
本文整理自Flink Forward 全球在线会议 ,演讲者云邪,由浪尖整理。
1. Flink table/sql架构演变
flink 1.9之前的版本,对于Table API和SQL的底层实现结构如下图,可以看处流处理和批处理有各自独立的api (流处理DataStream,批处理DataSet)。而且有不同的执行计划解析过程,codegen过程也完全不一样,完全没有流批一体的概念,面向用户不太友好。
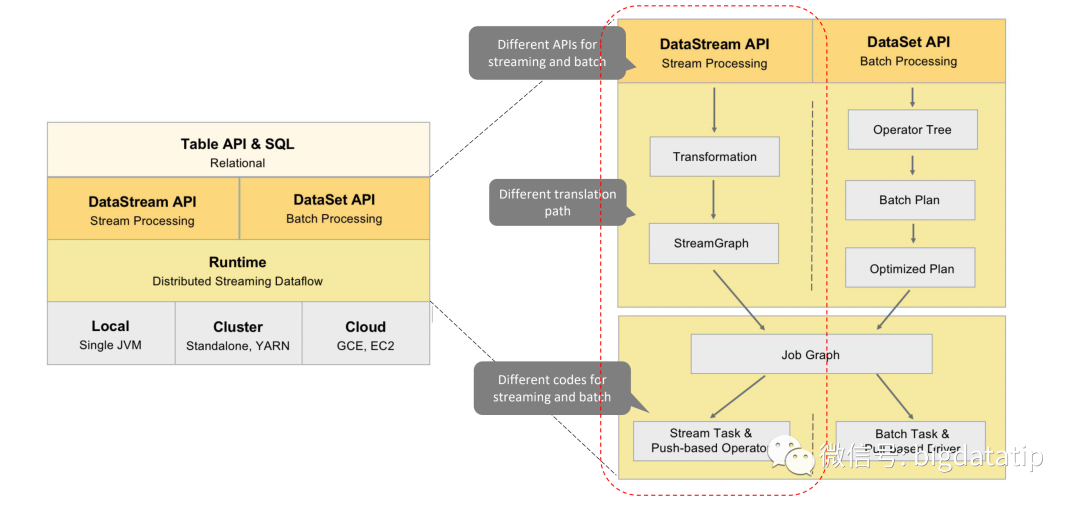
自flink 1.9之后的版本,在Flink Planner基础上,增加了Blink Planner,架构图如下:
自flink 1.9 版本为了兼容老版本Table及SQL模块,插件化实现了Planner,Flink原有的Flink Planner不变,后期版本会被移除。新增加了Blink Planner,新的代码及特性会在Blink planner模块上实现。blink planner的批或者流都是通过解析为Stream Transformation来实现的,不像Flink Planner,批是基于Dataset,流是基于DataStream。
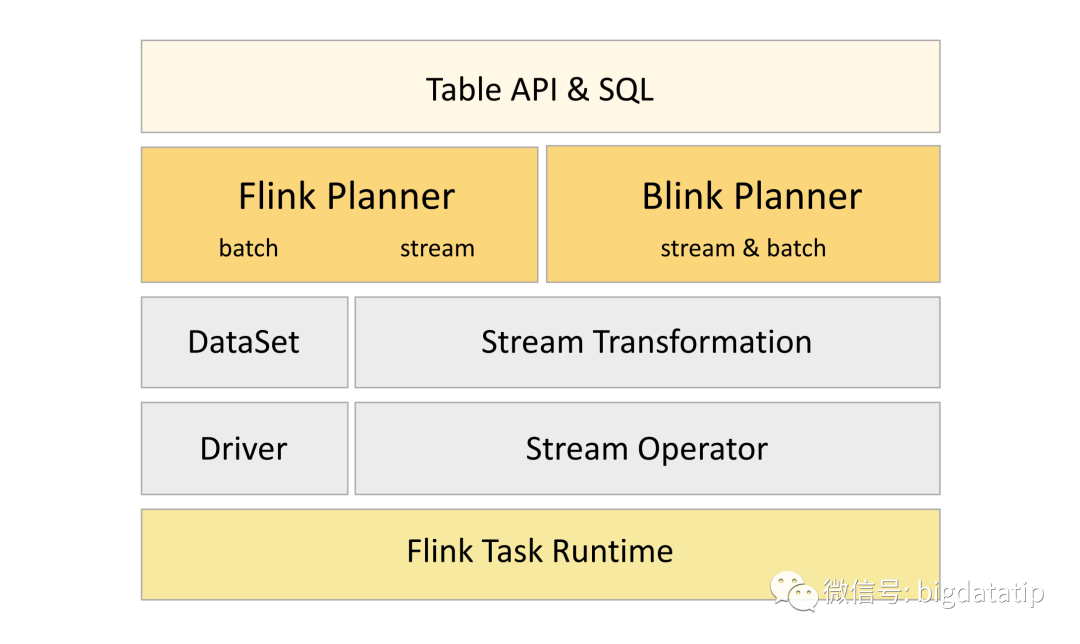
所以后期的架构会进一步实现流批统一,流批主要区别在Trasformation和codegen层,整体架构如下:

blink planner在1.11版本开始作为默认的planner,后期版本会移除调Flink Planner。
**2. flink sql的工作机制
**
下图是flink sql 的从编码层到执行的解析过程概览图:

flink 编程语言 :
scala,java,python,sql。
catalog支持hive 的metastore,也支持自定义Catalog。
API到Logical plan,会有catalg参与进来-目前是可以基于hive metastore,也可以自定义,catalog会提供,比如udf参数,返回值类型,表路径等等信息。
logical plan是优化起点,会被交给优化器optimizer进行优化,比如subquery 拆解,fliter/project下推,join recorder等,其实现过程中大量使用了calcite框架
Physical plan使用code generation生成transformations,这里也是做了大量优化,比如Code Optimizations,state-of-art opertors,resource Optimizations等具体可以看上图。
transformations之后就可以生成JobGraph了,可以用来提交到flink集群。
批和流的区别重点呈现在Pysical plan和transformations。
**3.批处理SQL解析过程
**
案例sql
select
首先,sql表达到逻辑执行计划,select操作对应Project,join对应join,where对应fliter,该逻辑计划如下图:
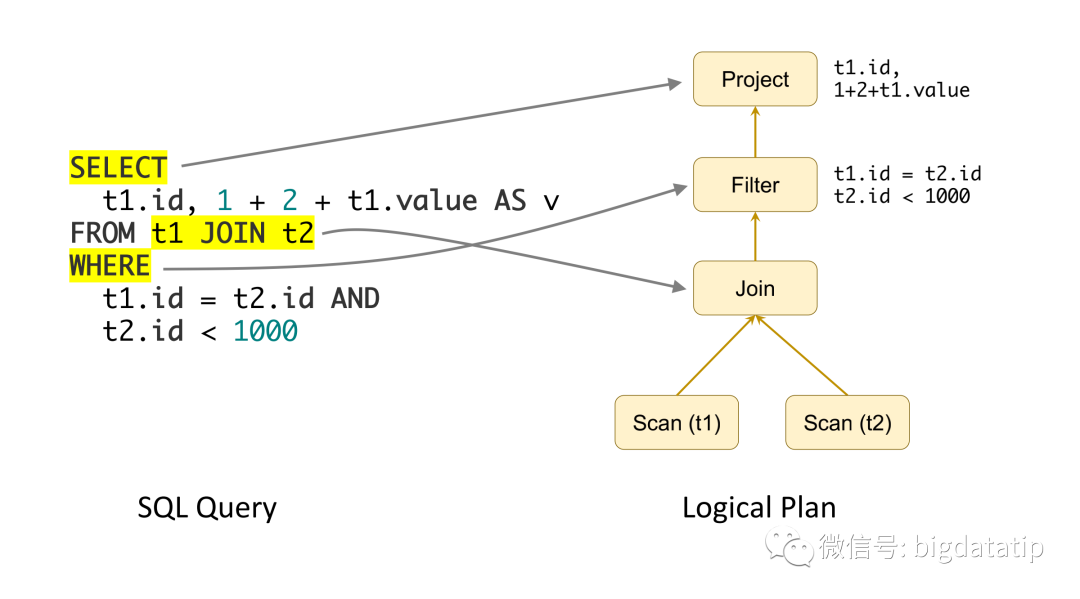
逻辑执行计划是优化的开始,案例中的sql优化过程如下:
常量折叠,也即是对sql中的常量的加减乘除等操作进行预计算,避免执行过程频繁对常量重复执行加减乘除计算:
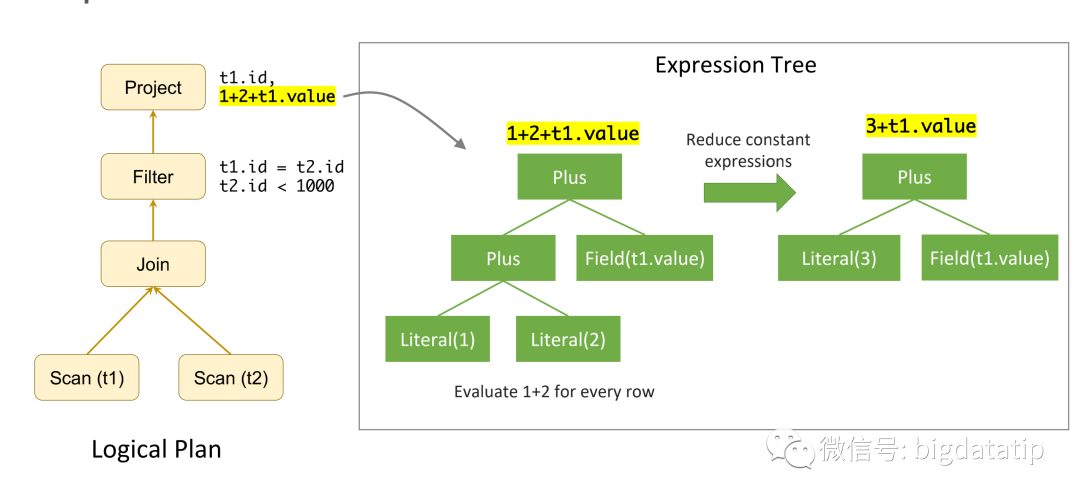
