
作者:杨振兴
Worktile 前端工程师,PingCode Wiki 产品技术负责人
PingCode Wiki 提供结构化知识库来记载信息和知识,便于团队沉淀经验、共享资源,欢迎大家注册试用
本文主要分享基于Angular和Slate开发富文本编辑器的实践历程,基于Angular做编辑器对我们来说也是一个新的尝试,社区关于Angular编辑器的实现更多的是基于原生编辑器组件化包装(比如基于Quill、Prosemirror的Angular组件),我们借助Slate编辑器框架,实现基于Angular的视图层,这意味着编辑器的交互事件、数据渲染全部交给Angular处理,写编辑器功能就是写基于编辑器业务的Angular组件,所以我觉用Angular写编辑器是体验很高、很有意思的一件事情。
一、编辑器业务
特点
内容多样
交互多样
富文本要支持的内容是多样的,再加上跟用户的交互方式也是多样性的,比如普通输入、粘贴、拖拽等,所以编辑器的业务是复杂且难治理的,所以编辑器也一直被认为是天坑的存在
传统实现
- 操作DOM
- 输出HTML字符串
传统编辑器的开发主要是依赖浏览器原生的编辑能力,直接操作DOM修改富文本内容,输出的结果是HTML字符串,这其实是非常混乱的,随着编辑器支持特性的增多,代码的拆分和富文本数据的维护会越来越麻烦
数据流:
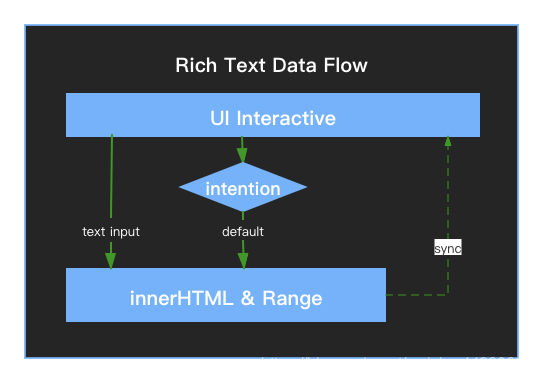
这种技术实现过于单薄,编辑器底层实现和功能拓展没有明确的边界,代码的理解成本可能会越来越大
结合Angular实现
编辑器是前端框架的一个绝佳应用场景,因为编辑器足够复杂,引入主流的编程思想或者框架可以有效拆解编辑器的复杂度,比如:
- 引入抽象的数据模型描述富文本数据
- 使用状态管理的思想统一编辑器的数据流
- 使用前端框架编写编辑器的交互界面
所以我觉得引入主流的编程实践和前端框架到编辑器中是有很大的进步意义的,并且引入框架其实可以很大程度上降低编辑器的开发难度,让编辑器的开发更大众化
使用Slate和Angular开发编辑器
Slate大概是在2016年开源的一款编辑器框架,从开源开始到现在一直保持着架构的创新性,底层不对编辑器的功能做任何的预设,抽离出了独立的视图层(让Angular开发编辑器成为可能),并且底层的所有代码已经全部用TypeScript重写,是非常有潜力的编辑器框架
Slate数据的抽象

有了对数据的抽象,结合Angular来做编辑器就变得很容易,每一种数据都可以转换成由特定的Angular组件来渲染
对应状态流转
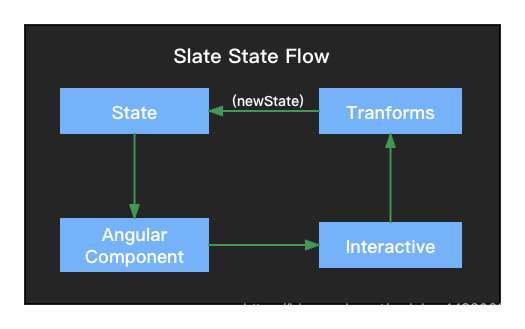
当然也有人认为编辑器引入前端框架是错误的,它会让编辑器的性能变差,不可否认引入框架会有一些性能损失,但从我的实践来看编辑器整体性能表现还可以,并且还可以根据框架特点做进一步优化
二、职责划分
Slate 职责
- 提供编辑器内核实现,定义数据模型(把富文本数据抽象成对象模型)
- 提供数据管理逻辑,基于不可变数据模型,定义底层的数据变换方法
Angular 职责
由于官方只提供基于React的视图层实现(插件机制、内容编辑代理机制),所以要想在Angular下开发编辑器,必须要实现一个基于Angular的视图层
- 使用Angular提供视图层的实现
- 插件逻辑加Angular组件的形式拓展编辑器功能,视图层本身不包含任何编辑器功能
