

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

SparkSQL逻辑计划概述
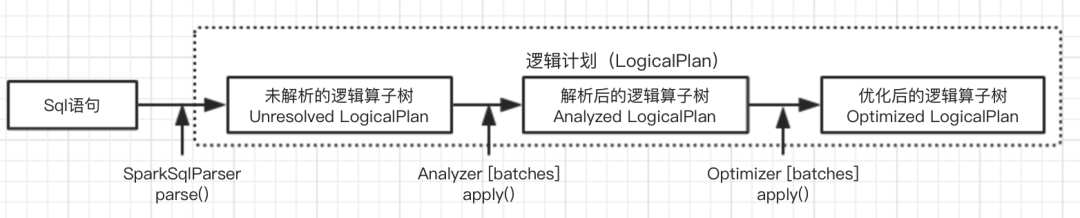
逻辑计划阶段被定义为LogicalPlan类,主要有三个阶段:
由SparkSqlParser中的AstBuilder将语法树的各个节点转换为对应LogicalPlan节点,组成未解析的逻辑算子树,不包含数据信息与列信息
由Analyzer将一系列规则作用在未解析逻辑算子树上,生成解析后的逻辑算子树
有Optimizer将一系列优化规则应用在逻辑算子树中,确保结果正确的前提下改进低效结构,生成优化后的逻辑算子树
LogicalPlan简介
概述
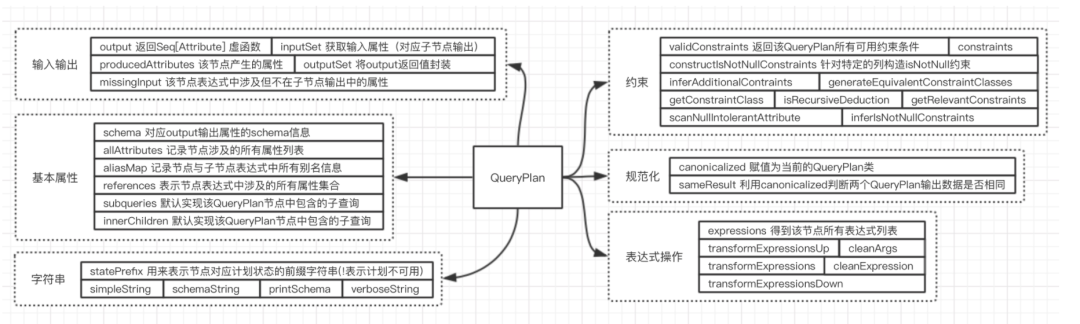
LogicalPlan的父类QueryPlan主要分为六个模块:
– 输入输出 涉及QueryPlan内属性相关的输入输出
– 基本属性 QueryPlan内的基本属性
– 字符串 主要用于打印QueryPlan的树形结构信息
– 规范化 类似Expression中的规范化
– 表达式操作
– 约束 本质上也是数据过滤条件的一种,同样是表达式类型。通过显式的过滤条件推导约束
基本操作和分类
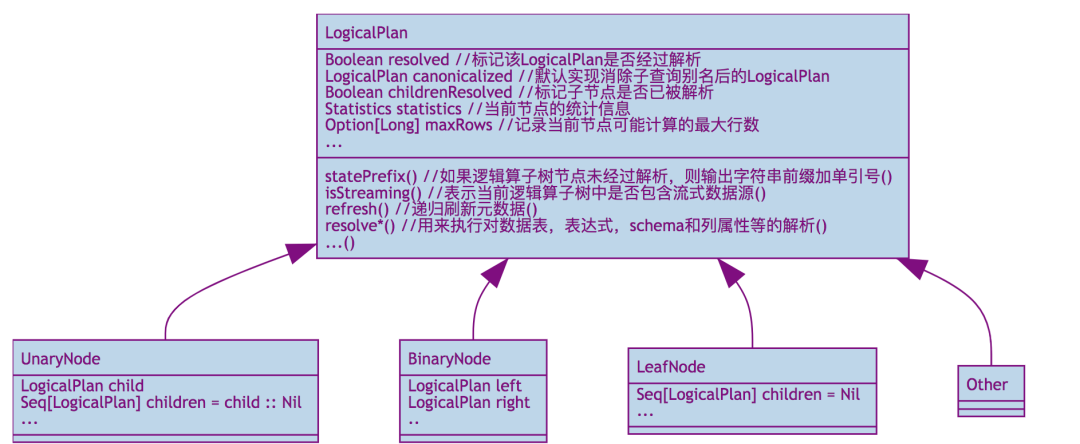
LeafNode 主要对应数据表和命令相关逻辑。
RunnableCommand 直接运行的命令 包括相关Database相关,Table相关,View相关,DDL相关,Function和Resource相关命令
UnaryNode 常见与对数据的逻辑转换操作,如过滤等
用来重定义分区操作(RedistributeData) 主要针对现有分区和排序的特定不满足的场景
脚本相关的转换操作(ScriptTransformation) 用特定脚本对输入数据进行转换
Object相关操作(ObjectConsumer)
常见操作算子(basicLogicalOperators) 涉及Project,Filter,Sort等各种常见关系算子
