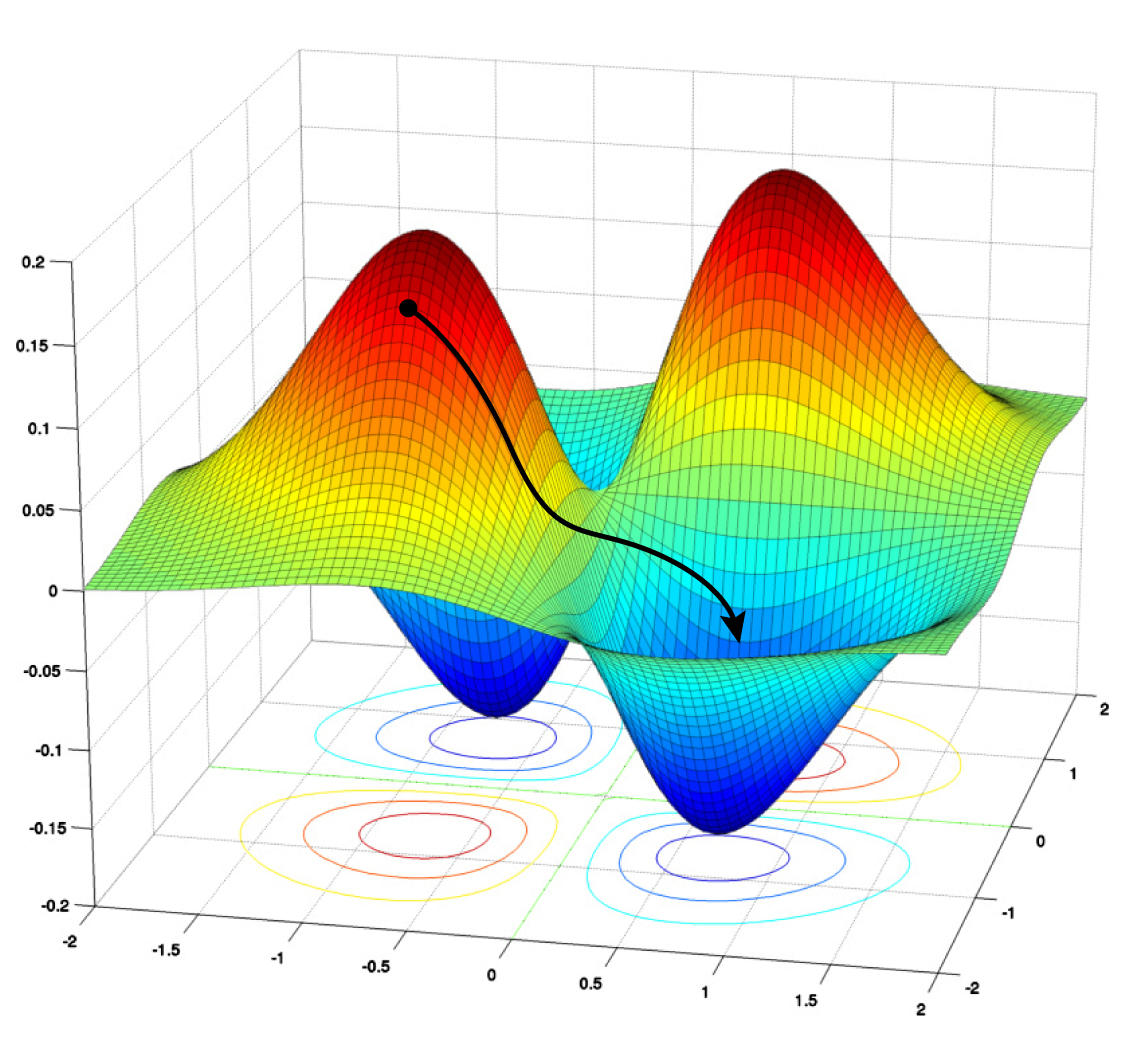
梯度下降算法让网络沿着其“损失景观”向下走,其中高位值表示较大错误或损失。算法旨在找到全局最小值,让损失最小化。
理论上可以从多个结构出发,然后优化每个结构并选出最好的。但Google Brain 访问学者 MengYe Ren 说:“训练需要花费相当多的时间,要想训练和测试每以个候选网络结构是不可能的。这种做法扩展不好,尤其是如果要考虑到数百万种可能设计的话。”
于是 2018 年,Ren 与自己在多伦多大学的前同事 Chris Zhang ,以及他们的指导 Raquel Urtasun 开始尝试一种不同的方法。他们设计出一种所谓的图超网络(Graph Hypernetwork, GHN),这种网络可以在给出一组候选结构的情况下,找出解决某个任务的最佳深度神经网络结构。
顾名思义,“图”指的是深度神经网络的架结构,可以认为是数学意义的图——由线或边连接的点或节点组成的集合。此处节点代表计算单元(通常是神经网络的一整层),边代表的是这些单元互连的方式。
原理是这样的。图超网络从任何需要优化的结构(称其为候选结构)开始,然后尽最大努力预测候选结构的理想参数。接着将实际神经网络的参数设置为预测值,用给定任务对其进行测试。Ren 的团队证明,这种方法可用于来对候选结构进行排名,并选择表现最佳的结构。
当 Knyazev 和他的同事想出图超网络这个想法时,他们意识到可以在此基础上进一步开发。在他们的新论文里,这支团队展示了 GHN 的用法,不仅可以用来从一组样本中找到最佳的结构,还可以预测最好网络的参数,让网络表现出绝对意义上的好。在其中的最好还没有达到最好的情况下,还可以利用梯度下降进一步训练该网络。
在谈到这项新工作时,Ren 表示:“这篇论文非常扎实,里面包含的实验比我们多得多。他们在非常努力地提升图超网络的绝对表现,这是我们所乐见的。”
训练“训练师” Knyazev和他的团队将自己的超网络称为是 GHN -2,这种网络从两个重要方面改进了Ren及其同事构建的图超网络。
首先,他们需要依赖 Ren 等人的技术,用图来表示神经网络结构。该图里面的每个节点都包含有关于执行特定类型计算的神经元子集的编码信息。图的边则描述了信息是如何从一个节点转到另一节点,如何从输入转到输出的。
