
Ps:mongod是mongodb实例,mongos被默认为为mongodb sharding的路由实例。
本文使用的mongodb版本为3.2.9,因此参考网址为:https://docs.mongodb.com/v3.2/sharding/
此外最后几个部分还引用了https://yq.aliyun.com/articles/60096中的一些问题描述及解决方案。
**一、Sharding集群简介
**
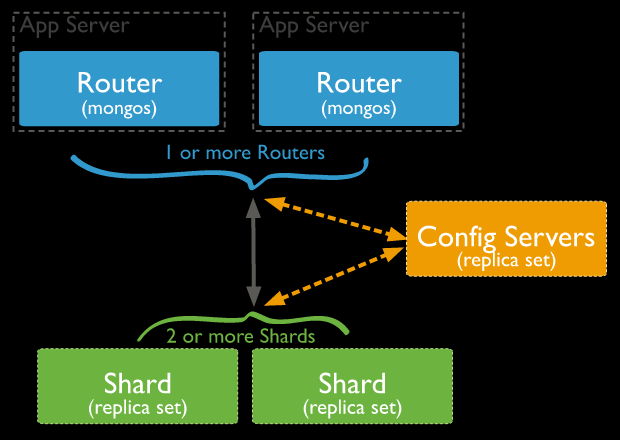
1.数据分片(Shards)
用来保存数据,保证数据的高可用性和一致性。可以是一个单独的mongod实例,也可以是一个副本集。在生产环境下Shard一般是一个Replica Set,以防止该数据片的单点故障。可以将所有shard的副本集放在一个服务器多个mongodb实例中。
sharding的每个node的database中的集合可以是分片也可以不分片,每个db都有一个primary shard,未分片的集合就是存在其各自的primary shard中的。
2.查询路由(Query Routers)
路由就是mongos的实例,客户端直接连接mongos,由mongos把读写请求路由到指定的Shard上去。
一个Sharding集群,可以有一个mongos,也可以如上图所示为每个App Server配置一个mongos以减轻路由压力。
注意这里的mongos并不要配置为rs,因为只是个路由,并不存储数据,配置多个mongos的意思是配置多个单独的mongos实例。
3.配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则。3.2版本以后config server可以配置为replica set(CSRS),3.4以后config server必须配置为rs。
config server的rs不能有arbiter(3.2.9版本是这样,其他版本未测试),生产上建议config server的rs至少要有3个副本集成员。
MongoDB是在collection级别实现的水平分片。
二、分片键:Shard keys
shard key在sharding搭建完毕后是不能修改的,一个collection上只能有一个shard key。
shard key上必须有索引(可以是以shard key开头的联合索引),如果没有mongodb会为shard key创建索引。如果是已经存在的collection那么必须手动为shard key创建索引。
在sharding的collection中只有_id和shard key前缀的索引可以是unique index,其他索引只能是普通索引。如果一个普通key上有unique index那么你不能以其他key为shard key对collection进行sharding。
shard key的选择将会影响整个集群的效率,可扩展性和性能。而且也会影响你所能选择的分片策略。
关于shard key详见:https://docs.mongodb.com/v3.2/core/sharding-shard-key/
分片范围是[shard_key_value_m,shard_key_value_n),MongoDB把每个分片叫做一个shard,一部分shard key的集合叫做chunk,一个shard上可以有多个chunk也可以只有一个chunk,一般会有多个。
三、Sharding的优势
1.读写方面:
sharding将读写负载均匀到各个shard,且workload上限可以通过水平扩展来增加。
2.扩容方面:
每个shard保存一部分数据,可以通过增加shards来扩容。
3.高可用方面:
即便某个shard不可用了,整个集群也可以对外提供服务,只不过访问down掉的shard会报"Connection refused"的错误。而且MongoDB3.2以后可以为每个shard都配置副本集(replica set),这样保证最大程度的高可用性。
四、Sharding的劣势
数据量较少时不建议使用sharding,毕竟读写都要经过一层路由会有性能损耗,直接表现就是ips和qps会降低。
五、使用Sharding前需要考虑的一些事情
1.sharding集群不支持一些常规的单实例方法,如group(),可以使用mapReduce()或者aggregate()中的group来替代,因此建议从一开始学习就直接使用aggregate(),这种写法较为简单明了,且统一化易于识别。
2.对于没有用到shard key的查询,路由进行全集群广播(broadcast operation),对每个shard都查一遍进行scatter/gather,此时效率会很低。
3.生产上使用副本集或sharding时,要考虑到安全认证的问题,集群节点间要指定keyfile启动(指定keyfile后auth默认会开启),如果集群环境下只开启auth认证不配置keyfile,replica节点之间的同步就会失败。
六、Sharding策略选择
1.hash sharding:https://docs.mongodb.com/v3.2/core/hashed-sharding/
当shard key总是单调递增时hash sharding并不是一个很好的选择,其查询分发基本和broadcast operation一样了,因为hash会把数据比较均匀的分布在各个shard上,但此时选择ranged sharding也有缺点,因为数据过度集中会导致数据集中于某个shard。
2.ranged sharding:https://docs.mongodb.com/v3.2/core/ranged-sharding/
在shard key选取不正确的情况下,范围分片会导致数据分布不均匀,也可能遭遇性能瓶颈,因此需要合理的选择ranged shard key。
3.Tag aware sharding:https://docs.mongodb.com/v3.2/core/tag-aware-sharding/
原理如下:
sh.addShardTag() 给shard设置标签A
sh.addTagRange() 给集合的某个chunk范围设置标签A,最终MongoDB会保证设置标签 A 的chunk范围(或该范围的超集)分布设置了标签 A 的 shard 上。