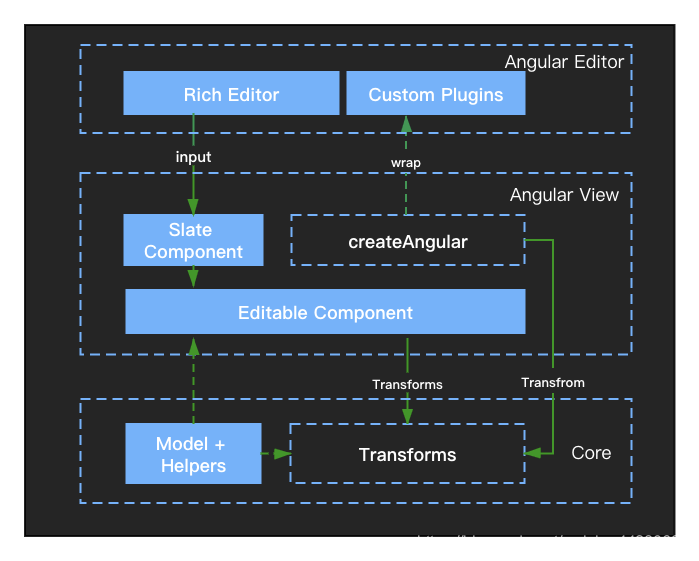
扩展一个编辑器功能(Alert)
介绍下使用Angular开发Alert(提示框)功能的一个流程
1、定义节点类型
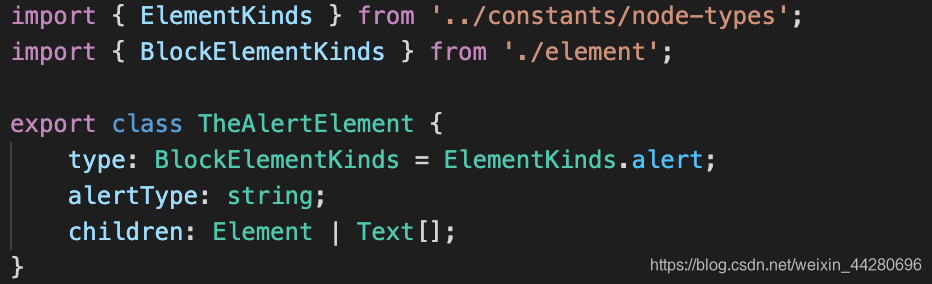
type是一个唯一标识,每一个块级节点都有一个唯一的数据类型
alertType是alert插件独有的,标识提醒类型
它有四种取值:
export enum ThyAlertType {
success = ‘success’,
warning = ‘warning’,
danger = ‘danger’,
info = ‘info’
}
children定义子节点
2、开发组件
开发一个Angular组件,显示该数据类型的UI
组件效果:

对应的组件模板:

虽然是写Angular组件来实现可编辑内容的显示,但是与写普通的Angular组件还是有一些差别的,主要有两点:
- 使用给子节点占位,这个需要根据需求把它放在正确的位置
- 因为整个组件是在可编辑区域内渲染的,所有要在指定的标签上增加contenteditable="false"让该区域不可编辑,避免造成焦点错乱。
可以看出来,在编写节点组件的时候我大量使用thy前缀的组件或者样式类,所以一些通用的UI我们是可以直接使用组件库来做的(thy其实是我们自己组件库的前缀)。
3、实现交互操作
Alert对应的交互操作其实有两类:
- 创建/删除Alert节点(可以是在空白区域创建,也可以是选择一个段落创建)
- 切换Alert节点的提示类型
为创建节点相对比较复杂,这里只介绍比较简单的提示类型的切换。
