
微信公众号:聊聊架构
5 月 21 日,Netflix 在其官方博客上宣布正式开源微服务网关组件 Zuul 2。Netflix 公司是微服务界的楷模,他们有大规模生产级微服务的成功应用案例,也开源了相当多的微服务组件(详见 GitHub 主页),受到了业内同行的高度认可。Zuul 是 Netflix 于 2013 年 6 月 12 日开源的网关组件,目前在 GitHub 已经有超过 4000 个关注,包括 Riot、携程、拍拍贷等公司都已经在生产环境中使用。
Zuul 在英文中是一种怪兽,星际争霸中虫族里头也有 Zuul,Netflix 为网关起名 Zuul,寓意看门神兽。2013 年左右,InfoQ 曾经对前 Netflix 架构总监 Adrian Cockcroft 有过一次专访,其中有问 Adrian:“Netflix 开源这么多项目,你认为哪一个是最不可或缺的 (MOST Indispensable)”,Adrian 回答说:“在 NetflixOSS 开源项目中,有一个容易被忽略,但是 Netflix 最强大的基础服务之一,它就是 Zuul 网关服务。Zuul 网关主要用于智能路由,同时也支持认证,区域和内容感知路由,将多个底层服务聚合成统一的对外 API。Zuul 网关的一大亮点是动态可编程,配置可以秒级生效”。从 Adrian 的回答中,我们可以感受到 Zuul 网关对微服务基础架构的重要性。
因为 Zuul 开源时间较早,在架构方面也存在一些问题,所以在 2016 年 9 月,Netflix 对外宣布他们将会调整 Zuul 的架构。Zuul 原本采用同步阻塞架构,转型后叫作 Zuul 2,采用异步非阻塞架构。Zuul 2 和 Zuul 1 在架构方面的主要区别在于,Zuul 2 运行在异步非阻塞的框架上,比如 Netty。Zuul 1 依赖多线程来支持吞吐量的增长,而 Zuul 2 使用的 Netty 框架依赖事件循环和回调函数。
下面是 Netflix 官方博客中对于 Zuul 2 的介绍,供读者参考。
Netflix 的 Cloud Gateway 团队运行并维护着 80 多个 Zuul 2 集群,将流量分发到大约 100 个(还在不断增长)后端服务集群,每秒的请求数超过 100 万个。所有这些流量几乎都来自启用了大家熟悉的发现和回放体验的客户端设备和浏览器。
本文将详细介绍 Netflix 今天发布的 Zuul 2 的一些有趣特性,并讨论我们正在使用 Zuul 2 构建的其他一些项目。
Zuul 2 的工作原理
以下是 Zuul 2 的大体架构图:
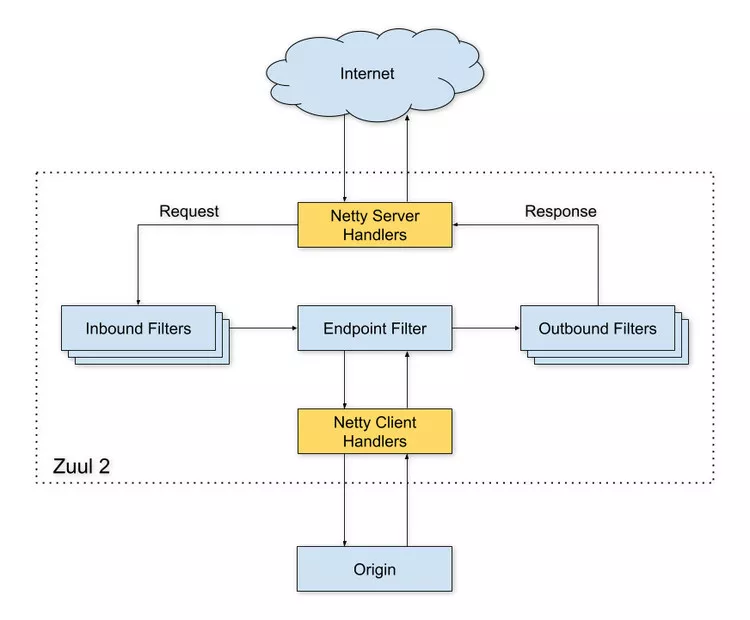
过滤器前端和后端的 Netty 事件处理器(handler)主要负责处理网络协议、Web 服务器、连接管理和代理工作。这些内部工作被抽象之后,所有主要的工作都会交给过滤器完成。入站过滤器在代理请求之前运行,可用于验证、路由或装饰请求。端点过滤器可用于返回静态响应,或将请求代理到后端服务。出站过滤器在返回响应后运行,可用于诸如压缩(gzipping)、指标或增删自定义请求头之类的内容。
Zuul 的功能几乎完全取决于每个过滤器的逻辑。这意味着它可以部署在多种上下文中,使用配置和运行的过滤器解决不同的问题。
我们在所有外部流量进入 Netflix 云服务的入口处都会使用 Zuul,并且也开始使用它来路由内部流量。Zuul用作外部流量网关和内部流量网关时,Zuul的核心架构是一样的,只是用作内部流量网关时实现相应功能的过滤器要少很多。
正式开源
今天运行的 Zuul 代码是 Zuul 最稳定和最有弹性的版本。经过多个阶段的代码库演化和重构,我们无比高兴将它分享给你们。
今天我们将发布许多核心特性。以下是最让人激动的:
服务器协议
HTTP/2——完整的入站(inbound)HTTP/2 连接服务器支持
双向 TLS(Mutual TLS)——支持在更安全的场景下运行 Zuul
弹性特性
自适应重试——Netflix 用于增强弹性和可用性的核心重试逻辑
源并发保护——可配置的并发限制,避免源过载,隔离 Zuul 背后的各个源
运营特性
请求 Passport——跟踪每个请求的所有生命周期事件,这对调试异步请求非常有用
状态分类——请求成功和失败的可能状态枚举,比 HTTP 状态码更精细
请求尝试——跟踪每个代理的尝试和状态,对调试重试和路由特别有用
我们也在研究一些即将推出的功能,包括:
Websocket/SSE——支持通道推送通知