BinaryNode 常见于对数据的组合关联操作
连接(Join)
集合
CoGroup
其他类型
Union 是一系列LoginPlan列表
ObjectProducer 用于产生只包含Object列的行数据
EventTimeWatermark 针对Spark Streaming中的水印机制
AstBuilder机制:Unresolved LogicalPlan生成
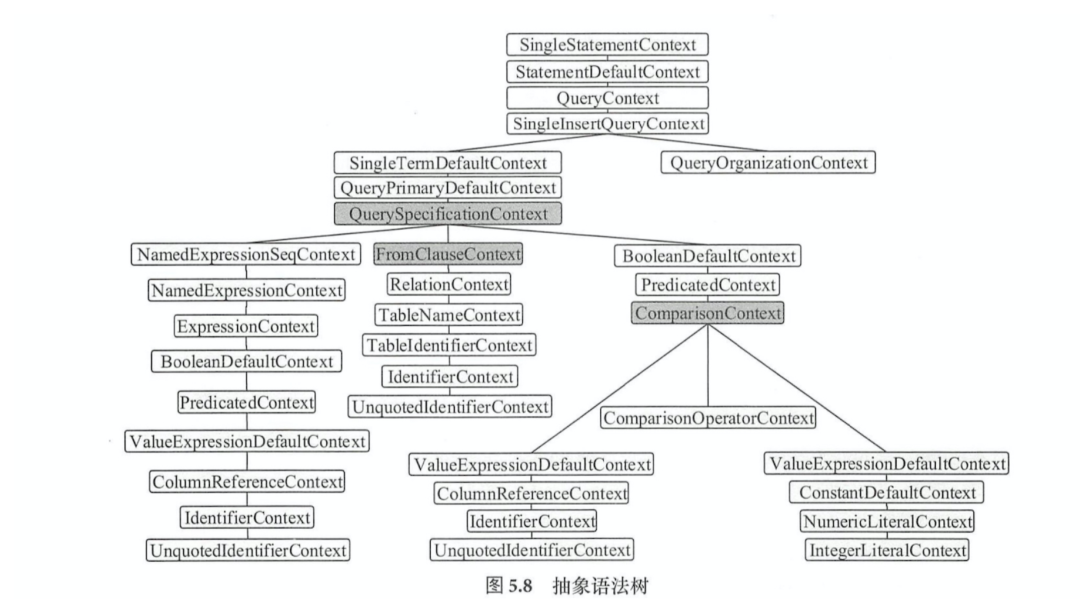
从visitSingleStatement为入口从根部递归访问整棵树,当访问到某个子节点可以构造LogicalPlan时,然后传递到父节点;执行到QuerySpecificationContext时,首先访问FromClauseContext子树,生成from的LogicalPlan,然后调用withQuerySpecification在from的基础上完成扩展
从访问QuerySpecificationContext开始,主要分为以下三个步骤
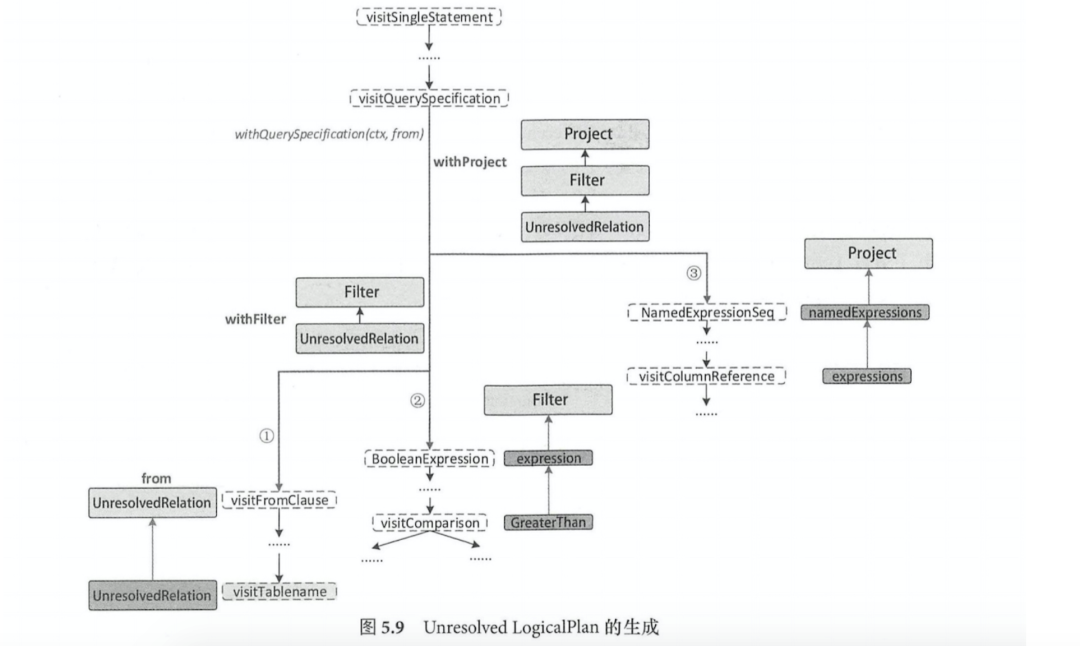
生成数据表对应的LogicalPlan:访问FromClauseContext直到匹配TableNameContext节点时,根据其中的数据信息生成UnresolvedRelation,并跳出递归,构造名为from的LogicalPlan
生成加入了过滤逻辑的LogicalPlan:对BooleanDefaultContext进行递归,生成对应的expression并返回作为过滤条件,然后基于此生成Filter LogicalPlanjiedian ,并与(1)中的UnresolvedRelation构造withFilter的LogicalPlan
生成加入列剪裁后的LogicalPlan:获取QuerySpecificationContext节点所包含的NamedExpressionSeqContext成员,并对其所有子节点表达式进行转换,生成NameExpression列表,然后生成Project LogicalPlan,并与(2)中的withFilter构造withProject的LogicalPlan