Tag aware sharding可应用在如下场景:
将部署在不同机房的shard设置机房标签,将不同chunk范围的数据分布到指定的机房
将服务能力不通的shard设置服务等级标签,将更多的chunk分散到服务能力更强的shard上去。
使用 Tag aware sharding 需要注意是,chunk分配到对应标签的shard上不是立即完成,而是在不断insert、update后触发split、moveChunk后逐步完成的,并且需要保证balancer是开启的。所以你可能会观察到,在设置了tag range后一段时间后,写入仍然没有分布到tag相同的shard上去。
七、Sharding搭建步骤:
关于sharding的操作方法参考:https://docs.mongodb.com/v3.2/reference/method/js-sharding/
环境说明:
MongoDB版本:3.2.9
节点:192.168.20.70/71/72
架构说明:
70:包含mongos、config server(master)、3个shards(master)
71:包含config server(slave)、3个shards(slave)
72:包含3个shards(arbiter)
--网上很多资料说config server必须是奇数个,但至少在本次搭建的3.2.9版本中2个也是可以的。
1.配置config server
--master的mongo.conf(192.168.20.70)
directoryperdb=true
replSet=config
configsvr=true
logpath=/home/mongod/config_master/mongod.log
logappend=true
fork=true
port=27018
dbpath=/home/mongod/config_master
pidfilepath=/home/mongod/config_master/mongod.pid
--slave的mongo.conf(192.168.20.71)
directoryperdb=true
replSet=config
configsvr=true
logpath=/home/mongod/config_slave/mongod.log
logappend=true
fork=true
port=27018
dbpath=/home/mongod/config_slave
pidfilepath=/home/mongod/config_slave/mongod.pid
然后启动并配置config server的rs(replica set):
mongod -f /home/mongod/config_master/mongo.conf
mongod -f /home/mongod/config_slave/mongo.conf
use admin
cfg={_id:"config",members:[{_id:0,host:'192.168.20.70:27018',priority:2}, {_id:1,host:'192.168.20.71:27018',priority:1}]};
rs.initiate(cfg)
2.配置shards
本例中配置了3个shards,分别使用70服务器的27017,27020,27021端口,他们的slave和arbiter分别使用71和72服务器上的相同端口。
--shard1的master、slave、arbiter的配置文件(分别在70、71、72上)
--master:
directoryperdb=true
replSet=shard1
shardsvr = true
logpath=/home/mongod/shard1_master/mongod.log
logappend=true
fork=true
port=27017
dbpath=/home/mongod/shard1_master
pidfilepath=/home/mongod/shard1_master/mongod.pid
--slave:
directoryperdb=true
replSet=shard1
shardsvr = true
logpath=/home/mongod/shard1_slave/mongod.log
logappend=true
fork=true
port=27017
dbpath=/home/mongod/shard1_slave
pidfilepath=/home/mongod/shard1_slave/mongod.pid
--arbiter:
directoryperdb=true
replSet=shard1
shardsvr = true
logpath=/home/mongod/shard1_arbiter/mongod.log
logappend=true
fork=true
port=27017
dbpath=/home/mongod/shard1_arbiter
pidfilepath=/home/mongod/shard1_arbiter/mongod.pid
shard2和shard3的配置文件与shard1基本一致,只需要把相应的replSet设为shard2\shard3,相应的目录修改为shard2\shard3,相应的端口修改为27020/27021即可。
建好相应的dbpath目录后,启动并为每个shard配置replica set,步骤如下:
use admin
cfg={_id:"shard1",members:[{_id:0,host:'192.168.20.70:27017',priority:2}, {_id:1,host:'192.168.20.71:27017',priority:1},{_id:2,host:'192.168.20.72:27017',arbiterOnly:true}]};
rs.initiate(cfg)
shard2和shard3的配置步骤一样,只需要把shard1修改为shard2/shard3,把端口修改为27020/27021即可。
3.完成config server和shards的rs配置后,就可以配置路由服务器了,路由服务器的官方名称是mongos,我们这里也以mongos称呼。
本例中只配置一个mongos,方法如下:
--注意:dbpath、directoryperdb等参数是不能出现在mongos的配置文件中的,简单起见只配置如下参数即可:
configdb = config/192.168.20.70:27018,192.168.20.71:27018 --这里的config是config server副本集的名称,后接config server的2个副本集节点。
logpath=/home/mongod/mongos/mongod.log
logappend=true
fork=true
port=27019
pidfilepath=/home/mongod/mongos/mongod.pid
然后启动mongos,注意mongos的启动是与其他类型的mongo实例不一样的:(用的mongos而不是mongod命令)
mongos -f /home/mongod/mongos/mongo.conf
4.至此完成了所有服务器的配置,接下来开始配置具体collection的分片策略。
登录mongos服务器:
mongo --port=27019
use admin
sh.addShard("shard1/192.168.20.70:27017,192.168.20.71:27017,192.168.20.72:27017");
sh.addShard("shard2/192.168.20.70:27020,192.168.20.71:27020,192.168.20.72:27020");
sh.addShard("shard3/192.168.20.70:27021,192.168.20.71:27021,192.168.20.72:27021");
然后在mongos上为具体的数据库配置sharding:
sh.enableSharding("test") --允许test数据库进行sharding
sh.shardCollection("test.t",{id:"hashed"}) --对test.t集合以id列为shard key进行hashed sharding
通过db.t.getIndexes()可以看到自动为id列创建了索引。
5.hashed分片验证
在第4步中针对test的t集合进行了分片配置,因此这里向t插入1000条数据做测试:
mongo --port=27019 --27019是mongos的端口号
use test
for(i=1,i<=1000,i++){db.t.insert({id:i,name:"Leo"})}
在3个shard的primary上使用db.t.find().count()会发现1000条数据近似均匀的分布到了3个shard上。
使用db.t.stats()查看分片结果,使用sh.status()查看本库内所有集合的分片信息。
6.其他分片方式
sh.shardCollection("test.t",{id:1}) --对test.t集合以id列为shard key进行ranged sharding
ranged分片直接使用{id:1}方式指定即可,分片的chunk由mongos自主决定,例如在ranged分片集合中插入1000条数据,其结果如下:
for(i=1;i<=1000;i++){db.t.insert({id:i,name:"Leo"})}--sh.status()的相关结果:
test.t
shard key: { "id" : 1 }
unique: false
balancing: true
chunks:
shard1 1
shard2 1
shard3 1
{ "id" : { "$minKey" : 1 } } -->> { "id" : 2 } on : shard1 Timestamp(2, 0)
{ "id" : 2 } -->> { "id" : 22 } on : shard3 Timestamp(3, 0)
{ "id" : 22 } -->> { "id" : { "$maxKey" : 1 } } on : shard2 Timestamp(3, 1)
从sh.status的结果可以看到id为[1,2)的被分配至shard1,[2,22)被分配至shard2,其他的全部被分配至shard3,分布极其不均匀。
由于默认的ranged sharding策略会导致自增shard key分布及其不均匀,我们需要在定时的使用sh.splitAt()方法来为分片指定分片chunk大小:
sh.splitAt("test.t",{id:500})
sh.splitAt("test.t",{id:1000})
sh.splitAt("test.t",{id:1500})
sh.splitAt("test.t",{id:2000})
for(i=1;i<=3000;i++){db.t.insert({id:i,name:"Leo"})}
--sh.status()显示的分片结果如下:
test.t
shard key: { "id" : 1 }
unique: false
balancing: true
chunks:
shard1 2 --shard2上有2个chunks,分别是[1500,2000]和[2000,$maxKey)
shard2 2
shard3 1
{ "id" : { "$minKey" : 1 } } -->> { "id" : 500 } on : shard1 Timestamp(2, 0)
{ "id" : 500 } -->> { "id" : 1000 } on : shard3 Timestamp(3, 0)
{ "id" : 1000 } -->> { "id" : 1500 } on : shard1 Timestamp(4, 0)
{ "id" : 1500 } -->> { "id" : 2000 } on : shard2 Timestamp(4, 1)
{ "id" : 2000 } -->> { "id" : { "$maxKey" : 1 } } on : shard2 Timestamp(3, 3)
tag aware分片策略还未测试,有待以后补充。
7.shards的扩容
当需要水平扩容时我们就需要进行shards添加了,添加步骤如下:(本例在70上直接添加单实例的27022端口的shard实例)
directoryperdb=true