他们借鉴的第二个想法是一种方法,训练超网络来预测新的候选结构的方法。这需要用到另外两个神经网络。第一个用来开启对原始候选图的计算,更新与每个节点相关的信息,第二个把更新过的节点作为输入,然后预测候选神经网络相应计算单元的参数。这两个网络也有自己的参数,在超网络能够正确预测参数值之前,必须对这两个网络进行优化。
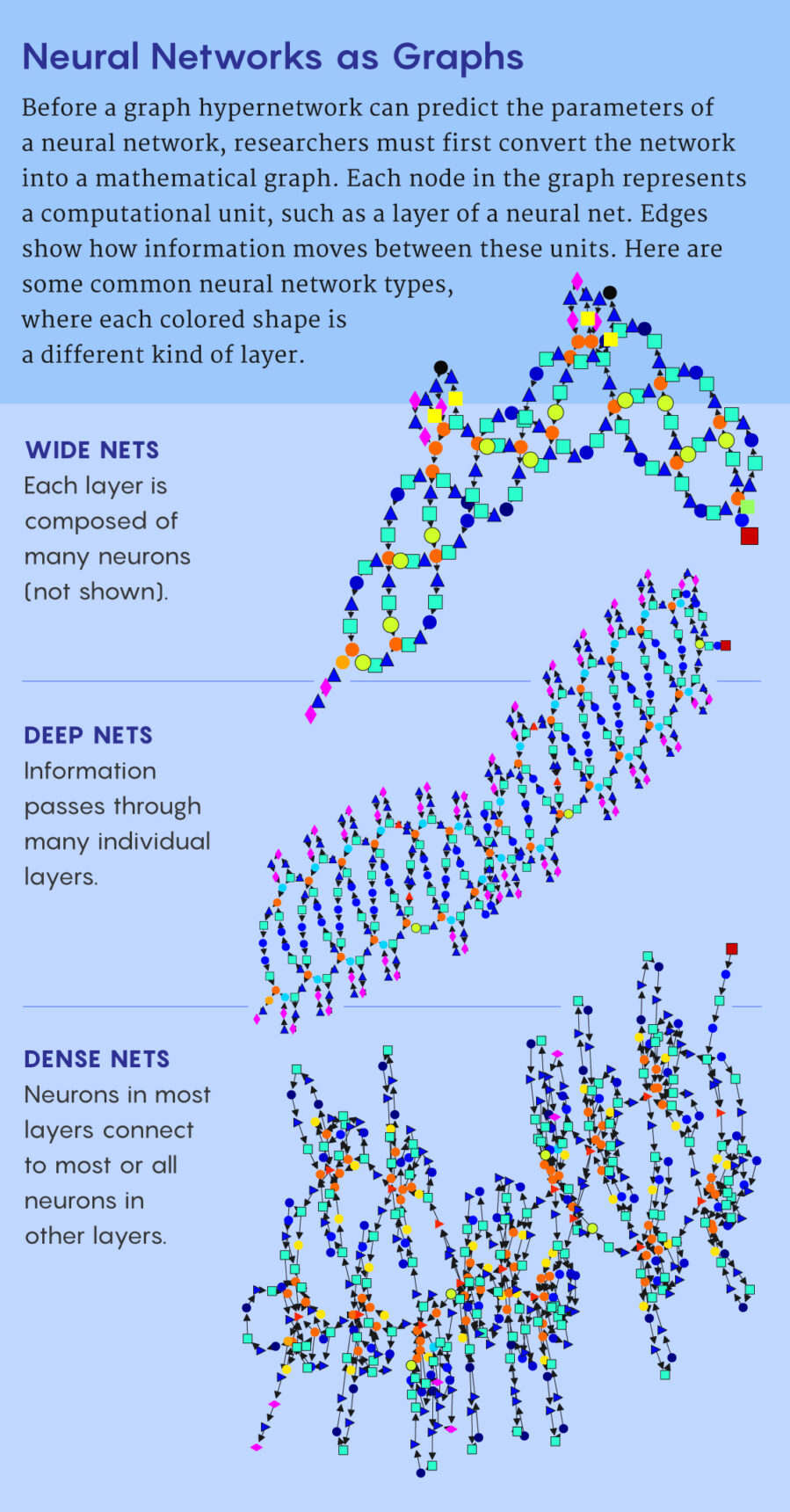
用图来表示神经网络
为此,你得训练数据——在本案例中,数据就是可能的人工神经网络(ANN)结构的随机样本。对于样本的每一个结构,你都要从图开始,然后用图超网络来预测参数,并利用预测的参数对候选 ANN进行初始化。然后该ANN会执行一些特定任务,如识别一张图像。通过计算该ANN的损失函数来更新做出预测的超网络的参数,而不是更新该ANN的参数以便做出更好的预测。这样以来,该超网络下一次就能做得更好。现在,通过遍历部分标记训练图像数据集的每一张图像,以及随机样本结构里面的每一个ANN,一步步地减少损失,直至最优。到了一定时候,你就可以得到一个训练好的超网络。
由于Ren 的团队没有公开他们的源代码,所以Knyazev 的团队采用上述想法自己从头开始写软件。然后Knyazev及其同事在此基础上加以改进。首先,他们确定了 15 种类型的节点,这些节点混合搭配可构建几乎任何的现代深度神经网络。在提高预测准确性方面,他们也取得了一些进展。
最重要的是,为了确保 GHN-2 能学会预测各种目标神经网络结构的参数,Knyazev 及其同事创建了一个包含 100 万种可能结构的独特数据集。Knyazev 说:“为了训练我们的模型,我们创建了尽量多样化的随机结构”。
因此,GHN-2 的预测能力很有可能可以很好地泛化到未知的目标结构。Google Research的Brain Team研究科学家 Thomas Kipf 说:“比方说,人们使用的各种典型的最先进结构他们都可以解释,这是一大重大贡献。”
结果令人印象深刻 当然,真正的考验是让 GHN-2 能用起来。一旦 Knyazev 和他的团队训练好这个网络,让它可以预测给定任务(比方说对特定数据集的图像进行分类)的参数之后,他们开始测试,让这个网络给随机挑选的候选结构预测参数。该新的候选结构与训练数据集上百万结构当中的某个也许具备相似的属性,也可能并不相同——有点算是异类。在前一种情况下,目标结构可认为属于分布范围内;若是后者,则属于分布范围外。深度神经网络在对后者进行预测时经常会失败,所以用这类数据测试 GHN-2 非常重要。
