
博客搬家啦,更多干货 https://blog.csdn.net/qq_2816...
Redis 单线程为什么还能这么快?
因为它所有的数据都在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性 能损耗问题。
Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到 文件事件分派器,事件分派器将事件分发给事件处理器。
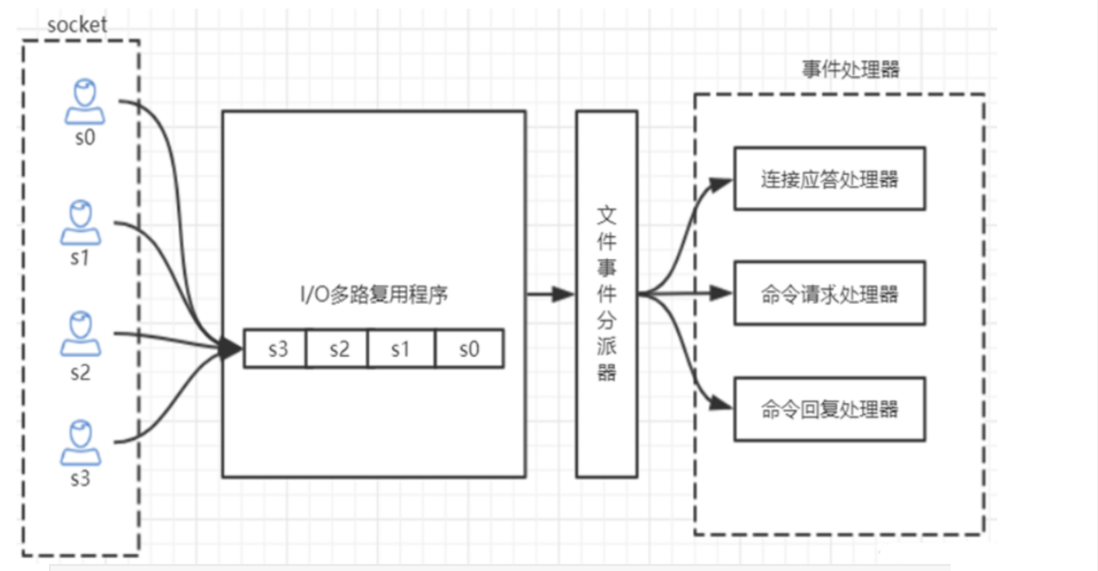
其实对于redis来讲,无论多少并发,到了redis层都会排队,一个一个的来处理
Info: 查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
Server 服务器运行的环境参数
Clients 客户端相关信息
Memory 服务器运行内存统计数据
Persistence 持久化信息
Stats 通用统计数据
Replication 主从复制相关信息 CPU CPU 使用情况
Cluster 集群信息
KeySpace 键值对统计数量信息
缓存穿透
缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑, 如果从存储 层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。
- 解决:可以将空对象缓存起来或者设置一个特殊意义的字符串来标示此记录数据库中不存在,直接在缓存层返回
- 布隆过滤器 对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不 存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可 能不存在;当它说不存在时,那就肯定不存在。
缓存失效
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大 甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同 时间。
int expireTime = new Random().nextInt(300) + 300;
bigkey
bigkey的坏处:
- 带宽固定,千兆网卡(按照字节来算是 128M/s),假设一个key的value大小为1M,有1000个连接并发,1s所占用的带宽就是1000M,会造成网络堵塞。
- redis堵塞,单线程处理bigkey有可能造成其他连接排队
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存 储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
- 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
- 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000(超过5000了可以采用分拆思想)
过期键清除策略
Redis对于过期键有三种清除策略:
- 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key)
- 当前已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略又分五种
- allkeys-lru:根据LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间 为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random: 随机删除过期键,直到腾出足够空间为止。
- volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据。如果没有,回退到noeviction策略。 (常用)
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error)OOM command not allowed when used memory",此时Redis只响应读操作。