shardsvr = true
logpath=/home/mongod/shard4/mongod.log
logappend=true
fork=true
port=27022
dbpath=/home/mongod/shard4
pidfilepath=/home/mongod/shard4/mongod.pid
启动此实例后,在mongos上执行:
sh.addShard("192.168.20.70:27022")
一段时间后sh.status()看到的结果如下:
test.t
shard key: { "id" : 1 }
unique: false
balancing: true
chunks:
shard1 1
shard0004 1 --mongos自动将新的单实例mongoDB的chunk命名为shard0004
shard2 2
shard3 1
{ "id" : { "$minKey" : 1 } } -->> { "id" : 500 } on : shard0004 Timestamp(5, 0)
{ "id" : 500 } -->> { "id" : 1000 } on : shard3 Timestamp(3, 0)
{ "id" : 1000 } -->> { "id" : 1500 } on : shard1 Timestamp(5, 1)
{ "id" : 1500 } -->> { "id" : 2000 } on : shard2 Timestamp(4, 1)
{ "id" : 2000 } -->> { "id" : { "$maxKey" : 1 } } on : shard2 Timestamp(3, 3)
--可以看到balancer自动将chunk进行了迁移,迁移机制为mongodb内部决定,原理参见第八部分。
八、Sharding的负载均衡(即Balancer)
MongoDB Sharding的自动负载均衡目前是由mongos的后台线程来做的,并且每个集合同一时刻只能有一个迁移任务,负载均衡主要根据集合在各个 shard上chunk的数量来决定的,相差超过一定阈值(跟chunk总数量相关)就会触发chunk迁移。
Balancer默认是开启的,为了避免chunk迁移影响到线上业务,可以通过设置迁移执行窗口,比如只允许凌晨2:00-6:00期间进行迁移。
mongo --port=27019 --连接到mongos
use config
db.settings.update(
{ _id: "balancer" },
{ $set: { activeWindow : { start : "02:00", stop : "06:00" } } },
{ upsert: true }
)
Balancer会在服务器local time的凌晨2-6点才执行chunk的balance。
另外,在进行sharding备份时(通过mongos或者单独备份config server和所有shard),需要停止负载均衡以免备份出来的数据出现状态不一致问题。
sh.setBalancerState("false")
或者:
sh.stopBalancer()
九、其他问题
moveChunk归档设置
使用3.0及以前版本的Sharded cluster可能会遇到一个问题,停止写入数据后,数据目录里的磁盘空间占用还会一直增加。
上述行为是由sharding.archiveMovedChunks配置项决定的,该配置项在3.0及以前的版本默认为true,即在move chunk时,源shard会将迁移的chunk数据归档一份在数据目录里,当出现问题时,可用于恢复。也就是说,chunk发生迁移时,源节点上的空间并没有释放出来,而目标节点又占用了新的空间。
在3.2版本,该配置项默认值也被设置为false,默认不会对moveChunk的数据在源shard上归档。
recoverShardingState设置
使用MongoDB Sharded cluster时,还可能遇到一个问题,就是启动 shard后,shard 不能正常服务,Primary上调用ismaster时,结果却为 true,也无法正常执行其他命令,其状态类似如下:
PRIMARY> db.isMaster()
{
"hosts" : [
"host1:9003",
"host2:9003",
"host3:9003"
],
"setName" : "mongo-9003",
"setVersion" : 9,
"ismaster" : false, // primary 的 ismaster 为 false???
"secondary" : true,
"primary" : "host1:9003",
"me" : "host1:9003",
"electionId" : ObjectId("57c7e62d218e9216c70aa3cf"),
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2016-09-01T12:29:27.113Z"),
"maxWireVersion" : 4,
"minWireVersion" : 0,
"ok" : 1
}
查看其错误日志,会发现shard一直无法连接上config server,上述行为是由sharding.recoverShardingState选项决定,默认为true,也就是说,shard启动时,其会连接config server进行sharding 状态的一些初始化,而如果config server连不上,初始化工作就一直无法完成,导致 shard 状态不正常。
有同学在将Sharded cluster所有节点都迁移到新的主机上时遇到了上述问题,因为config server的信息发生变化了,而shard启动时还会连接之前的config server,通过在启动命令行加上--setParameter recoverShardingState=false来启动shard就能恢复正常了。
上述默认设计的确有些不合理,config server的异常不应该去影响shard,而且最终的问题的表象也很不明确,在3.4大版本里,MongoDB也会对这块进行修改去掉这个参数,默认不会有recoverShardingState的逻辑,具体参考SERVER-24465。











