
mit 分布式论文集 https://github.com/feixiao/Distributed-Systems
raft 和 zab 是类似的,都是1.先选举,2.然后再对客户端的消息进行投票. 其实是 simple paxos 的一种变化.
和 原生paxos 的区别在于: 选举的阶段其实是 prepare 的阶段. 选举允许多个主出现.
1. 读原文
paxos-simple-Copy [ https://www.microsoft.com/en-us/research/wp-content/uploads/2016/12/paxos-simple-Copy.pdf ]
读译文
悟出一点和zk的区别.
文献例子中:
- leader可以两个, 所有投票还是两阶段. prepare预锁[预锁是最好的理解方式]+ 提交 所以在fast paxos中再次强调不关心leader如何选举[The Progress Property 一节中,i will not discuss how to select leader]. 在此文中有提及方法,timeout.[paxos-simple-Copy原文Progress 一节末尾]
- 顺序性有序号保证,接受不一定立即执行. 故没有135 ,就不能执行149. 可以先设置一个nop
- 可以批量决议议题,第x-x+10个命令,是否采用对应的命令.
- instance 就是没个决议. 笔者注:instance可以细化到到单个账户的投票上,对应着zk为各个路径.增加并发能力.
zk和raft中leader的作用:
1. 作为所有paxos instance的prepare阶段. [phil注: 一般人悟不到这点]
2. 统筹所有的请求,方便进行并发控制
3. 选择日志最多的节点,能够快速从失败中恢复.
zk和raft中leader是否可能有多个?
zk:
可能的. 虽然zk在得到半数同意后, 再等待了finalizeWait = 200ms, 远小心节点之间心跳超时时间. 也避免不了leader被抢走的尴尬. 案例说明: 共5台机器, 比如 1,2,3 都选择了1. 1 变成leader 然后2 还没得到3的通知, 此时5发出请求,得到了2,3,4,5的同意.
raft:
选自己,然后通知所有人. 各自等待. 先唤醒的再选择自己,通知所有人.
zk:
和raft共同点:
- 有选举轮次,来源于simple paxos 的prepare的概念
- 都是选自己,通知所有人.
和raft不同点:
- 对返回的结果不理睬,直接睡眠 [4]
- leader排他,有效的只能是一个.
- 顺序性有命令队列保证.
- 接受了立即执行
- 日志不是顺序的
- 加入新节点会阻塞 [1]
- 更换leader会阻塞 [1]
http://blog.csdn.net/xhh198781/article/details/10949697 前半部分是对simple faxos的很好总结.
raft:
和zk共同点:
- 有选举轮次,来源于simple paxos 的prepare的概念
和raft不同点:
对返回的结果理睬.
日志是连续的 [1] [3]
加入新节点不阻塞
- 其他区别见下图[6]
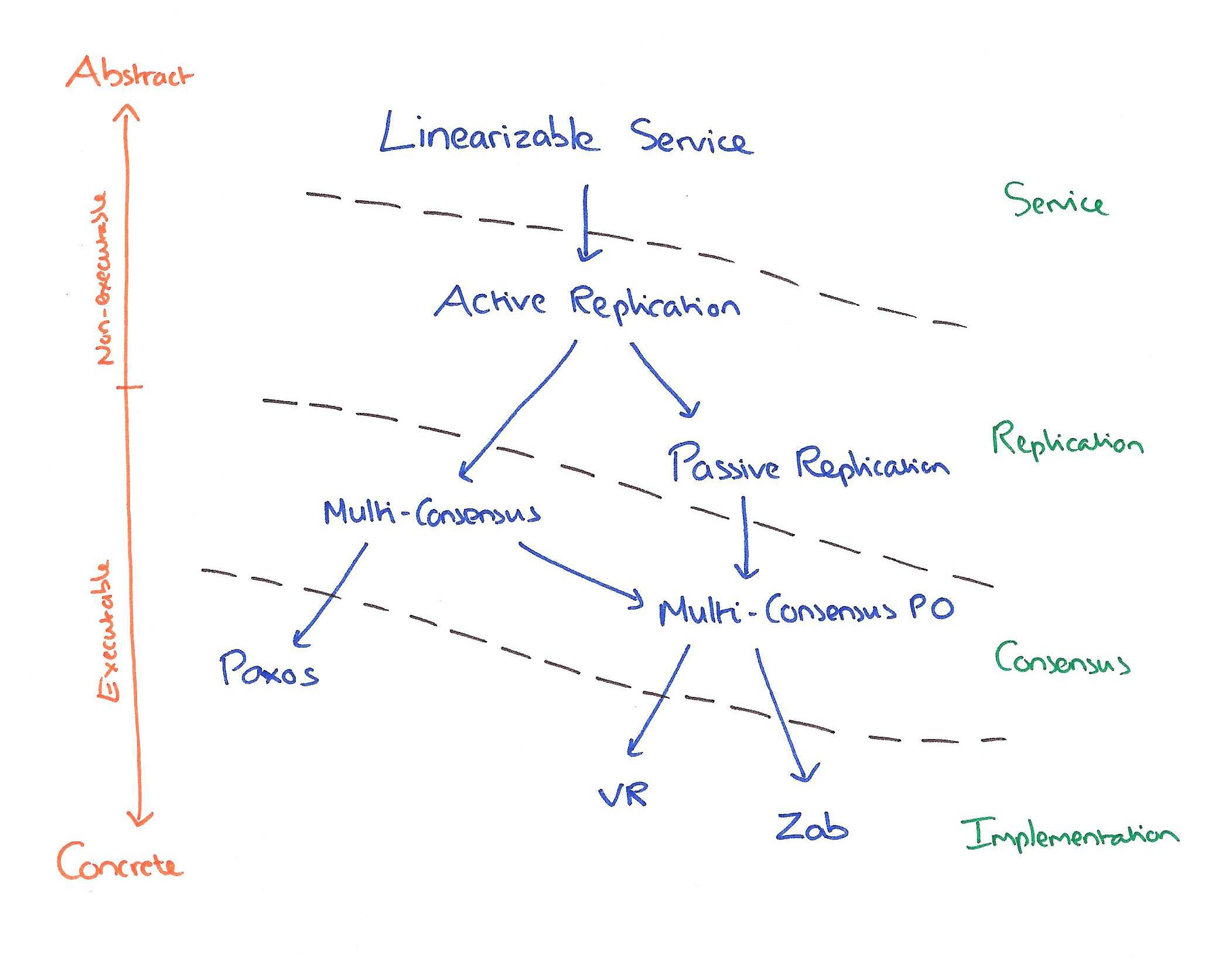
笔者注解: 之前的可靠性都是
1. 通过备份,切换的方式. 对应的监听切换器又需要热备. 热备无穷尽也.
