Python_爬虫_笔记
1.前言
1.1爬虫用途:
网站采集、接口采集(地图(jis 热力学 屋里端口/协议)、微信、知乎、)
1.2基本流程:网页下载(requests)+网页解析+爬虫调度
网页解析:在当前网站找信息、下一个入口等信息
调度:调度器/队列(先进先出、谁快谁先...)
1.3Python爬虫库 urllib、bs4/beautiful_soup、lxml/XPath、scripy
学习顺序:urllib→bs4/beautiful_soup→lxml/XPath→scripy
注:lxml/XPath 是指lxml下的Xpth库;具体用法会在下面部分详述
1.4反爬虫 和 反反爬虫 原理
反爬虫原理:检查request的(user-agent[识别爬虫]、Host、refer[来源,防盗链])、js异步加载、其他机制
反反爬虫:控制爬取节奏(time.sleep())、伪装头信息(user-agent、Host、refer)、伪装IP(代理池)、伪装cookie
1.5用到的知识点:
- web前端(css选择器、JS渲染规则)选择器;ajax异步加载、HTTP协议、Python进程线程等
-JSON的序列化dumps()和反序列化loads()
对付(HTTPs的)ssl安全套接层协议
HTTPs 有验证,处理办法:
1.引入ssl躲避 2.设置取消验证
2.IP代理、代理池维护【待完善】
url自带
1.调用urllib.request.ProxyHandler(proxies=None) 代理矩柄
2.创建Opener(类似urlopen)
3.安装Opener
代理IP
透明Ip 附加真实IP(用途少),有的直接就是不生效
高密IP 隐藏自身IP
- cookie-urllib的cookie很复杂,到scrapy上再看
3.网页请求 与 网页解析
3.1 request请求
注:Python最最常用的请求库 - request,其他的可以忽略
#request请求案例(简版):
import request
req = request.urlopen("url地址").read().decode('编码格式')
#request请求案例(标准版)-注:标准请求要加入表头信息
qingqiutou = request.Request(url=url,headers=headers,method="GET")
res=request.urlopen(qingqiutou).read().decode('utf-8')
3.2页面解析库【重要!!!】
3.2.1 re模块,Python自带的正则解析库;最基础最不好用的解析库
注:最原始的办法是re模块正则解析,目前只用正则来处理不遵守结构化DOM(Document Object Model)树规范的页面
用法案例:略
3.2.2 Urllib模块
常见问题:
urllib.request 请求模块,打开和读取URLs
urllib.error 异常处理模块 分为:HTTPerror、urlerror
注:HTTPError在URLError之前,因为HTTPError是URLError的子类,若URLError在前报错会覆盖HTTPError
urllib.parse url解析模块
urllib.robotparser robots.txt 解析模块【少,基本不用】
print(response.getcode()) #打印出状态码
f.getcode() 等同于 f.status 获取状态码
f.getheaders() 等同于 f.info() 获取表头
用法案例:略
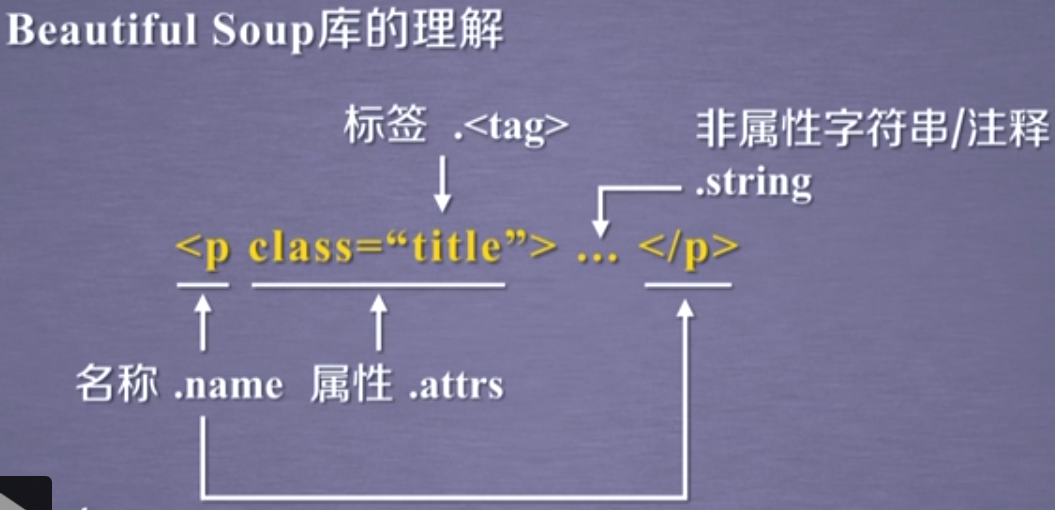
3.2.3 bs4解析库【form bs4 import beautiful soup】
主要用于网页数据解析,根据标签机结构化解析
find_all find
节点选取: 子节点、父节点、兄弟节点
bs4库能格式化html数据
包含4大(bs4)对象
1.Tag 标签 例如:supe.title 能表示标题,默认第一个【包含NavigableString、Comment】
2.NavigableString 例如:print(soup.p.string) 输出p标签里的内容【包含Comment】
3.BeautifulSoup 是一个特殊的tag对象 能提取name、attr等属性
4.Comment 能提取注释内容
bs4库的4个解析器
1、 Python标准库【主要,系统自带;】
使用方法: BeautifulSoup(markup,"html.parser")【注:markup是html文档】 Python的内置标准库
案例 from bs4 import BeautifulSoup soup = BeautifulSoup.(html,'html.parser') print(soup.title.string)
2、 lxmlHTML解析器
BeautifulSoup(markup,"lxml") 速度快、需要安装C语言库
3、 lxml XML解析器
使用方法:BeautifulSoup(markup,"xml") 速度快,唯一支持XML的解析器、需要安装C语言库
4、 html5lib
BeautifulSoup(markup,"html5lib") 容错性好,以浏览器的形式解析文档,生成html5格式的文档,但是速度慢
3.2.4 lxml.XPath解析库 可以代替re的lxml解析库
XML Path Language是一个小型的查询语言,根据DOM树路径一层层查找
from lxml import etree
select = etree.HTML(html代码) #格式化
selector.xpath(表达式) #返回为一列表
XPath四种标签:【注:唯一一个编号是从0开始的】
1. // 根路径,会全局扫描,取得内容后以列表的形式返回
2. / 路径 找当前或下一级内容
3. text() 获取当前路径下的文本内容;例:text(2) 取第二个
4. /@xxx 属性标签 获得当前路径下的属性值(取href值) 案例:/div[@classs="shuxing1"]/...
5. | 分割符 同时取多个路径
6. . 点 取当前节点
7. .. 两个点 取当前节点的父节点
Tips: 集合 content = set(content1) #集合可以去重,当做键