借助经过全面训练的 GHN-2,该团队预测了 500 个以前看不见的随机目标网络结构的参数。然后将这 500 个网络(其参数设置为预测值)与使用随机梯度下降训练的相同网络进行对比。新的超网络通常可以抵御数千次 SGD 迭代,有时甚至做得更好,尽管有些结果更加复杂。
借助训练好的 GHN-2 模型,该团队预测了 500 个之前未知的随机目标网络结构的参数。然后将这 500 个(参数设置为预测值的)网络与利用随机梯度下降训练的同一网络进行对比。尽管部分结果有好有坏,但新的超网络的表现往往可以跟数千次 SGD 迭代的结果不相上下,有时甚至是更好。
对于图像数据集 CIFAR-10 ,GHN-2 用于分布范围内的结构得到的平均准确率为 66.9%,而用经过近 2500 次 SGD 迭代训练出来的网络,其平均准确率为 69.2%。对于不在分布范围内的结构,GHN-2 的表现则出人意料地好,准确率达到了约 60%。尤其是,对一种知名的特定深度神经网络架构, ResNet-50, GHN2的准确率达到了 58.6% 这是相当可观的。在本领域的顶级会议 NeurIPS 2021 上,Knyazev说:“鉴于 ResNet-50 比我们一般训练的结构大了有大概 20 倍,可以说泛化到 ResNet-50 的效果出奇地好。”。
不过GHN-2 应用到 ImageNet 上却表现不佳。ImageNet 这个数据集规模很大。平均而言,它的准确率只有 27.2% 左右。尽管如此,跟经过 5000SGD 迭代训练的同一网络相比,GHN-2的表现也要好一些,后者的平均准确度只有 25.6%。 (当然,如果你继续用 SGD 迭代的话,你最终可以实现95% 的准确率,只是成本会非常高。)最关键的是,GHN-2 是在不到一秒的时间内对ImageNet 做出了参数预测,而如果用 SGD 在GPU上预测参数,要想达到同样的表现,花费的平均时间要比 GHN-2 要多 10000 倍。
Veličković说:“结果绝对是令人印象深刻。基本上他们已经极大地降低了能源成本。”
一旦GHN-2 从结果样本中为特定任务选出了最佳的神经网络,但这个网络表现还不够好时,至少该模型已经过了部分训练,而且可以还进一步优化了。与其对用随机参数初始化的网络进行 SGD,不如以 GHN-2 的预测作为起点。Knyazev 说:“基本上我们是在模仿预训练”。
