
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


大数据真好玩
点击右侧关注,大数据真好玩!

Flink作为新一代的大数据处理引擎,不仅是业内公认的最好的流处理引擎,而且具备机器学习等多种强大计算功能,用户只需根据业务逻辑开发一套代码,无论是全量数据还是增量数据,亦或者实时处理,一套方案即可全部解决。K8S是业内最流行的容器编排工具,与docker容器技术结合,可以提供比Yarn与Mesos更强大的集群资源管理功能,成为容器云的主要解决方案之一。如果能将两者结合,无疑是双剑合璧,对生产效能有着巨大的提升。本文将介绍目前为止,Flink On K8S的最前沿实现方案。
Flink集群架构
如下图所示,Flink集群中一个 JobManger 和若干个TaskManager。由 Client 提交任务给 JobManager,JobManager再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的JVM进程。
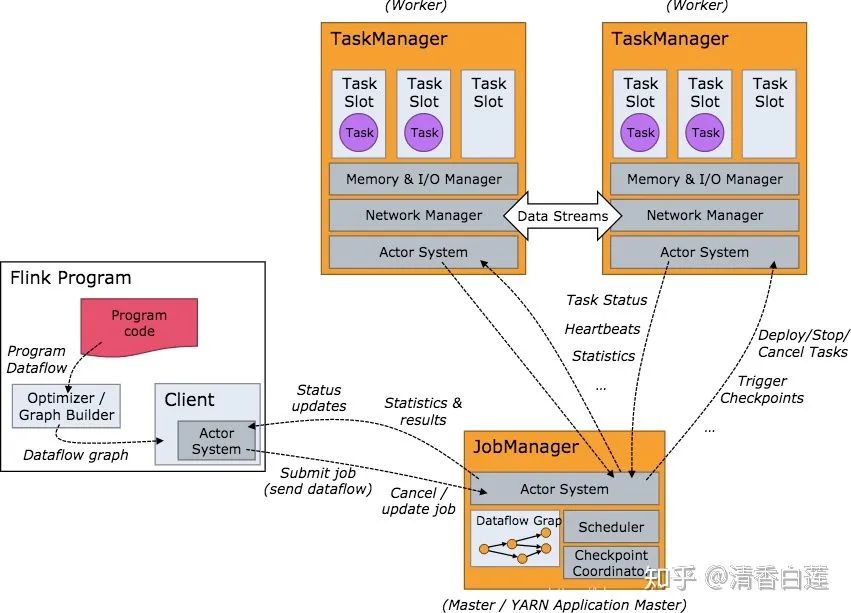
Client是提交Job的客户端,可以是运行在任何机器上(与JobManager 环境连通即可),也可以运行在容器中。提交Job后,Client可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
JobManager主要负责调度Job并协调Task做checkpoint。从Client处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以Task粒度调度到各个TaskManager上去执行。
TaskManager在启动的时候就设置好了槽位数(Slot),每个slot能启动一个Task,Task为线程。从JobManager处接收需要部署的Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
可以看到Flink的任务调度是多线程模型,并且不同Job/Task混合在一个 TaskManager 进程中。
目前在K8S中执行Flink任务的方式有两种,一种是Standalone,一种是原生模式。
Standalone模式
在K8S中启动Flink集群
Flink on Kubernetes 的架构如图所示,Flink 任务在 Kubernetes 上运行的步骤有:
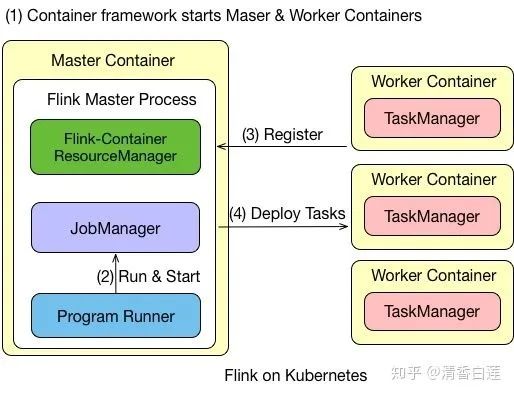
首先往 Kubernetes 集群提交了资源描述文件后,会启动 Master 和 Worker 的 container。
Master Container 中会启动 Flink Master Process,包含 Flink-Container ResourceManager、JobManager 和 Program Runner。
Worker Container 会启动 TaskManager,并向负责资源管理的 ResourceManager 进行注册,注册完成之后,由 JobManager 将具体的任务分给 Container,再由 Container 去执行。
需要说明的是,Master Container 与Worker Container是用一个镜像启动的,只是启动参数不一样,如下图所示,两个deployment文件的image都是flink:latest。

计算任务可以以Session模式与Per-Job模式运行提交:
Session模式:先启动一个Flink集群,然后向该集群提交任务,所有任务共用JobManager。任务提交速度快,适合频繁提交运行的短时间任务。
Per-Job模式:每提交一个任务,单独启动一个集群运行该任务,运行结束集群被删除,资源也被释放。任务启动较慢,适合于长时间运行的大型任务。
Session 模式
