
本文仅讨论 Blinn-phong BRDF model 的高光specular部分,其BRDF 表达式为:
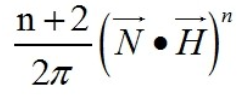
H 是半角向量:
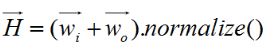
普通的monte carlo 方法在对BRDF 进行采样的时候是对出射光方向采样(比如phong模型),但是这里对光照结果产生影响的是半角向量,因此我们对半角向量H采样,然后再反推出出射光的方向。
山寨一张GPU gem 的图:
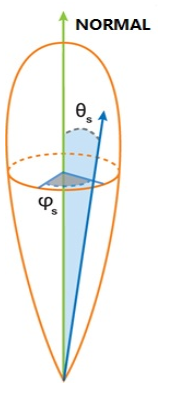
我们用θ ø 表示在 以N轴为Z轴的空间里H 向量的方向(球坐标), 这样只要θ按照余弦n次方的分布采样就能做到和BRDF一致实现重要性采样了;具体:
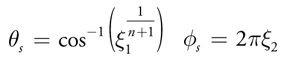
这样采样之后半角的分布就是:
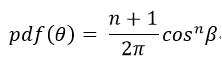
β 就是半角和法向量的夹角。
之后转换为x y z 坐标:
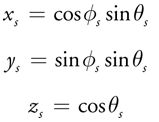
然后就是采样出来的H向量了,需要注意的是这里我们生产的分布是H向量的,在实际计算辐射积分的时候是关于入射向量的,所以需要做一个分布的转换(参考PBRT章节13.5)
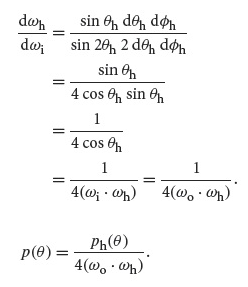
这样我们可以得出 最终采样的pdf表达式为:
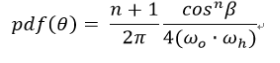
蒙特卡洛的估计量(BRDF / PDF) 可以简化成:
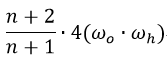
放一张path tracing 的结果:











