
一. Elasticsearch是一个基于Lucene的实时的分布式搜索和分析引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。基于RESTful接口
二. ES中的核心概念
集群(Cluster): ES是一个分布式的搜索引擎,一般由多台物理机组成。这些物理机,通过配置一个相同的cluster name,互相发现,把自己组织成一个集群。
节点(Node):同一个集群中的一个Elasticearch主机。
主分片(Primary shard):索引(下文介绍)的一个物理子集。同一个索引在物理上可以切多个分片,分布到不同的节点上。分片的实现是Lucene 中的索引。
注意:ES中一个索引的分片个数是建立索引时就要指定的,建立后不可再改变。所以开始建一个索引时,就要预计数据规模,将分片的个数分配在一个合理的范围。
副本分片(Replica shard):每个主分片可以有一个或者多个副本,个数是用户自己配置的。ES会尽量将同一索引的不同分片分布到不同的节点上,提高容错性。对一个索引,只要不是所有shards所在的机器都挂了,就还能用。
索引(Index):逻辑概念,一个可检索的文档对象的集合。类似与DB中的database概念。同一个集群中可建立多个索引。比如,生产环境常见的一种方法,对每个月产生的数据建索引,以保证单个索引的量级可控。
类型(Type):索引的下一级概念,大概相当于数据库中的table。同一个索引里可以包含多个 Type。
文档(Document):即搜索引擎中的文档概念,也是ES中一个可以被检索的基本单位,相当于数据库中的row,一条记录。
字段(Field):相当于数据库中的column。ES中,每个文档,其实是以json形式存储的。而一个文档可以被视为多个字段的集合。比如一篇文章,可能包括了主题、摘要、正文、作者、时间等信息,每个信息都是一个字段,最后被整合成一个json串,落地到磁盘。
映射(Mapping):相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以不显示地指定、自动根据文档数据创建。
Elasticsearch集群可以包含多个索引(indices),每一个索引可以包含多个类型(types),每一个类型包含多个文档(documents),然后每个文档包含多个字段(Fields),这种面向文档型的储存,也算是NoSQL的一种吧。
ES比传统关系型数据库,对一些概念上的理解:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
三 .Elasticsearch 的安装及配置
- 零配置,开箱即用
- 没有繁琐的安装配置
- java版本要求:最低1.7
- 下载地址:
- https://www.elastic.co/downloads/past-releases/1-4-4
- 启动
- cd /usr/local/elasticsearch-1.4.4
- ./bin/elasticsearch
- bin/elasticsearch -d(后台运行)
配置文件elasticsearch.yml 集群名和节点名: #cluster.name: elasticsearch #node.name: "node1" 是否参与master选举和是否存储数据 #node.master: true #node.data: true 分片数和副本数 #index.number_of_shards: 5 #index.number_of_replicas: 1
master选举最少的节点数,这个一定要设置为整个集群节点个数的一半加1,即N/2+1
#discovery.zen.minimum_master_nodes: 1
discovery ping的超时时间,拥塞网络,网络状态不佳的情况下设置高一点
#discovery.zen.ping.timeout: 3s
注意,分布式系统整个集群节点个数N要为奇数个!!
如何避免ElasticSearch发生脑裂(brain split):http://blog.trifork.com/2013/10/24/how-to-avoid-the-split-brain-problem-in-elasticsearch/
即使集群节点个数为奇数,minimum_master_nodes为整个集群节点个数一半加1,也难以避免脑裂的发生,详情看讨论:https://github.com/elastic/elasticsearch/issues/2488
四. ElasticSearch之初体验
在正式使用之前,最好安装个web图形界面的插件,我们使用比较流行的head插件,安装步骤如下: /elasticsearch-1.7.1/bin/plugin -install mobz/elasticsearch-head ,安装完毕后的页面显示如下:
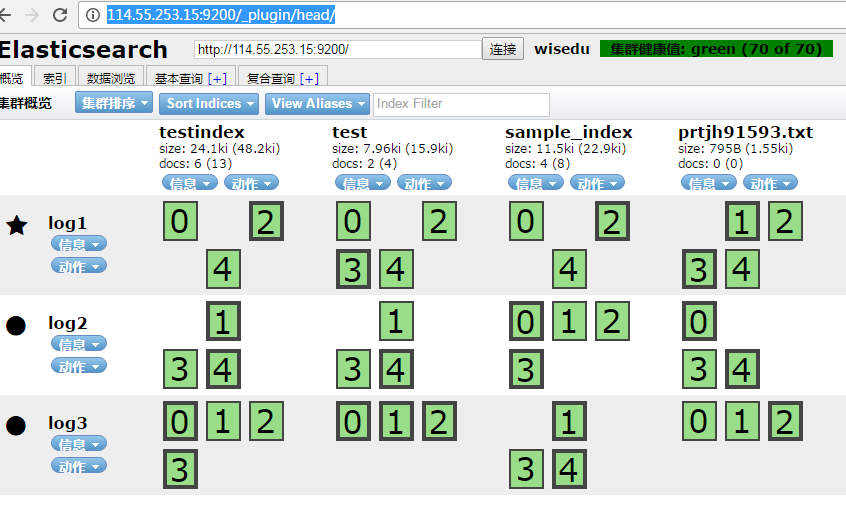
通过图形界面可以查看集群信息,索引信息,索引状态,检索数据等操作。大概有个印象,后面介绍下大概用法,及JavaApi如何使用