在Session模式下,需要先启动一个Flink集群,然后向该集群提交任务,主要步骤为:先将集群配置定义为ConfigMap、然后通过官方资源描述文件分别启动JobManager与一定数量的TaskManager,最后在flink客户端向这个启动的Flink集群中提交任务。
定义ConfigMap
对于 JobManager 和 TaskManager 运行过程中需要的一些配置文件,如:flink-conf.yaml、hdfs-site.xml、core-site.xml,可以通过flink-configuration-configmap.yaml文件将它们定义为 ConfigMap 来实现配置的传递和读取。如果使用默认配置,这一步则不需要。
kubectl create -f flink-configuration-configmap.yaml
启动JobManager
JobManager 的执行过程分为两步:
首先,JobManager 通过 Deployment 进行描述,保证 1 个副本的 Container 运行 JobManager,可以定义一个标签,例如 flink-jobmanager。
kubectl create -f jobmanager-deployment.yaml
其次,还需要定义一个JobManager Service,通过 service name 和 port 暴露 JobManager 服务,通过标签选择对应的 pods。
kubectl create -f jobmanager-service.yaml
启动TaskManager
TaskManager 也是通过 Deployment 来进行描述,保证 n 个副本的 Container 运行 TaskManager,同时也需要定义一个标签,例如 flink-taskmanager。
kubectl create -f taskmanager-deployment.yaml
提交任务
提交服务是通过请求JobManager Service实现的,如果从K8S集群外部请求该Service,需要对外暴露端口
kubectl port-forward service/flink-jobmanager 8081:8081
然后通过flink命令的m参数,指定服务的地址,即可向刚创建的集群中提交任务了。
./bin/flink run -d -m localhost:8081 ./examples/streaming/TopSpeedWindowing.jar
删除集群
直接利用K8S的命令行工具或者API删除前面创建的资源对象即可
kubectl delete -f jobmanager-deployment.yamlkubectl delete -f taskmanager-deployment.yamlkubectl delete -f jobmanager-service.yamlkubectl delete -f flink-configuration-configmap.yaml
Flink on Kubernetes–交互原理
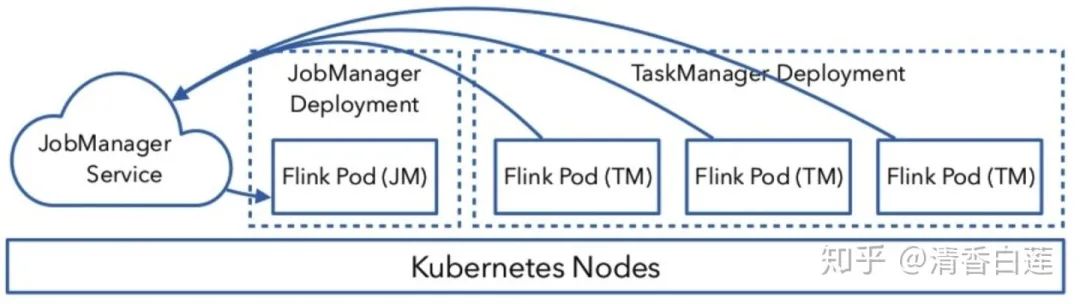
整个交互的流程比较简单,用户往 Kubernetes 集群提交定义好的资源描述文件即可,例如 deployment、configmap、service 等描述。后续的事情就交给 Kubernetes 集群自动完成。Kubernetes 集群会按照定义好的描述来启动 pod,运行用户程序。各个组件的具体工作如下:
Service: 通过标签(label selector)找到 job manager 的 pod 暴露服务。
Deployment:保证 n 个副本的 container 运行 JM/TM,应用升级策略。
ConfigMap:在每个 pod 上通过挂载 /etc/flink 目录,包含 flink-conf.yaml 内容。
Per-Job模式