重新看下前面的模板,工具栏中的操作icon都绑定了mousedown事件,对应的处理函数是switchType,看下处理函数的实现:

第二个参数是单击的alertType的新值,然后通过Slate提供的Transform方法直接修改该节点对应的属性,当编辑器数据发生变化,框架会自动刷新UI,实现数据的驱动。
总结
扩展一个编辑器插件或者支持一种新的数据类型只需要简单的三步就完成了,跟开发普通业务功能差不多了,同样只需要修改数据,同样可以使用组件库进行UI实现,开发体验已经非常的好了。
三、Angular视图层机制
通过Alert插件的实现,大家了使用Angular扩展编辑器功能的一个基本体验,这种开发体验的背后其实是需要视图层的支持的,下面我会针对组件渲染、组件受控、性能优化等方面介绍下Angular视图层内部的实现机制
组件渲染
Slate把富文本数据抽象成节点树,不同的数据类型有不同的层级,理论上还可以互相嵌套,比如表格可以嵌套列表,那么最终的节点层级就达到了六级,可以看下嵌套的节点具体长啥样
提示框
表格

每一个块节点必须有一个children字段,节点理论上可以无限嵌套,只要保证叶子节点是text就行
所以视图层肯定要实现这些节点的对应组件的渲染,并且每个节点类型对应的UI组件需要支持由外部提供,是由运行时决定的。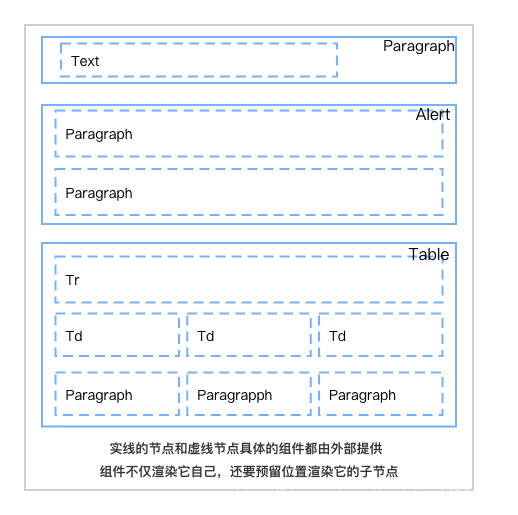
组件渲染的一个结构图,所以要实现嵌套渲染、组件动态配置还是有些复杂度的
模板递归
目前我们是通过模板递归的方式显示数据的渲染,核心是依赖Angular的ng-template,大致思路如下:
- 为一种类型的数据开发一个组件