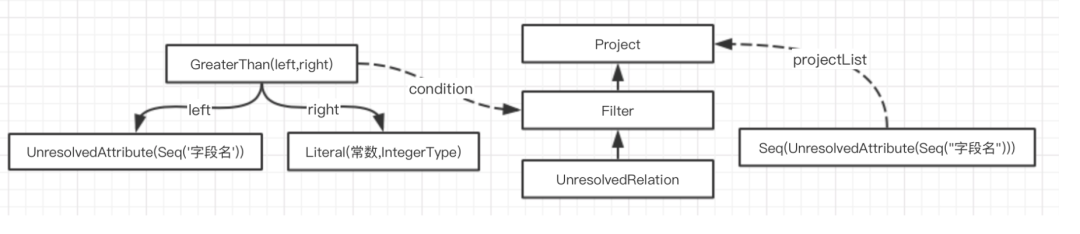
Analyzed LogicalPlan生成
Sql经过AstBuilder的处理得到的 未解析逻辑算子树 主要由UnresolvedRelation 和UnresolvedAttribute两个对象组成。Analyzer主要作用就是将这两种对象or表达式解析为有类型的对象
Catalog体系分析
Catalog通常理解为一个容器或数据库命名空间中的一个层次,在Spark中主要用于各种函数资源和元数据的统一管理。
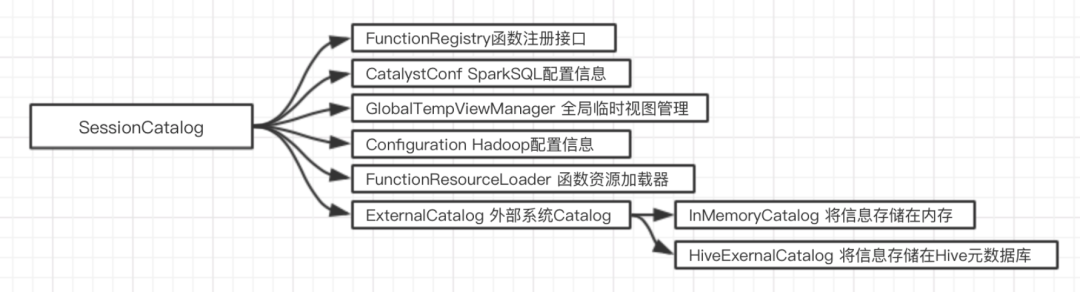
GlobalTempViewManager 是线程安全类,进行跨Session的视图管理,提供对全局视图的增删改查等,主要依赖一个mutable类型的HashMap来对视图名和数据源进行映射
FunctionResourceLoader 用来加载用户自定义函数和Hive中的各种函数(以Jar包或文件类型提供)
FunctionRegistry 用来实现函数注册,查找和删除功能。采用Map结构注册
ExternalCatalog 用来管理数据库,数据表,分区和函数的接口,目标是与外部系统交互并做到上述内容的非临时存储
Catalog内部还包括一个mutable类型的HashMap来管理临时表信息,以及currentDb成员来指代当前操作对应的数据库名(use db; )
Rule体系
对逻辑算子树的操作(绑定,解析,优化等)主要都是基于规则的,通过Scala的语言模式匹配进行树结构转换或节点改写。由RuleExecutor来调用规则,所有涉及树形结构转换过程的都继承自RuleExecutor[TreeType] 抽象类。
RuleExecutor内部提供一个Seq[Batch]定义了改RuleExecutor的处理步骤,每个Batch代表一套规则;RuleExecutor.apply(TreeType plan)会按照batches和batches内Rule的顺序对传入的plan内的节点进行迭代处理