超越 GHN-2 尽管取得了这些成功,但Knyazev 认为刚开始的时候机器学习社区会抵制使用图超网络。他把这种阻力拿来跟 2012 年之前深度神经网络的遭遇相比拟。当时,机器学习从业者更喜欢人工设计的算法,而不是神秘的深度网络。但是,当用大量数据训练出来的大型深度网络开始超越传统算法时,情况开始逆转。Knyazev :“超网络也可能会走上同样的道路。”
与此同时,Knyazev 认为还有很多的改进机会。比方说,GHN-2 只能训练来预测参数,去解决给定的任务,比如对 CIFAR-10 或 ImageNet 里面的图像进行分类,但不能同时执行不同的任务。将来,他设想可以用更加多样化的结果以及不同类型的任务(如图像识别、语音识别与自然语言处理)来训练图超网络。然后同时根据目标结构与手头的特定任务来做出预测。
如果这些超网络确实能成功的话,那么新的深度神经网络的设计和开发,将不再是有钱和能够访问大数据的公司的专利了。任何人都可以参与其中。Knyazev 非常清楚这种“让深度学习大众化”的潜力,称之为长期愿景。
然而,如果像GHN -2 这样的超网络真的成为优化神经网络的标准方法, Veličković强调了一个潜在的大问题。他说,对于图超网络,“你有一个神经网络——本质上是一个黑盒子——预测另一个神经网络的参数。所以当它出错时,你无法解释[它]。”
不过,Veličković 强调,如果类似 GHN-2 这样的超网络真的成为优化神经网络的标准方法的话,可能会有一个大问题。他说:“你会得到一个基本上是个黑箱的神经网络,然后再用图超网络去预测另一个神经网络的参数。如果它出错,你没法解释错在哪里。”
当然,神经网络基本上也是这样。Veličković说:“我不会说这是弱点,我把这叫做告警信号。”
不过Kipf看到的却是一线希望。 “让我最为兴奋的是其他东西。” GHN-2 展示了图神经网络在复杂数据当中寻找模式的能力。
通常,深度神经网络是在图像、文本或音频信号里面寻找模式,这类信息一般都比较结构化。但 GHN-2 却是在完全随机的神经网络结构图里面寻找模式。而图是非常复杂的数据。
还有,GHN-2 可以泛化——这意味着它可以对未知、甚至不在分布范围内的网络结构的参数做出合理的预测。Kipf 说:“这项工作向我们表明,不同结构的很多模式其实多少是优点相似的,而且模型能学习如何将知识从一种结构转移到另一种结构,这可能会启发神经网络新理论的诞生。”
如果是这样的话,它可能会让我们对这些黑箱有新的、更深入的理解。
转载自:https://36kr.com/p/1628481160214024
人工智能技术与咨询了解更多相关信息及知识