- 把编辑器支持的有限组件先转换成模板定义
- 每个节点除了定义它自身的组件外还要定义子节点的模板插槽,因为子节点一定是一个数组,每一项有可能还是块节点,也有可能是Text节点(叶子节点),如果是块节点则会继续找它的模板定义,继续使用ngTemplatOutlet渲染,如此下去就是实现了递归渲染,如果遇到Text节点则直接使用特定的Text组件渲染,结束递归
- 视图层会根据插件提供的renderElement函数获取该类型指定的模板定义,然后直接使用ngTemplateOutlet渲染
模板定义:
视图层调用模板定义
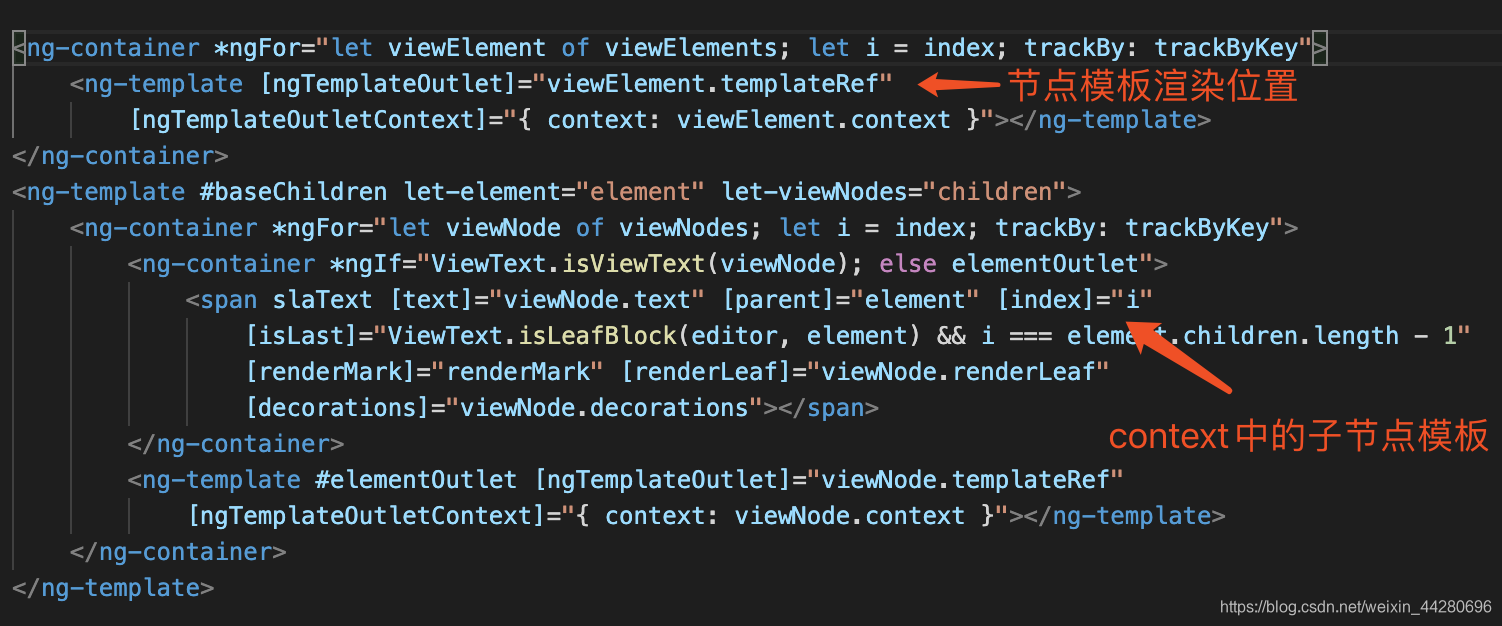
关键点在于baseChildren,它是子节点的渲染模板,并且如果子节点项仍然是块级节点,它会继续把baseChildren作为context中的childrenTemplate参数传递给模板定义,如此就在模板层面实现了递归调用
renderElement实现
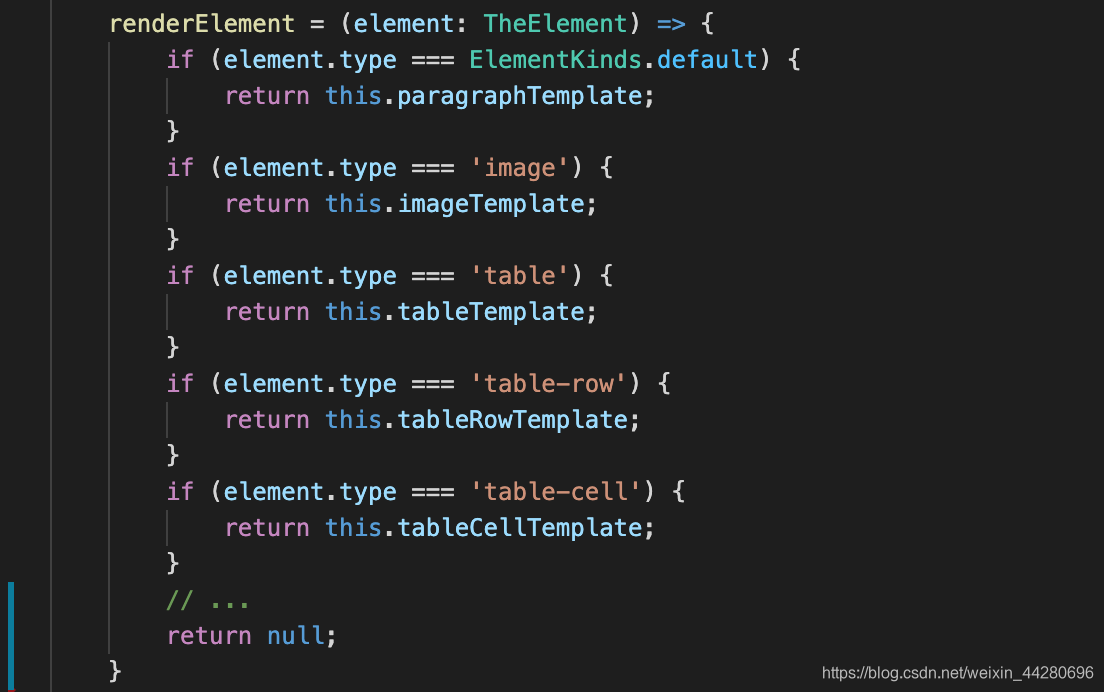
组件递归
其实我们是使用动态创建组件的方式来做的,虽然也能实现需求,但是有以下几个问题:
- 需要操作DOM把子节点放到动态创建组件的指定节点下,非常low
- 因为要往动态创建组件的指定节点下移动DOM,所以我需要在组件创建完成后立即调用detectChanges,这样一来组件原本的生命周期就会被破坏了,这给写插件带来了一些麻烦
- 第三个是使用动态创建组件后无法实现组件参数的自动更新,比如节点属性修改了,我只能通过给组件实例重新赋值的方式来通知组件