Analyzed LogicalPlan生成过程
Analyzer执行过程会调用ReluExecutor实现的run方法,默认定义了6个Batch(Spark2.1):
Batch Substitution 节点替换操作
CTESubstitution 对应With语句,主要用于SQL子查询模块化,将多个LogicalPlan合并成一个
WindowsSubstitution 匹配WithWindowDefinition表达式,将未解析的窗口表达式转换成窗口函数表达式
EliminateUnions 当Union算子节点只有一个子节点时,将Union替换为children.head节点
SubstituteUnresolvedOrdinals 用于支持Spark2.0开始支持的使用常数来表示列下表的特性,将下表替换为UnresolvedOrdinal表达式
BatchResolution 最常用的解析规则,包含了数据源,数据类型等操作。
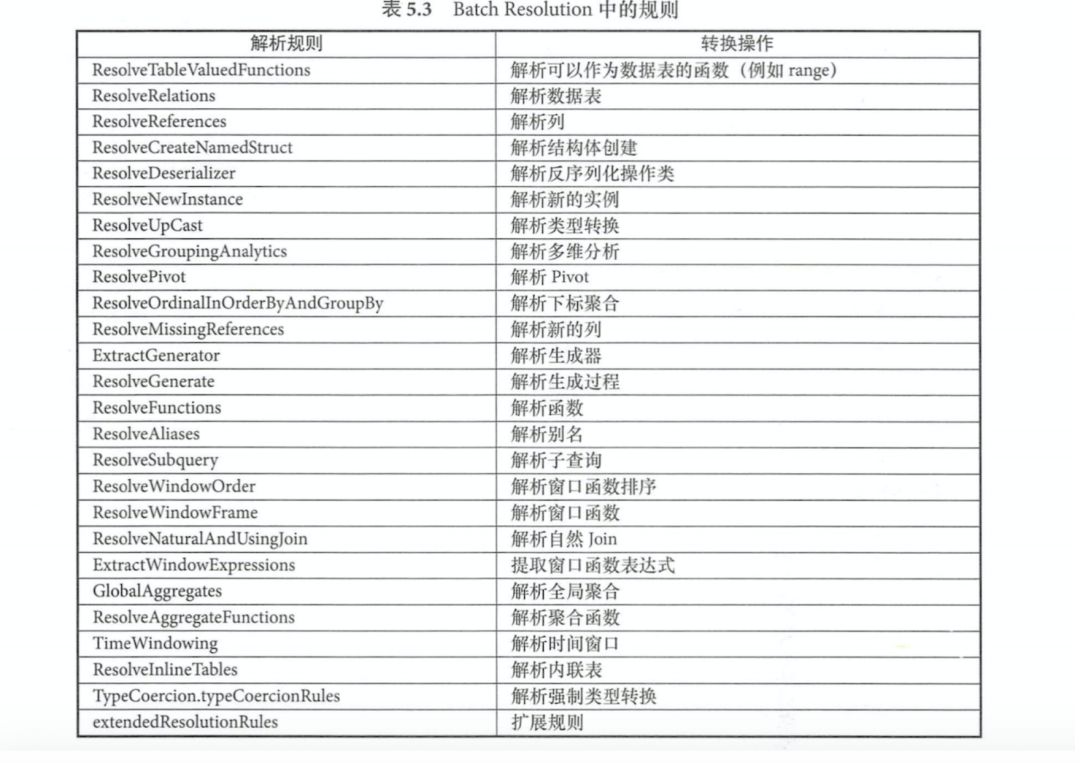
Batch Nondeterministic => PullOutNondeterministic
将LogicalPlan中非Project和非Filter 的不确定表达式提取出来,然后放到内层或最终的Project算子中Batch UDF => HandleNullInputsForUDF
对用户自定义函数进行一定处理,HandleNullInputsForUDF用来处理输入数据为Null的情况,自上而下遍历表达式,匹配到ScalaUDF类型表达式时,会创建IF表达式进行Null的检查Batch FixNullability => FixNullability
用来统一设定LogicalPlan中表达式的nullable属性Batch Cleanup => CleanupAliases
用来删除LogicalPlan中无用的别名信息
Analuzed LogicalPlan详细步骤
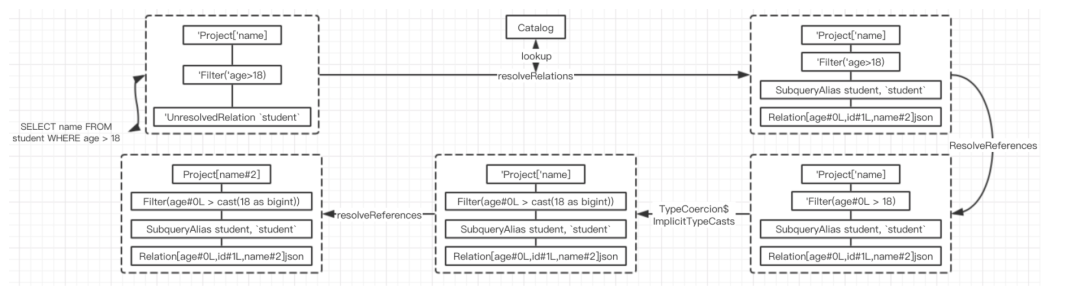