上图常量折叠前:1+2+t1.value;折叠后:3+t1.value,逻辑执行计划缩减了一个大步骤。
filter下推执行,这里就是把t2.id<1000,下推到扫描 t2表的时候。
假设不进行这一步优化,执行过程是:全量数据扫描,执行join操作,然后才进行fiter,这明显很浪费,id大于1000的不需要执行join操作,将fliter操作下推到join之前执行,减少了join的数据量,大大提升性能。
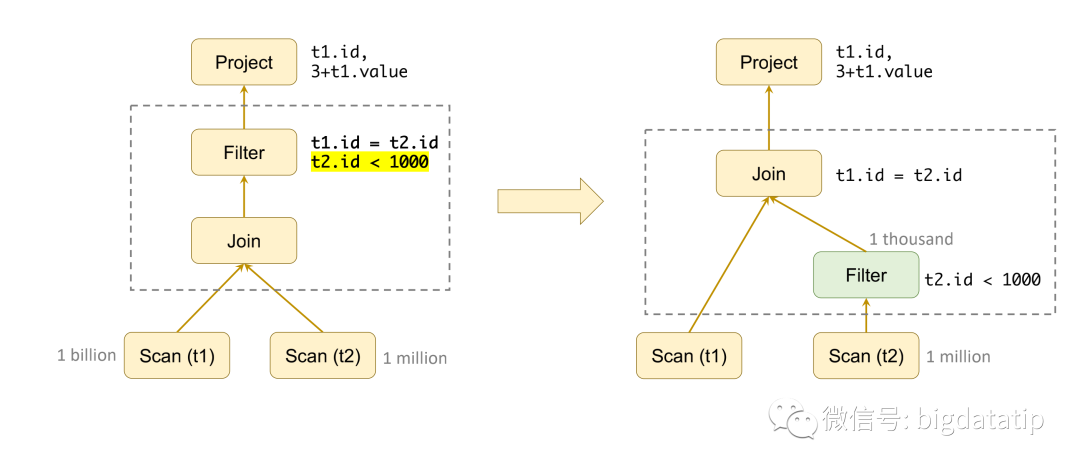
project下推执行,可以用来避免加载不需要的字段。由原来的sql可知,t1只需要加载t1.id,t1.value,t2只需要加载t2.id。假如表还有大量的其他字段,由于SQL中没用到,加载多余字段就是浪费,所以将project操作下推执行,就不需要加载无用字段。而且此时假如是列存储,只需要加载指定的列,优化更大。
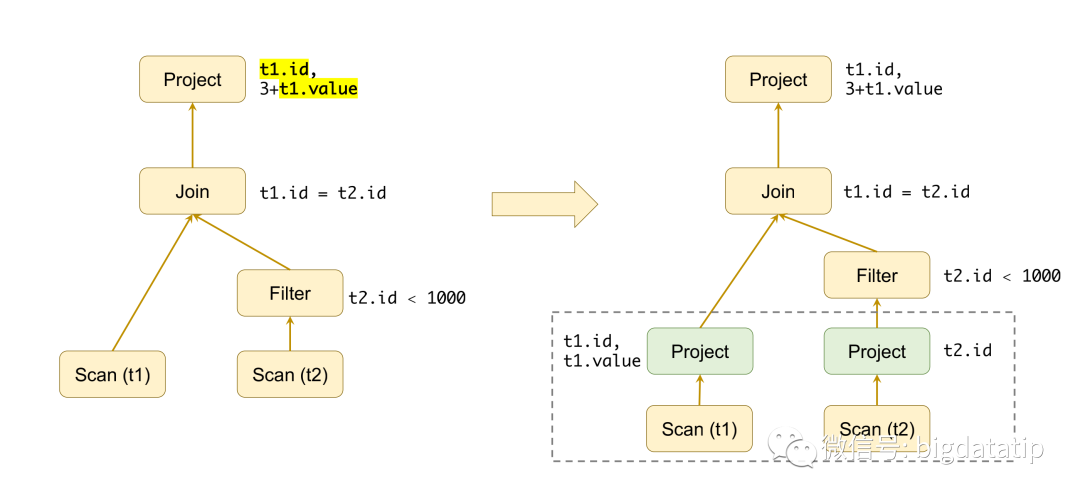
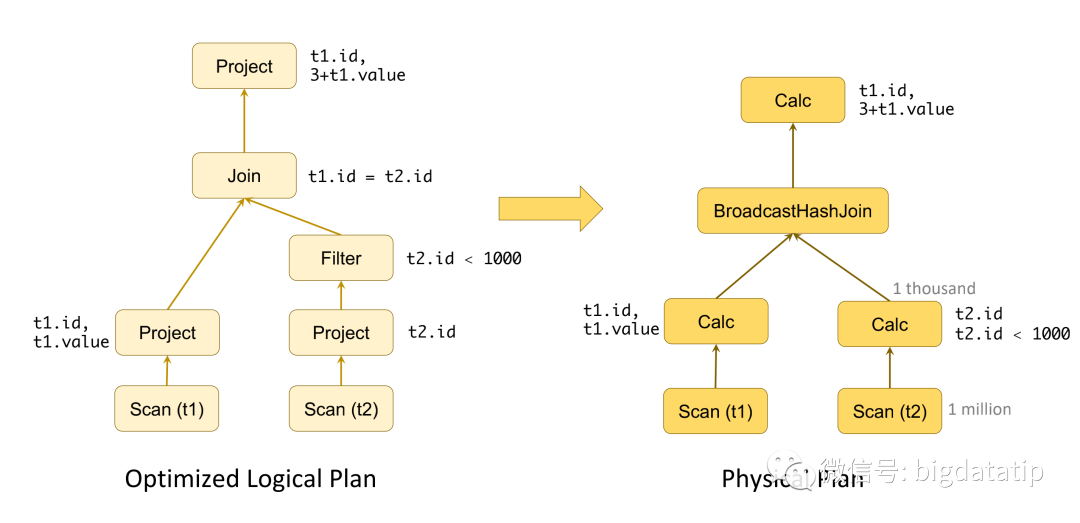
物理执行计划生成的时候也会进行很多优化操作,如根据代价cost选择批处理join有方式(sortmergejoin,hashjoin,boradcasthashjoin)。比如咱们这个例子,再filter下推之后,在t2.id<1000的情况下,由1 百万数据量变为了1 千条,计算cost之后,使用broadcasthashjoin最合适。
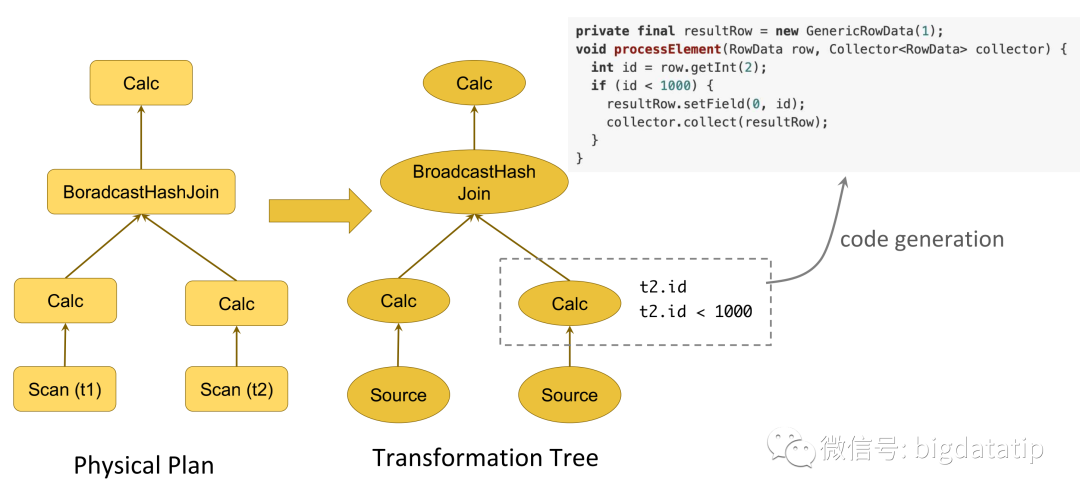
物理计划codegen过程,就是翻译成transformation tree的过程:
4.流处理SQL解析过程
flink 的流处理sql解析过程如下:
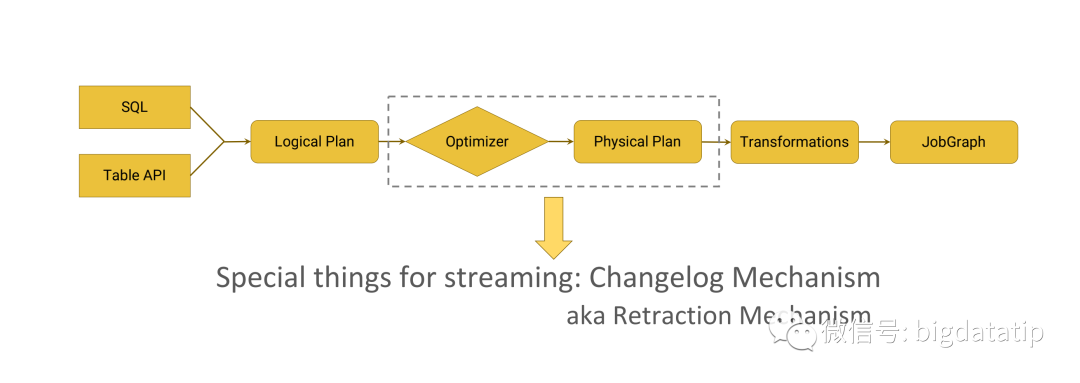
对于flink 流表的计算,在Optimizer和Physical plan过程中是需要引入changelog机制,也可以叫做retraction机制。
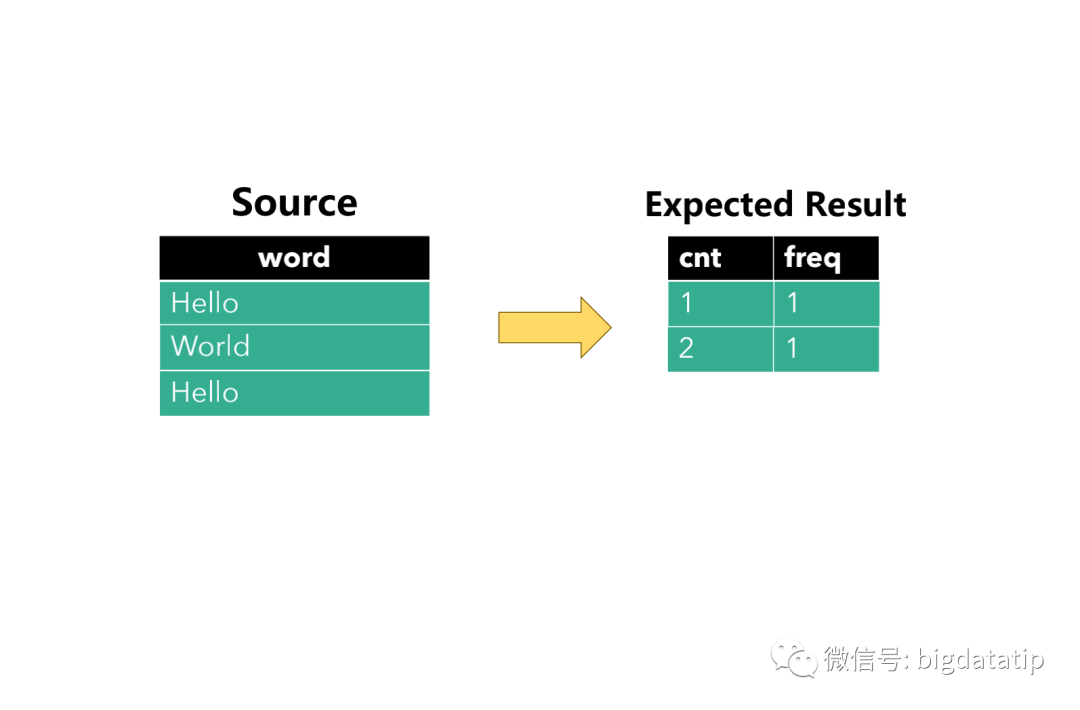
比如下面一条sql,表达含义就是先进行wordcount操作,得到临时表<列Row(word,cnt)>,然后统计频次cnt出现的次数。
SELECT cnt, COUNT(cnt) as freq
数据源先后输入的单词: hello,word ,hello。
期望的结果是cnt 值为1和2各 出现一次。
假如数据先输入了hello 和word两个词,得到计算过程及结果如下:

图中结果是cnt为1出现频次为2,因为word和hello各出现了一次。
此时,在输入hello,假设没有changelog机制,得到结果如下:
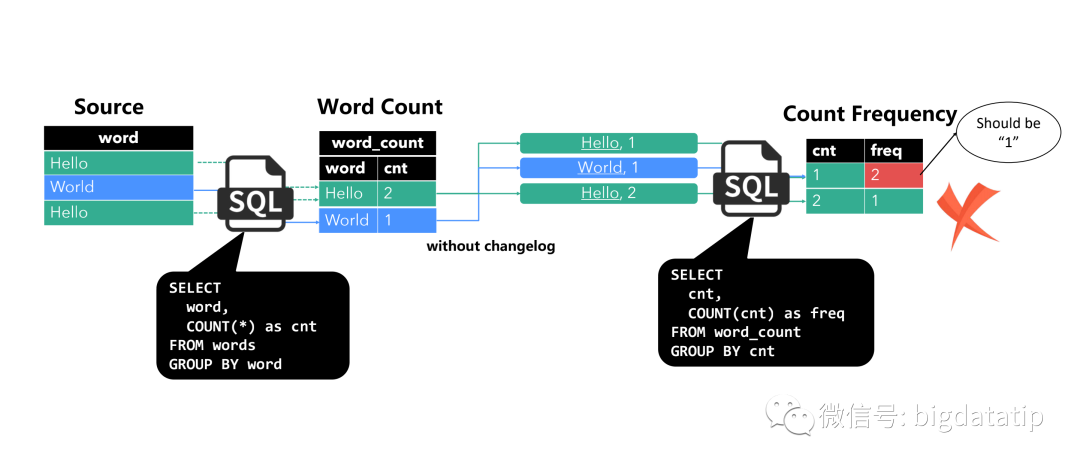
图中cnt 值为1出现的频次为2,cnt为2出现频次为1,这明显不符合预期,是错误的结果。
引入changelog机制,在wordcount aggregate计算结束之后,会给下游发送update_before和update_after两个消息,在进行cnt频率统计时,用来保证结果的正确性。
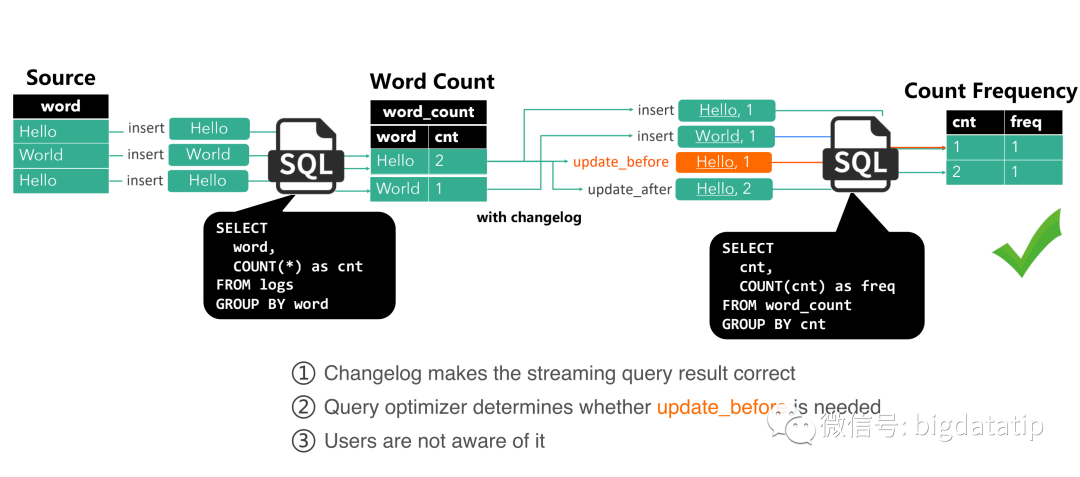
changelog机制保证了结果的正确性,同时query优化器决定者update_before消息是否需要,并且该机制对于用户来说是无感知的。
5.changelog机制介绍
5.1 确定node该产生消息类型