递归的理解可能稍微有点复杂,总之目前的做法是递归逻辑完全在模板中实现,数据的更新完全依赖Angular的检测机制,既实现不同数据使用不同组件渲染,也不用使用动态创建组件。
组件受控
虽然组件是由插件提供,但是我们还是需要对这些插件组件有一些基本的控制的,比如在组件渲染的根节点上增加统一的样式类,增加固定的属性,并且还要维护每一个数据节点与渲染的DOM的一个Map关系。
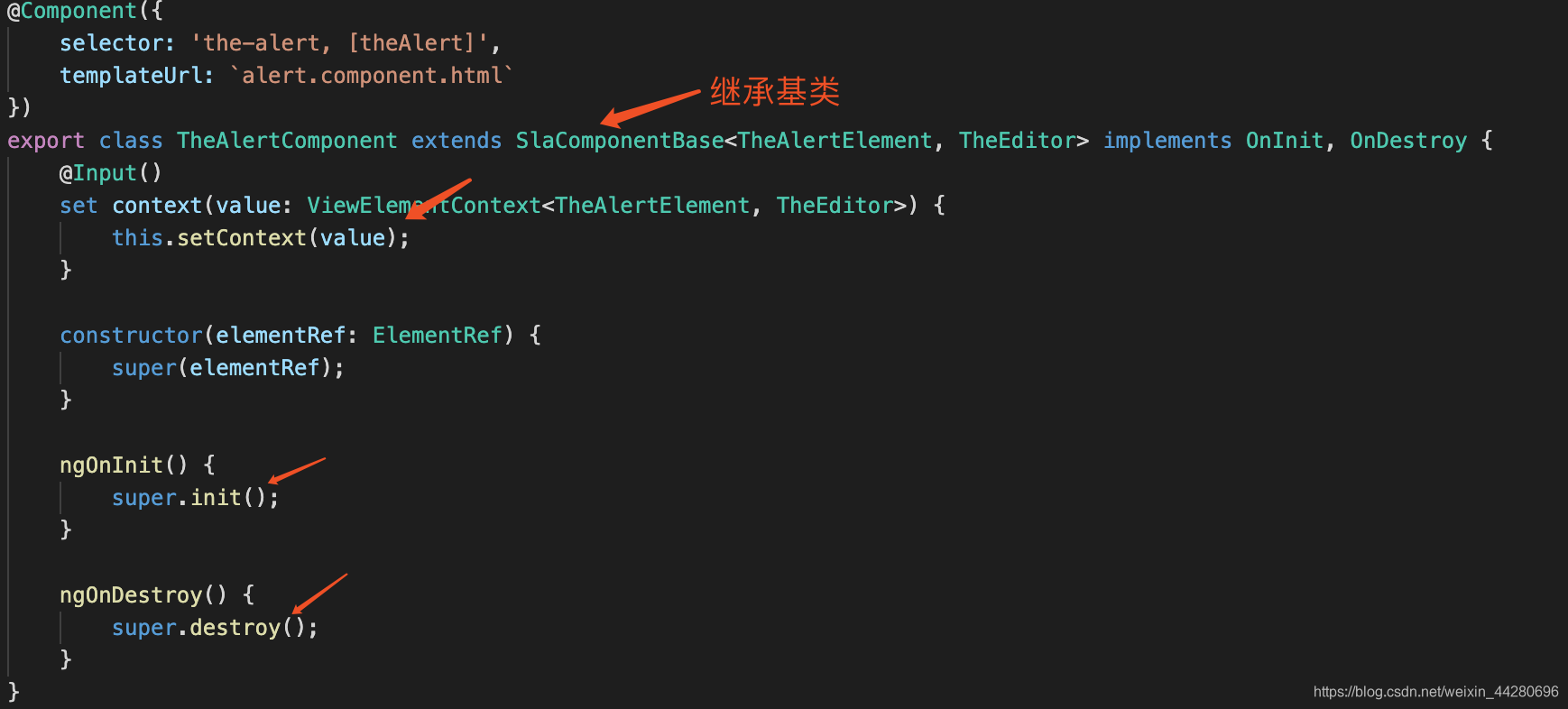
我们是目前是通过在视图层提供组件基类,通过所有插件组件统一继承这个基类,来实现这个需求的,看下基类的定义:
提供init、destroy、setContext三个函数的实现:

然后规定所有的渲染组件都必须要在相应的声明周期中调用这三个函数
init、destroy 分别在组件的ngOnInit和ngOnDestroy时调用
setContext 在当节点数据更新时调用
Alert组件的示意
性能优化
下面介绍下我基于Angular框架所做的一些性能优化
OnPush
OnPush是基本的,从使用Angular开发编辑器开始,视图层以及编辑器插件层所涉及到的组件基本都是OnPush模式,整个页面的变化检测不会传递到编辑器组件内部,这样基本保证编辑器组件不会拖累整体页面的性能。
NgZone
编辑器内部是需要监听很多DOM事件来监控内容输入的,比如keyup、click、beforeinput事件族等,在快速输入的场景,如果每一次事件触发都触发变化检测,系统性能必然会受到影响,所以编辑器内部的所有事件监听都是运行在runOutsideAngular之下,减少输入过程中不必要的变化检测开销。

trackBy