匹配ResolveRelations规则,从SessionCatalog中查表,并获取分析后的LogicalPlan,并插入一个别名节点
分析Filter节点中的age信息,但由于常数18还未经分析,因此Filter节点依旧是未分析状态(以单引号开头)
对表达式中的数据类型进行隐式转换,将18转换为bigint类型,此时Filter节点依旧是已分析状态
再次匹配ResolveReferences规则,对Project节点中的进行name解析,此时整个Analyzed LogicalPlan就生成了
优化器Optimizer
Analyzed LogicalPlan基本是未解析的逻辑算子树一对一转换来的,存在很多低效的写法,需要进行优化
优化器概述&规则体系
与Analyzed类似,Optimizer也主要依赖一系列规则,并在RuleExecutor执行execute方法是利用这些规则Batch。
SparkOptimizer中共实现了16个Batch(Spark2.1):
Batch Finish Analysis 更多是为了得到正确的结果而不是优化
EliminateSubqueryAliases 消除子查询别名,对应SubqueryAlias节点
ReplaceExpression 表达式替换,替换RuntimeReplaceable的表达式,通常用来对其他类型数据库的支持
ComputeCurrentTime 计算一次时间函数表达式,并将其他相同的函数替换成计算结果
GetCurrentDatabase 执行CurrentDatabase并获得结果,替换所有获取数据库的表达式
RewriteDistinctAggregates 重写Distinct聚合,将其转换为两个常规聚合表达式
BatchUnion => CombineUnions
当相邻节点都是Union算子时,合并为一个Union节点Batch Subquery => OptimizeSubqueries
当SQL语句包含子查询时,在逻辑算子树上遇到SubqueryExpression表达式会进一步递归调用Optimizer对子查询计划进行优化BatchReplaceOperator 主要执行算子(集合类型的操作算子)的替换操作,避免进行重复的逻辑转换
ReplaceIntersectWithSemiJoin 将Intersect算子替换为Left-Semi Join算子,两者逻辑上是等价的
ReplaceExceptWithAntiJoin 将Except算子替换为Left-Anti Join算子
ReplaceDistinctWithAggregate 将distinct转换为Aggregate语句,将Select distinct转换为Groupby
Batch Aggregate 处理集合算子中的逻辑
RemoveLiteralFromGroupExpression 删除GroupBy中的常数,如果全是常数则替换为0
RemoveRepetitionFromGroupExpression 删除重复的Groupby表达式
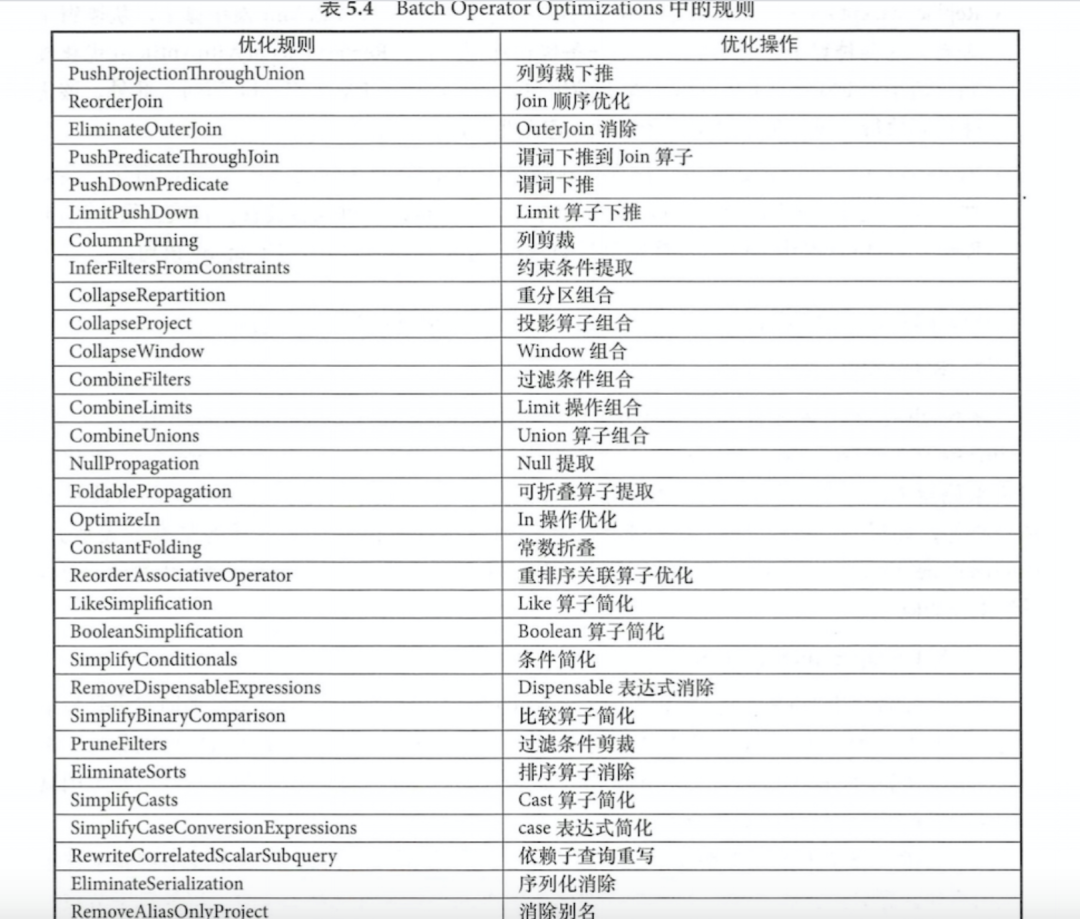
Batch Operator Optimizations 包含了最多最常用(31)的各种优化规则,分为以下几类
算子下推:将上层的算子下推,减少后续处理的数据量
算子结合:将能组合的算子尽量组合,避免多次计算
常量折叠和长度削减:对涉及常量的节点在执行前就完成运算
BatchCheckCartesianProducts => CheckCartesianProducts
监测算子树中是否有笛卡尔积,如果没有用crossJoin显式使用,则抛出异常(除非’spark.sql.crossJoin.enable’设置为true)BatchDecinalOptimizations => DecimalAggregates
用于处理跟Decimal类型相关的问题,如精度固定等BatchTypedFilterOptimization => CombineTypedFilters
对特定情况下的过滤条件进行合并BatchLocalRelation 优化与LocalRelation相关的逻辑算子树
ConvertToLocalRelation 将LocalRelation上的本地操作转换为另一个LocalRelation
