
JDK13已经发布有一段时间了,年前没有细看,单纯的就是浏览了一下,没成想,疫情在家,假期从寒假放到了暑假,闲来无聊,突然想起来他,就在网上查了一下相关的文档和资料,在即将开工之前,进行一个整理
首先肯定奉上的是我自己觉得比较有意思的几大特性和大家一起分享
350: Dynamic CDS Archives
351: ZGC: Uncommit Unused Memory
353: Reimplement the Legacy Socket API
354: Switch Expressions (Preview)
355: Text Blocks (Preview)
在这里面,我觉得最有意思的是两个,ZGC和Switch,其中ZGC因为GC这个名词以及JVM调优的缘故,关注比较多,今天就来跟大家分享一下我对于ZGC的理解。
什么是ZGC
ZGC(Z Garbage Collector)是一款由Oracle公司研发的,以低延迟为首要目标的一款垃圾收集器。它是基于动态Region内存布局,(暂时)不设年龄分代,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-整理算法的收集器。在JDK 11新加入,还在实验阶段,主要特点是:回收TB级内存(最大4T),停顿时间不超过10ms。
动态Region
ZGC的Region可以具有如图所示的大、中、小三类容量:

· 小型Region(Small Region):容量固定为2MB,用于放置小于256KB的小对象。
· 中型Region(Medium Region):容量固定为32MB,用于放置大于等于256KB但小于4MB的对象。·
· 大型Region(Large Region):容量不固定,可以动态变化,但必须为2MB的整数倍,用于放置4MB或以上的大对象。每个大型Region中只会存放一个大对象,最小容量可低至4MB,所有大型Region可能小于中型Region。大型Region在ZGC的实现中是不会被重分配的,因为复制一个大对象的代价非常高昂。
染色指针技术
HotSpot虚拟机的标记实现方案有如下几种:
1. 把标记直接记录在对象头上(如Serial收集器);
2. 把标记记录在与对象相互独立的数据结构上(如G1、Shenandoah使用了一种相当于堆内存的1/64大小的,称为BitMap的结构来记录标记信息);
3. 直接把标记信息记在引用对象的指针上(如ZGC)
染色指针是一种直接将少量额外的信息存储在指针上的技术。目前在Linux下64位的操作系统中高18位是不能用来寻址的,但是剩余的46位却可以支持64T的空间,到目前为止我们几乎还用不到这么多内存。于是ZGC将46位中的高4位取出,用来存储4个标志位,剩余的42位可以支持4T的内存,如图所示:

· Linux下64位指针的高18位不能用来寻址,所有不能使用;
· Finalizable:表示是否只能通过finalize()方法才能被访问到,其他途径不行;
· Remapped:表示是否进入了重分配集(即被移动过);
· Marked1、Marked0:表示对象的三色标记状态;
· 最后42用来存对象地址,最大支持4T;
三色标记
在并发的可达性分析算法中我们使用三色标记(Tri-color Marking)来标记对象是否被收集器访问过:
· 白色:表示对象尚未被垃圾收集器访问过。显然在可达性分析刚刚开始的阶段,所有的对象都是白色的,若在分析结束的阶段,仍然是白色的对象,即代表不可达。
· 黑色:表示对象已经被垃圾收集器访问过,且这个对象的所有引用都已经扫描过。黑色的对象代表已经扫描过,它是安全存活的,如果有其他对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接(不经过灰色对象)指向某个白色对象。
· 灰色:表示对象已经被垃圾收集器访问过,但这个对象上至少存在一个引用还没有被扫描过。
可达性分析的扫描过程,其实就是一股以灰色为波峰的波纹从黑向白推进的过程,但是在并发的推进过程中会产生“对象消失”的问题,如图:

对象消失理论,只有同时满足才会发生对象消失:
· 赋值器插入了一条或多条从黑色对象到白色对象的新引用;
· 赋值器删除了全部从灰色对象到该白色对象的直接或间接引用;
要解决对象消失问题只需要破坏其中一条就行了,目前常用有两种方案:
· 增量更新(Incremental Update):增量更新要破坏的是第一个条件,当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一次。这可以简化理解为,黑色对象一旦新插入了指向白色对象的引用之后,它就变回灰色对象了。
· 原始快照(Snapshot At TheBeginning,SATB):原始快照要破坏的是第二个条件,当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束之后,再将这些记录过的引用关系中的灰色对象为根,重新扫描一次。这也可以简化理解为,无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照来进行搜索。
以上无论是对引用关系记录的插入还是删除,虚拟机的记录操作都是通过写屏障实现的。CMS是基于增量更新来做并发标记的,G1、Shenandoah则是用原始快照来实现。
染色指针的三大优势
1. 一旦某个Region的存活对象被移走之后,这个Region立即就能够被释放和重用掉,而不必等待整个堆中所有指向该Region的引用都被修正后才能清理,这使得理论上只要还有一个空闲Region,ZGC就能完成收集。而Shenandoah需要等到更新阶段结束才能释放回收集中的Region,如果Region里面对象都存活的时候,需要1:1的空间才能完成收集。
2. 染色指针可以大幅减少在垃圾收集过程中内存屏障的使用数量,ZGC只使用了读屏障。
3. 染色指针具备强大的扩展性,它可以作为一种可扩展的存储结构用来记录更多与对象标记、重定位过程相关的数据,以便日后进一步提高性能。
内存多重映射
ZGC使用了内存多重映射(Multi-Mapping)将多个不同的虚拟内存地址映射到同一个物理内存地址上,这是一种多对一映射,意味着ZGC在虚拟内存中看到的地址空间要比实际的堆内存容量来得更大。把染色指针中的标志位看作是地址的分段符,那只要将这些不同的地址段都映射到同一个物理内存空间,经过多重映射转换后,就可以使用染色指针正常进行寻址了,效果如图:

ZGC的多重映射只是它采用染色指针技术的伴生产物
读屏障
当对象从堆中加载的时候,就会使用到读屏障(Load Barrier)。这里使用读屏障的主要作用就是检查指针上的三色标记位,根据标记位判断出对象是否被移动过,如果没有可以直接访问,如果移动过就需要进行“自愈”(对象访问会变慢,但也只会有一次变慢),当“自愈”完成后,后续访问就不会变慢了。
读写屏障可以理解成对象访问的“AOP”操作
ZGC运作过程
ZGC的运作过程大致可划分为以下四个大的阶段:
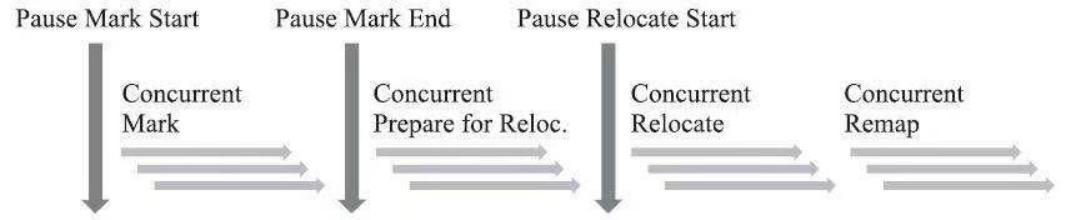
· 并发标记(Concurrent Mark):与G1、Shenandoah一样,并发标记是遍历对象图做可达性分析的阶段,它的初始标记和最终标记也会出现短暂的停顿,整个标记阶段只会更新染色指针中的Marked 0、Marked 1标志位。
· 并发预备重分配(Concurrent Prepare for Relocate):这个阶段需要根据特定的查询条件统计得出本次收集过程要清理哪些Region,将这些Region组成重分配集(Relocation Set)。ZGC每次回收都会扫描所有的Region,用范围更大的扫描成本换取省去G1中记忆集的维护成本。
· 并发重分配(Concurrent Relocate):重分配是ZGC执行过程中的核心阶段,这个过程要把重分配集中的存活对象复制到新的Region上,并为重分配集中的每个Region维护一个转发表(Forward Table),记录从旧对象到新对象的转向关系。ZGC收集器能仅从引用上就明确得知一个对象是否处于重分配集之中,如果用户线程此时并发访问了位于重分配集中的对象,这次访问将会被预置的内存屏障所截获,然后立即根据Region上的转发表记录将访问转发到新复制的对象上,并同时修正更新该引用的值,使其直接指向新对象,ZGC将这种行为称为指针的“自愈”(Self-Healing)能力。
ZGC的染色指针因为“自愈”(Self-Healing)能力,所以只有第一次访问旧对象会变慢,而Shenandoah的Brooks转发指针是每次都会变慢。 一旦重分配集中某个Region的存活对象都复制完毕后,这个Region就可以立即释放用于新对象的分配,但是转发表还得留着不能释放掉,因为可能还有访问在使用这个转发表。
· 并发重映射(Concurrent Remap):重映射所做的就是修正整个堆中指向重分配集中旧对象的所有引用,但是ZGC中对象引用存在“自愈”功能,所以这个重映射操作并不是很迫切。ZGC很巧妙地把并发重映射阶段要做的工作,合并到了下一次垃圾收集循环中的并发标记阶段里去完成,反正它们都是要遍历所有对象的,这样合并就节省了一次遍历对象图的开销。
ZGC存在的问题
ZGC最大的问题是浮动垃圾。
浮动垃圾
ZGC的停顿时间是在10ms以下,但是ZGC的执行时间还是远远大于这个时间的。假如ZGC全过程需要执行10分钟,在这个期间由于对象分配速率很高,将创建大量的新对象,这些对象很难进入当次GC,所以只能在下次GC的时候进行回收,这些只能等到下次GC才能回收的对象就是浮动垃圾。
ZGC没有分代概念,每次都需要进行全堆扫描,导致一些“朝生夕死”的对象没能及时的被回收。
解决方案
目前唯一的办法是增大堆的容量,使得程序得到更多的喘息时间,但是这个也是一个治标不治本的方案。如果需要从根本上解决这个问题,还是需要引入分代收集,让新生对象都在一个专门的区域中创建,然后专门针对这个区域进行更频繁、更快的收集。
官方测试数据
停顿时间
在ZGC的停顿时间测试上,和其他收集器相比完全不在一个数量级,如图:

吞吐量
ZGC的“弱项”吞吐量方面,以低延迟为首要目标的ZGC已经达到了以高吞吐量为目标Parallel Scavenge的99%,直接超越了G1,如图:

优缺点
· 优点:低停顿,高吞吐量,ZGC收集过程中额外耗费的内存小
· 缺点:浮动垃圾
以上就是我对ZGC的理解,有不足的地方希望大家指出,喜欢的朋友欢迎转发关注支持