因为组件的渲染是其实是循环递归的模式,通常情况下一个节点内容的变更不会影响其它节点,所以可以通过trackBy进行进一步的优化

我这边的处理办法是为每一个节点都生成一个唯一key,底层根据这个key值进行trackBy,通常情况下key值不变化,组件只需要刷新状态即可,不需要组件的销毁和重建。

首次加载
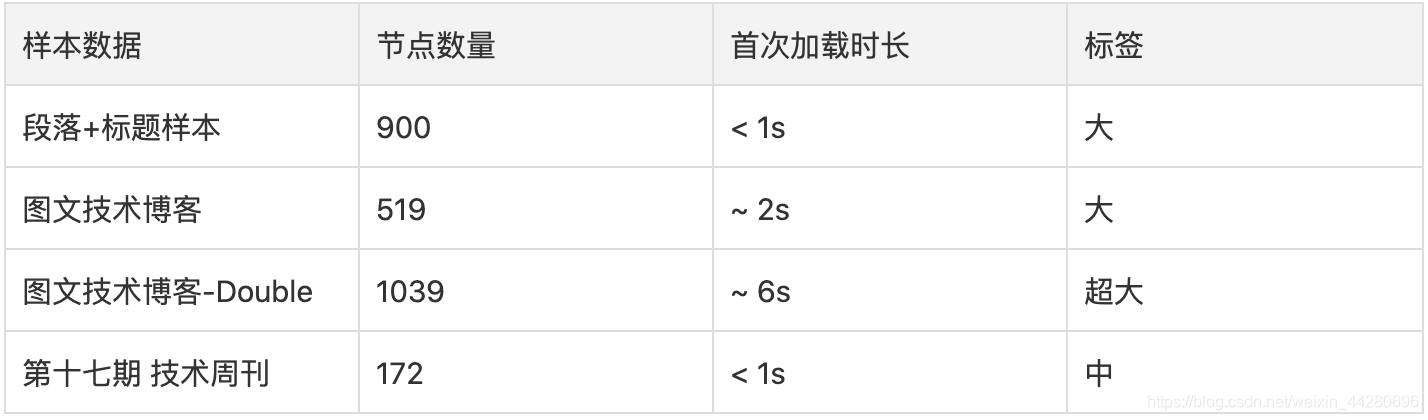
从测试的结果看,中等偏大(6000字)一些的文章还是可以实现秒级渲染的
输入流畅度
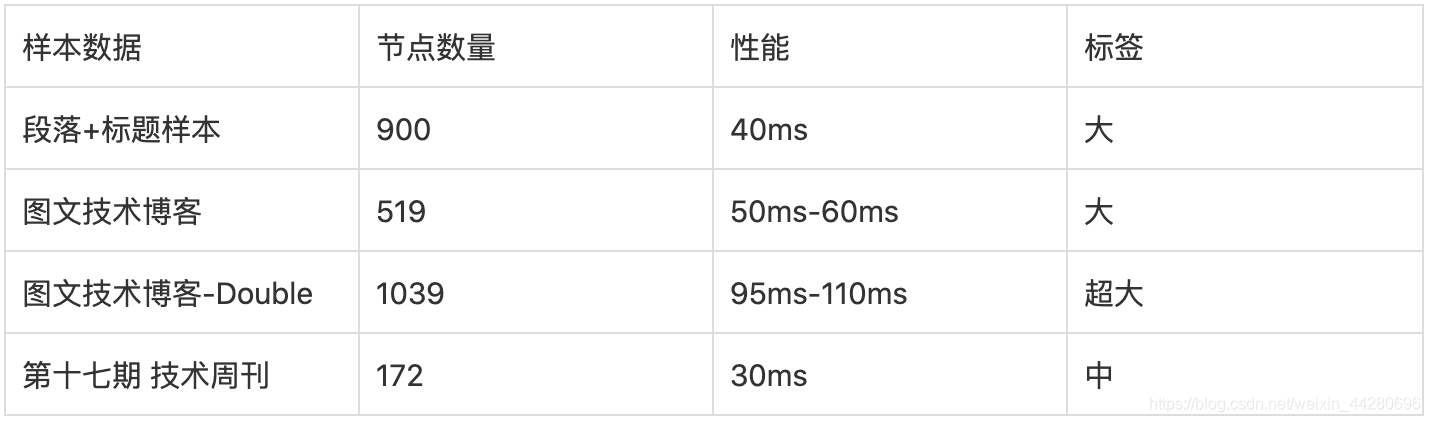
指标:从输入一个字符开始,到这个逻辑执行完毕和DOM刷新完成所花费的时间,60ms以下基本很流畅
所以除了特别大的样本有一些卡顿外,整体测试都是非常流畅的
踩过的坑
其实回顾使用Angular编辑器的过程,还有有遇到过一些坑的,这里分享几个跟Angular关联比较大的点:
comment 意外删除
Angular的模板语法会生成很多的comment节点,这些comment节点影响着模板内容的刷新,而在编辑器中整个组件的渲染都是可编辑器内的,所以在中文输入的某些情况下会造成comment节点被意外删除,然只要该节点数据再次变更,Angular就会把改模板对应的整个标签全部删除掉,然后造成内容意外丢失,编辑器失焦等等的现象。
这个问题还是比较严重的,目前的解决办法是在节点旁边增加隐藏的span,阻止浏览器默认删除comment节点的行为
中文输入性能问题
这个问题是前一段时间刚遇到的,因为使用模板递归渲染导致的,使用模板递归的这种方式会造成每渲染一个节点会都生成很多个comment,这些comment会造成中文输入非常卡顿,而且非常奇怪,这个问题只在Chrome下出现,Safari以及Firefox下都没有这个问题。