2. 客户端多ip 适用于无状态服务器.
paxos的选举机制很好的解决了这个问题.3台机器即可. 客户端配置x个ip.
paxos之Multi-Paxos 这个没找到原文献. 和simple中思想差别较大.但是和zk区别较大,见[2]
“Leslie Lamport也是用了长达9年的时间来完善这个算法的理论”–
这个故事其实是这样的:
Lamport大牛在他Paxos的第一个版本早在1990年就提交给ACM TOCS Jnl.的评审委员会了 但是当时没有人理解他的算法 主编回执他的稿子建议他用数学而不是神话描述他的算法 他们才会考虑接受这篇paper
Lamport大牛很生气 他有次就在一个会议上说:”为什么搞理论的这群人一点幽默感也没有呢?” 他拒绝修改 而且withdraw了这篇文章
1996年微软的Butler Lampson在WDAG96上提出了重新审视这篇文章 因为他读懂了
1997年MIT的Nancy Lynch在WDAG97上 根据原文重新改写了这篇文章 叫做 在本文中她们”代替”Lamport用数学形式化的定义并证明了Paxos
于是在1998年的ACM TOCS上 这篇迟到了9年的paper终于被接受了
后来2001年 Lamport大牛也作出了让步 他用简单的语言而不是神话故事 重述了原文 这就是 但是通篇还是没有数学符号 L大牛甚为固执 据他自己说 他检查过了自己的语言并没有歧义 不需要数学来描述
Paxos可以说是Theory of CS领域被流传最广泛的一则趣事~
- 实现:
phxsql)是腾讯开源的mysql主备集群多副本管理系统,除了mysql源码之外,还包含了一系列外部的组件(phxsqlproxy、phxbinlogsvr)和内部插件(phxsync),借助paxos协议,实现了主备数据的强一致。
阿里云企业三节点版本,在alisql内核中引入raft协议,不借助任何外部依赖,通过mysqld自身的简单配置,实现整个集群的构建,架构简单、实现优雅。
分布式基础通信协议:paxos,totem和gossip canssandra.
核心是对应的画图能力,模块分解能力. 数据流图.
别人的文章 图解zookeeper FastLeader选举算法. 要学会画无职责的流程图(含循环+ 节点批注). 然后再理解模块,带上职责. 甚至是角色.
http://blog.csdn.net/zhxdick/article/details/50886638
[1] Raft对比ZAB协议 总结了两个经典区别: 1. 日志的连续性问题 2.加入过程是否阻塞整个请求 .具体详见文献3
[2] Multi Paxos http://www.cnblogs.com/fei33423/p/7990190.html wiki上也有,但是没有对应的文献.
[3] Raft算法赏析 核心: 当前term的leader不能“直接”提交之前term的entries . 导致了日志是连续的
有一张例子图 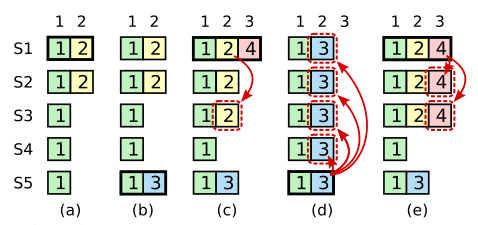
[5] 很有深度的文章 分布式系统理论进阶 - Raft、Zab
[6] Vive La Difference: Paxos vs. Viewstamped Replication vs. Zab, Robbert van Renesse, Nicolas Schiper and Fred B. Schneider, 2014
个人渣记录,仅搜索用






