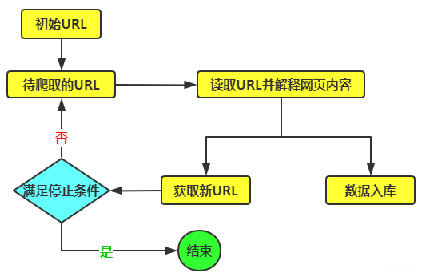
随着互联网的发展和数据量的不断增加,网络爬虫已经成为了一项非常重要的工作。爬虫技术可以帮助人们自动地从互联网上获取大量数据,并且这些数据可以应用于各种领域,如搜索引擎、数据分析和预测等。然而,在实际应用中,我们面临的一大难题就是如何高效地爬取大量数据。分布式爬虫和高并发技术的出现,为解决这个难题带来了新的解决方案。 比如我们在实际爬虫过程中如何通过分布式爬虫和高并发来实现电商平台拼多多的数据爬取。首先是分布式爬虫的使用,分布式爬虫是指将一个爬虫任务分成多个子任务,并分配到多个计算机节点上进行并行处理的一种爬虫技术。它可以大幅提高爬虫的效率和速度,同时降低单个节点的负载和风险。它最大优势在于可以通过多台计算机同时进行任务处理,从而实现高效、快速地爬取大量数据的目标。同时,分布式爬虫还可以通过多个节点相互协作,避免单点故障,提高爬虫的可靠性和稳定性。 高并发之分布式爬虫的意思是,指通过分布式爬虫技术实现高并发的爬虫框架。它可以帮助人们快速地获取大量的数据,并且可以支持高并发的数据请求,爬虫框架的选择有很多,这里重点介绍下Scrapy-Redis 。是基于 Scrapy 框架的分布式爬虫框架。它通过 Redis 数据库实现任务分发和结果合并,可以支持多个爬虫节点同时工作,从而实现高并发的爬虫任务。电商网站的反爬都是比较严的,各种反爬方式都是以难度最大优先。比如对IP的限制,爬取的时候需要使用高质量的IP辅助才能成功爬取数据,高质量IP的选择并不是很多,通过多次测试对比,亿牛云提供的代理产品是最优的选择,因为他们IP池足够大,能够支持很多大并发的爬取场景需求。这里我们可以通过他们提供的爬虫代理加强版IP池,通过分布式爬虫和高并发的代理的辅助来实现拼多多数据的爬取,实现过程如下:
import base64
import sys
import random
PY3 = sys.version_info[0] >= 3
def base64ify(bytes_or_str):
if PY3 and isinstance(bytes_or_str, str):
input_bytes = bytes_or_str.encode('utf8')
else:
input_bytes = bytes_or_str
output_bytes = base64.urlsafe_b64encode(input_bytes)
if PY3:
return output_bytes.decode('ascii')
else:
return output_bytes
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "SRWFDQW"
proxyPass = "548764"
# [版本>=2.6.2](https://docs.scrapy.org/en/latest/news.html?highlight=2.6.2#scrapy-2-6-2-2022-07-25)无需添加验证头,会自动在请求头中设置Proxy-Authorization
request.meta['proxy'] = "http://{0}:{1}@{2}:{3}".format(proxyUser,proxyPass,proxyHost,proxyPort)
# 版本<2.6.2 需要手动添加代理验证头
# request.meta['proxy'] = "http://{0}:{1}".format(proxyHost,proxyPort)
# request.headers['Proxy-Authorization'] = 'Basic ' + base64ify(proxyUser + ":" + proxyPass)
# 设置IP切换头(根据需求)
# tunnel = random.randint(1,10000)
# request.headers['Proxy-Tunnel'] = str(tunnel)
# 每次访问后关闭TCP链接,强制每次访问切换IP
request.header['Connection'] = "Close"