简单来说,对于flink流处理的动态实时表,主要是有三种操作Insert,update,delete。这三种操作在transfoation之间传递的时候就是对应着三种message,下游算子接受到这三种message之后就知道该进行如何操作了,changelog机制就以此来实现的。
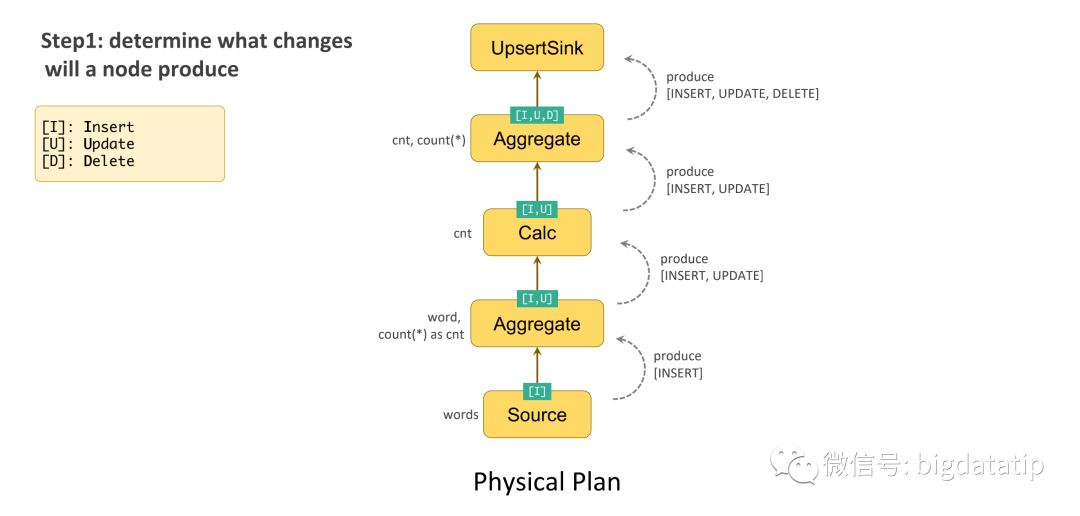
消息正向传递过程解释:
Source到word count的Aggregate算子只产生了一种消息-INSERT message。
word count的Aggregate之后到Calc产生了两种message,分别是新增的消息 INSERT ,更新的消息UPDATE ,Calc不会产生新的消息,直接透传消息到cnt频次统计的Aggregate算子。
cnt频次统计的Aggregate操作向 UpsertSink发送 了三种消息,分别是INSERT, UPDATE, DELETE 。
最后upsertSink就根据cnt频次统计Aggregate传递的这三种消息,做具体的操作(insert,update),保证结果的正确性。
**5.2 确定update消息内容
**
一个update消息,有两个内容:update_before和update_after。产生update消息的节点,可以只发送update_after,也可以同时发送两个消息,这个决定于下游算子,推导过程可以从sink到source。
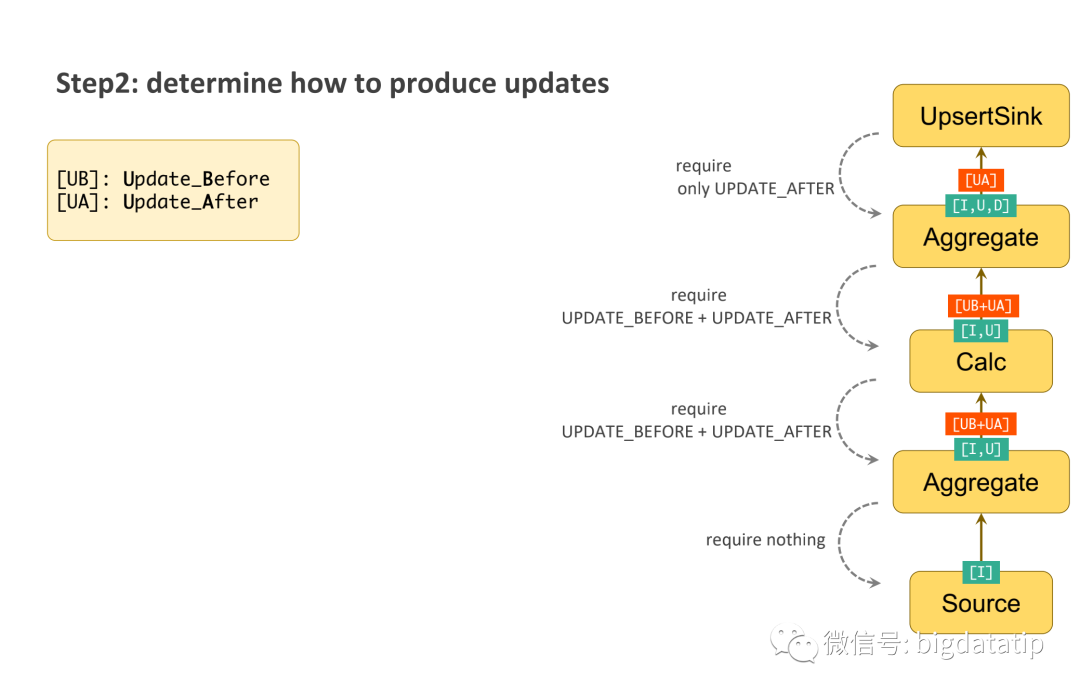
update message推导过程:
updsertSink假设只接受Update_After消息,那么他就会告诉频次统计的Aggregate,只发送Update_After消息即可。sink编写时确定接受消息类型。