PropagateEmptyRelation 将包含空的LocalRelation进行折叠
BatchOptimizeCodegen => OptimizeCodegen
对生成的代码进行优化,主要针对case when语句BatchRewriteSubquery 主要优化子查询
RewritePredicateSubquery 将特定子查询为此逻辑转换为left-semi/anti joincaozuo
CollapseProject 将两个相邻的Project算子结合并进行别名替换
BatchOptimizeMetadataOnlyQuery => OptimizeMetadataOnlyQuery
用来优化只需查找分区级别元数据的语句,要求扫描的所有列都是分区列且包含聚合算子(表达式是分区列or有Distinct算子or有无Distinct算子不影响结果)BatchExtractPythonUDFfromAggregate => ExtractPythonUDFFromAggregate
用来提取出聚合操作中的Python UDF函数,在聚合完成后再执行BatchPruneFileSourceTablePartitions => PruneFileSourcePartitions
对数据文件中的分区进行剪裁操作,并尽可能把过滤算子下推到存储层BatchUserProvidedOptimizers => ExperimentalMethods.extraOptimizations
用于满足用户自定义优化规则
Optimized LogicalPlan的生成过程
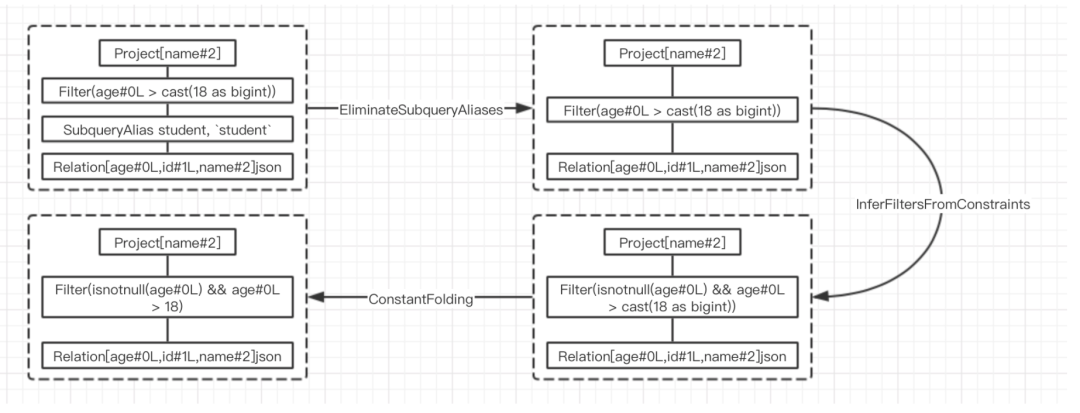
直接删除无用的SubqueryAlias节点,Filter直接作用于Relation
对过滤节点进行分析,添加非空约束(来自Filter中的约束信息)
对可以折叠的表达式直接进行静态计算,并用结果替换表达式(直接执行类型转换)
最终优化后的逻辑算子树会作为生成物理算子树过程的输入,进入下一个阶段。
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