限流和限速——防止恶意客户端连接和请求,帮助抵御大规模攻击
掉电过滤器——Zuul 过载时禁用一些 CPU 密集型特性
可配置路由——基于文件的路由配置,而不需要在 Zuul 中创建路由过滤器
Zuul 2 在 Netflix 的应用
在 Netflix,几个主要特性我们一直在研究,但尚未开源。每一个都值得专门写一篇博文介绍,但是我们现在只简单介绍一下。
自助服务路由
我们的合作伙伴使用最广泛的特性是自助服务路由。我们为用户提供应用程序和 API,以根据请求 URL、路径、查询参数或请求头中的任何条件创建路由规则。然后,我们将这些路由规则发布到所有 Zuul 实例。
主要的用例是将流量路由到特定的测试或临时集群。但是,实际生产流量有很多用例。例如:
需要分割流量的服务会创建路由规则,将某些路径或前缀映射到不同的源
通过创建新主机名映射到新的源的路由,开发人员上线新服务
开发人员运行负载测试,将一定比例的现有流量路由到小型集群,并确保应用程序在负载情况下会优雅地服务降级
通过逐步创建映射流量的规则,一次一条路径,重构应用程序的团队可以逐渐迁移到新的源
团队通过向运行新版本的插桩群集(instrumented cluster)发送一小部分流量来测试变更(金丝雀测试)
如果团队测试的变更需要多次连续请求新版本,他们将运行 Sticky 金丝雀测试,短时间内将同一批用户路由到新版本
安全团队创建基于路径或请求头的规则,拒绝所有 Zuul 集群中的“恶意”请求
正如你所看到的,我们广泛地使用自助服务路由,并且在增加路由的可定制性和范围,以支持更多的用例。
弹性负载均衡
我们一直在努力的另一个主要特性是,使负载均衡更加智能化。我们能够绕过运行大量节点时经常出现的故障、缓慢、GC 问题以及各种其他问题。这个特性的目标是提高所有 Netflix 服务的弹性、可用性和服务质量。
以下是我们处理的几个案例:
冷实例
当新的源实例启动时,一段时间内,我们会将它们的流量减少,直到它们变热。在具有大型代码库和使用巨大的元数据空间的应用程序中,我们观察到了这个问题。这些应用需要花费大量的时间来解释(JIT)代码并准备好处理大量的流量。
如果碰巧命中影响速度的冷却的实例,我们通常还会将流量偏向较旧的实例,我们总是可以重试热的实例。这使我们在可用性方面有了一个数量级的提高。
高错误率
由于各种原因,错误总是发生,无论是由于代码中的错误、错误的实例还是设置了无效的配置属性。幸运的是,作为代理,我们可以可靠地检测错误——无论是 5xx 错误还是服务连接问题。
我们跟踪每个源的错误率,如果错误率很高,这意味着整个服务都有问题。我们限制设备的重试次数并禁用内部重试,以便服务恢复。此外,我们还会追踪每个实例的连续失败并在一段时间内将失败的实例列入黑名单。
过载实例
通过上述方法,我们向集群中限流或拒绝连接的服务器发送较少的流量,并通过在其他服务器上重试这些失败请求来减轻影响。
我们现在正推出一个额外的方法,目标是一开始就避免服务器过载。这是通过让源向 Zuul 发送它们当前的利用率来实现的,Zuul 然后将利用率用作其负载均衡选择中的一个因子——从而降低错误率、重试和延迟。
源为所有响应添加请求头,说明其百分比利用率,以及期望的整个集群的目标利用率。计算百分比利用率完全取决于每个应用程序,工程师可以使用最适合他们的任何指标。与我们提出一种通用的方法相比,这可以提供一个一般的解决方案。
通过这个特性,我们为每个实例分配一个分数(实例利用率和其他因素的组合),并进行二选一负载均衡选择。
异常检测和上下文警告
随着我们从少数几个源发展到任何人都可以快速启动一个容器集群并将其部署在 Zuul 后面,我们发现需要自动检测并确定源的故障。
得益于 Mantis 实时事件流,我们构建了一个异常检测器,汇总每项服务的错误率,并在服务出现问题时实时通知我们。它根据给定的时间窗口内所有异常,创建一个所有有问题的源的时间表。然后,我们创建一个包含上下文的警报电子邮件,其中包含事件时间表和受影响的服务。这使得运维人员可以快速关联这些事件并厘清思路,调试特定的应用程序或功能,并最终找到根本原因。
事实上,发送通知给源团队本身非常有用。除 Zuul 之外,我们还添加了更多内部应用程序,可以构建更为广泛的事件时间表。这在生产事故中提供了巨大帮助,帮助运维人员在发生严重中断之前迅速发现并解决问题。
原文地址:https://medium.com/netflix-techblog/open-sourcing-zuul-2-82ea476cb2b3