Aggregate知道前一层会发送: update_before和update_after,而自身也需要两种消息,那么就会通知Calc节点同时发送两种消息,其实Calc节点是不会产生消息,只会透传的。
Calc会知道wordcount的aggregate算子会产生 update_before和update_after,而且自己也需要向下传递两个消息,所以会要求Aggregate产生 update_before和update_after两个消息。
wordcount的aggregate算子由于知道source不会产生update消息,所以不会要求其传递update消息。
最后就是正向传递update消息的过程,具体过程如下图右侧,source 到sink流动箭头。

经过上述过程之后,最终生成的物理计划如下:
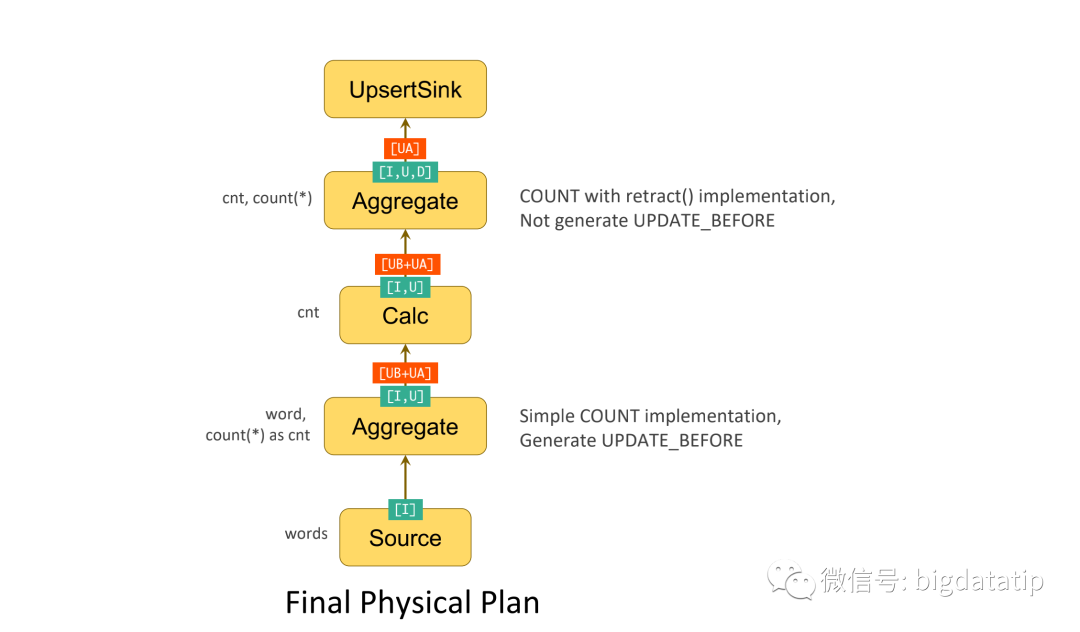
**6. Flink的一些优化操作
**
6.1 内部数据结构优化
原有的row数据结构如图:
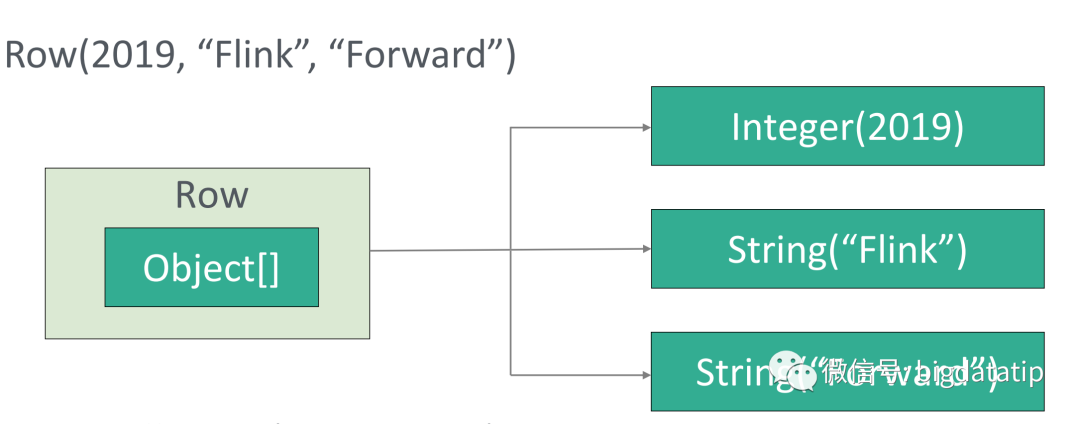
主要有以下几个缺点:
a.占用过多空间,比如object 头。
b.频繁的封箱和拆箱操作
c.序列化和反序列化的开销,尤其在随机访问字段的时候开销更明显。
新的内部数据结构,BinaryRow如下图:
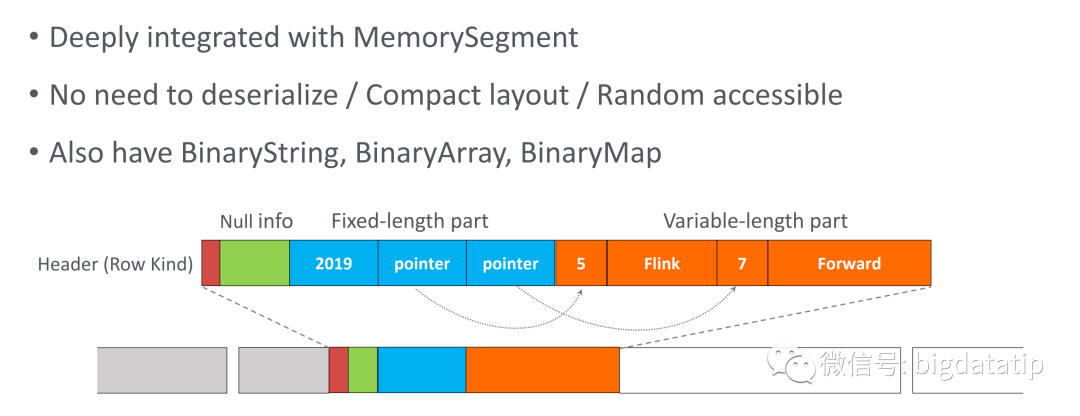
BinaryRow有以下有点:
a.与MenorySegment深度整合。
b.大量减少反序列化及序列化操作/压缩/随机访问更友好
c.依然支持BinaryString,BinaryArray,BinaryMap。
解析一下,BinaryRow源码可以知道:
由Flink的最小内存管理单元 MemorySegment 支撑实现,能够大量减少序列化与反序列化的开销
正如上图所示,一个binary row含有两个部分: 定长和变长部分
a. Fixed-length part:
一个字节长的header
null bit sets 用于null 的追踪??与8个字节长的字对齐
field values 保存基本类型和能以8个字节长存储的变长的值
否则field values将会存储变长值的长度与offset
完全落在MemorySegment,这会加速field的读写速度。
单行的field的数值不能超过一个MemorySegment的容量
b.variable-length part:
- 可能会由多个memorySegment来存储
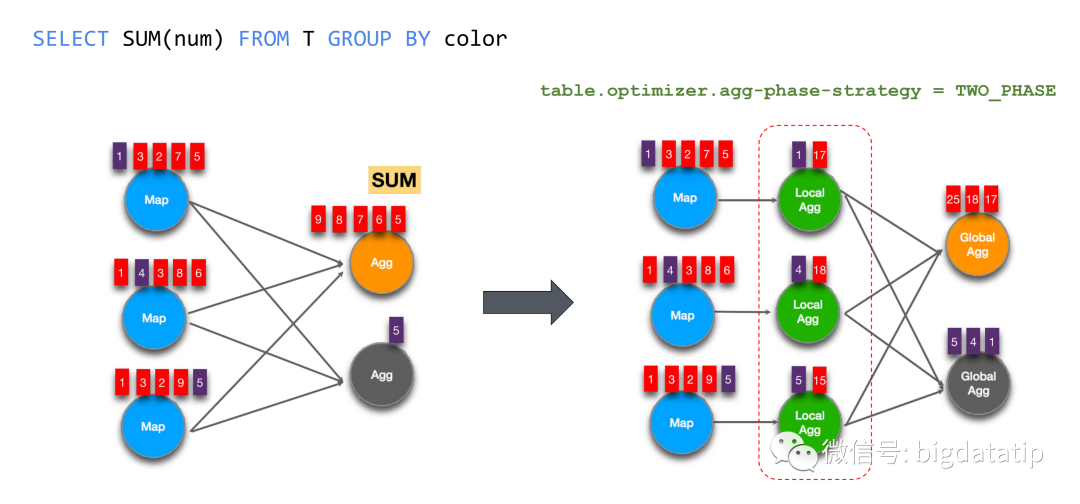
6.2 预聚合策略
其实,就是通过设置参数 :
table.optimizer.agg-phase-strategy = TWO_PHASE
来开启map端聚合操作,减少shuffle数据量。
**6.3 支持微批
**
大家都知道flink是可以基于时间和事件进行处理,原有策略是每条数据都会触发计算,状态更新等操作,这个其实性能也不是很好。
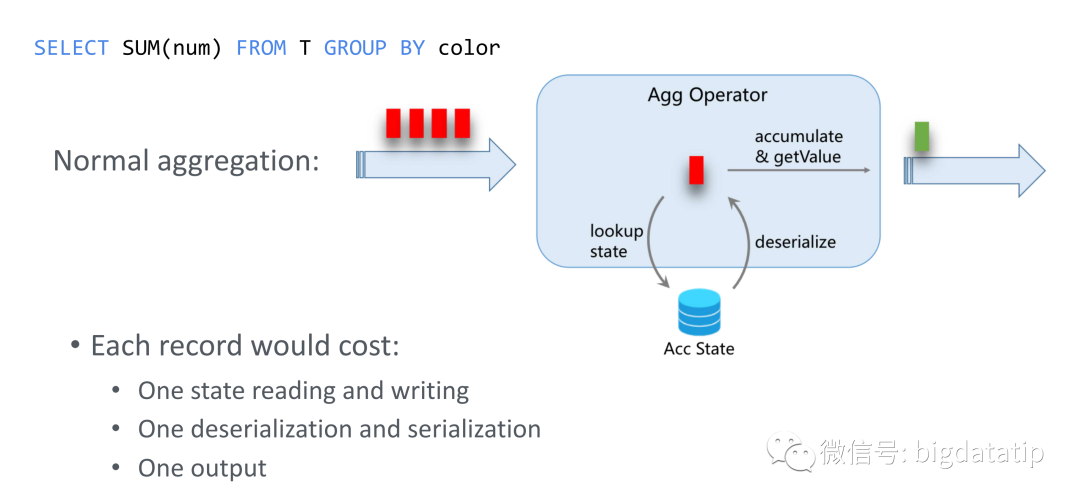
翻一下,就是 逐条消息处理 代价:
每次都需要读写状态,
每条消息都需要序列化反序列化,
每条消息都会输出一次。
支持微批处理,就会缓解单事件处理的缺点,具体介绍如下:
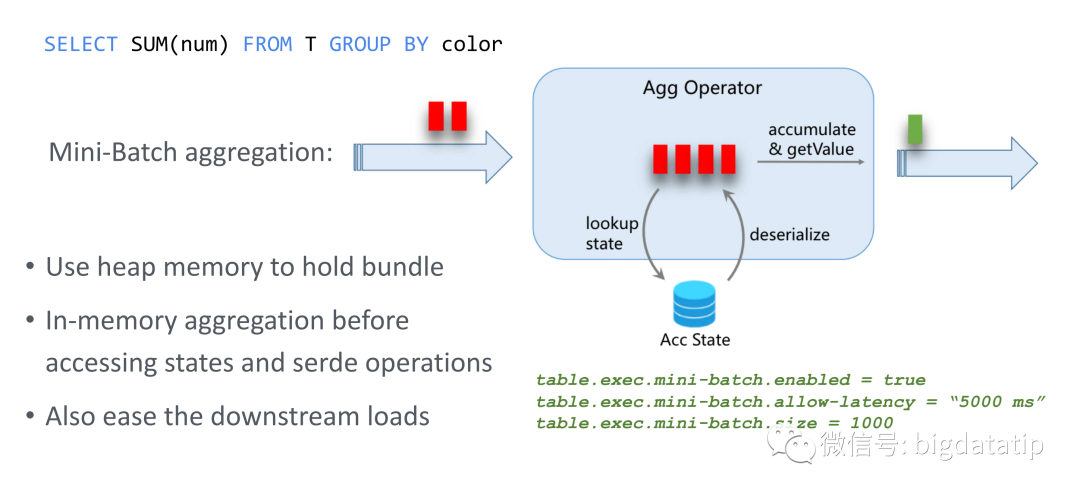
策略也是很简单,批次加超时,来实现该功能,主要有三个配置:
// 开启支持微批table.exec.mini-batch.enabled = true// 微批处理超时时间设置,主要是处理 积累不到指定的批大小,程序永远等待的情况。table.exec.mini-batch.allow-latency = "5000 ms"// 每个批次的大小table.exec.mini-batch.size = 1000
优点:
使用堆内存缓存数据。
在反问历史状态和进行序列化操作之前,内存中聚合。
也可以减轻下游的负载。
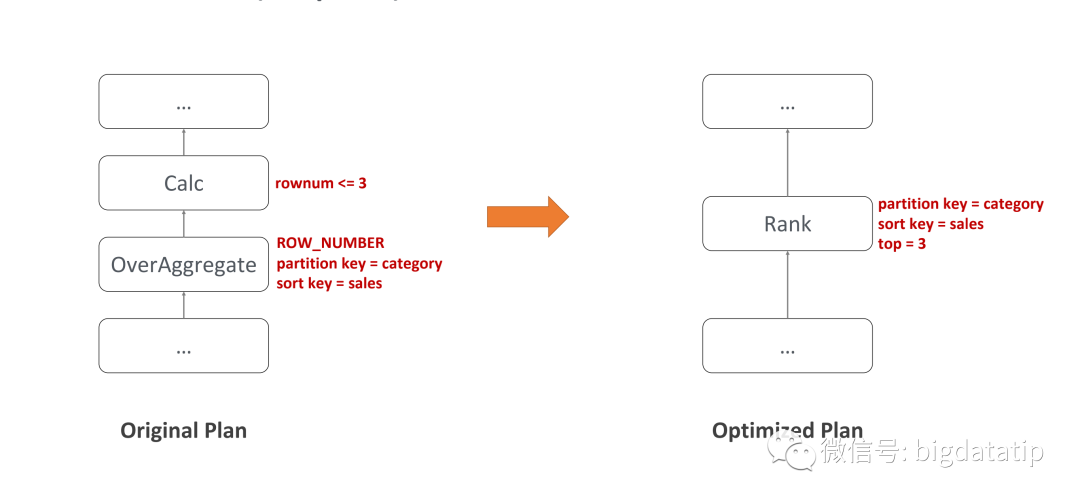
6.4 top n策略优化
实时计算中对数据全局排序代价是非常大的,但是计算top n还是比较容易实现的。
下面是计算每个类别,top n的策略,flink sql表达:
`SELECT *`
`FROM (`
` SELECT // you can get like shopld or other information from this`
` ROW_NUMBER() OVER (PARTITION BY category ORDER BY sales DESC) AS rowNum`
` FROM shop_sales`
`)`
`WHERE rowNum <= 3`
具体实现实际上是重写了底层的执行计划,将OverAggregate操作替换为了一个rank操作。
推荐阅读:
趣头条基于 Flink+ClickHouse 构建实时数据分析平台

本文分享自微信公众号 - 浪尖聊大数据(bigdatatip)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