所以当初断定这个性能问题应该跟编辑的JS执行没有关系,应该就跟浏览器的一些机制有关。
这个问题也有点乌龙,目前的解决办法在模板渲染的最外层增加了一层自定义的组件标签(可能是减少了根节点下comment的的数量)
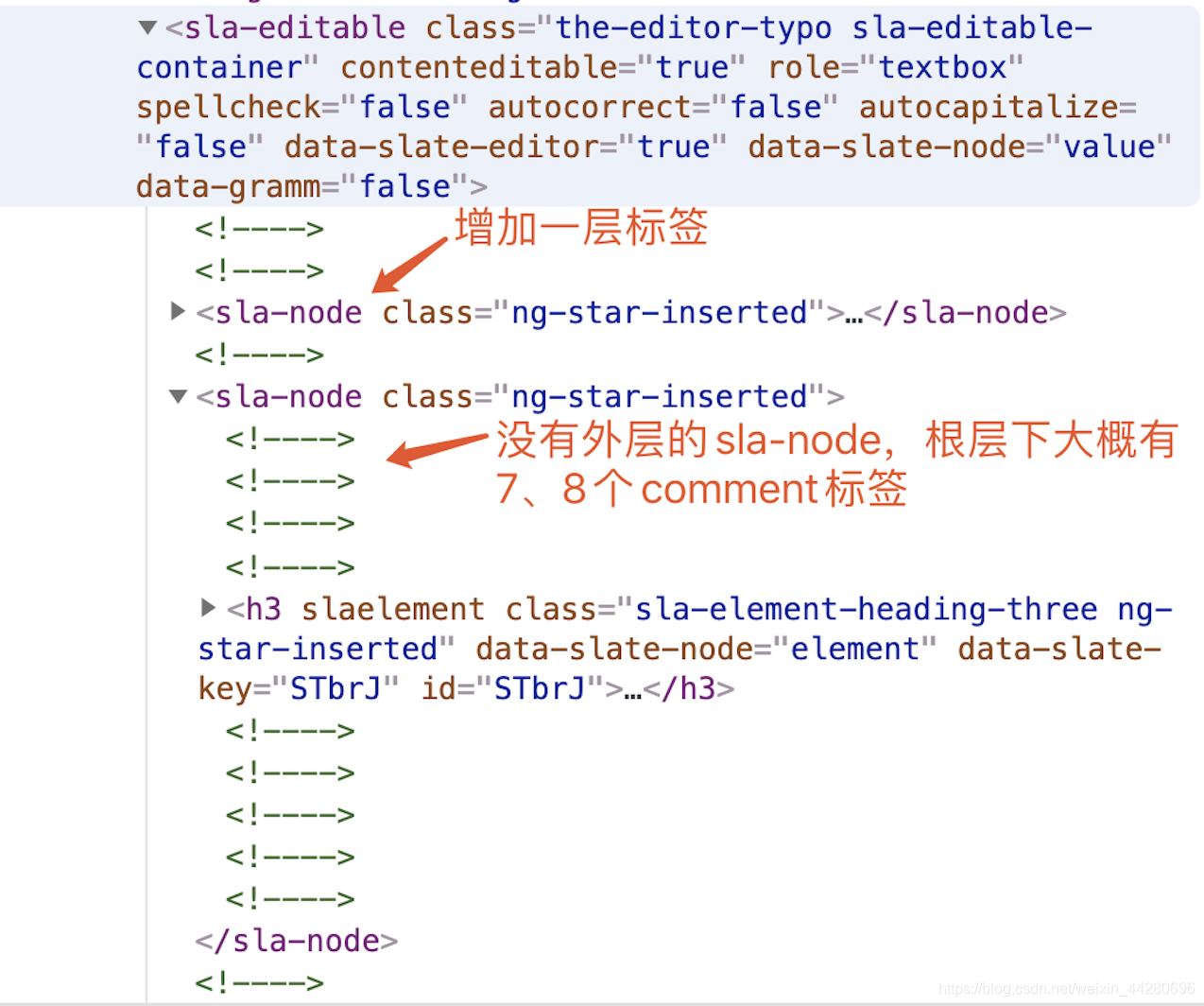
有了这层标签性能问题一下就解决了,非常神奇!
依赖注入问题
这个问题主要出在表格插件上,我想实现每一个表格共享一套Angular的服务,我在最外层表格上配置provider,以为它的子组件比如theTr、theTd,都可以通过依赖注入访问到这个服务,但结果让我很意外,子组件根本取不到表格上提供的服务,所以考虑到可能是Angular依赖注链关系的维护可能是在组件声明的时候决定的,而按照我们模板定义的实现,声明的时候Table组件和Td组件并没有直接的父子关系,导致依赖注入链没有续上。
最终的解决方案是,通过Map存储表格节点与表格渲染组件的这层关系,这样就可以通过节点的父子关系找到对应表格组件的实例,进而访问到表格所注入的服务了。
总结
了解Slate + Angular开发编辑器的基本情况
通过Alert插件的实现,体验了扩展一个编辑功能都需要做那些事情
通过组件渲染、组件受控、性能优化介绍了Angular视图层的核心机制
作者:杨振兴,Worktile 前端工程师,所在Team主要负责PingCode Wiki产品的研发,PingCode Wiki是一款企业级的知识库产品,提供模块化的页面帮助企业沉淀信息、分享经验,是重度依赖富文本编辑器的场景,欢迎大家试用体验.