在官方的Per Job模式下,需要先将用户代码都打到镜像里面,然后根据该镜像来部署一个flink集群运行用户代码,即Flink job cluster。所以主要分为两步:创建镜像与部署Flink job cluster。
创建镜像
在flink/flink-container/docker目录下有一个build.sh脚本,可以根据指定版本的基础镜像去构建你的job镜像,成功后会输出 “Successfully tagged topspeed:latest” 的提示。
sh build.sh --from-release --flink-version 1.7.0 --hadoop-version 2.8 --scala-version 2.11 --job-jar ~/flink/flink-1.7.1/examples/streaming/TopSpeedWindowing.jar --image-name topspeed
镜像构建完成后,可以上传到 hub.docker.com 上,也可以上传到你们项目组的内部Registry。
docker tag topspeed zkb555/topspeedwindowing docker push zkb555/topspeedwindowing
部署Flink job cluster
在镜像上传之后,可以根据该镜像部署Flink job cluster。
# 启动Servivekubectl create -f job-cluster-service.yaml # 启动JobManagerFLINK_IMAGE_NAME=zkb555/topspeedwindowing:latest FLINK_JOB=org.apache.flink.streaming.examples.windowing.TopSpeedWindowing FLINK_JOB_PARALLELISM=3 envsubst < job-cluster-job.yaml.template | kubectl create -f – # 启动TaskManagerFLINK_IMAGE_NAME=zkb555/topspeedwindowing:latest FLINK_JOB_PARALLELISM=4 envsubst < task-manager-deployment.yaml.template | kubectl create -f -
参数说明:
FLINK_DOCKER_IMAGE_NAME- 镜像名称(默认:flink-job:latest)FLINK_JOB- 要执行的Flink任务名称(默认:none)DEFAULT_PARALLELISM- Flink任务的默认并行度 (默认: 1)FLINK_JOB_ARGUMENTS- 其他任务参数;SAVEPOINT_OPTIONS- Savepoint选项 (default: none)
这种方式比较笨重,如果业务逻辑的变动涉及代码的修改,都需要重新生成镜像,非常麻烦,在生产环境提交一个新任务重新打镜像是不切实际的。一种更好的替代方案是将你的业务代码放到NFS或者HDFS上,然后在启动容器时通过挂载或者将jar包下载到容器内的方式执行你的Flink代码,代码位置通过启动参数传入。
需要注意的是Standalone模式需要在任务启动时就确定TaskManager的数量,暂且不能像Yarn一样,可以在任务启动时申请动态资源。然而很多时候任务需要多少个TaskManager事先并不知道,TaskManager设置少了,任务可能跑不起来,多了又会造成资源浪费,需要在任务启动时才能确定需要多少个TaskMananger,为了支持任务启动时实时动态申请资源的功能,就有了下面介绍的原生模式, 这意味着Flink任务可以直接向K8s集群申请资源。
原生模式
原生模式提供了与K8S更好的集成,在Flink 1.9以上版本内置了K8S的客户端,Flink的可以直接向K8S申请计算资源,集群资源得到了更高效的利用。这点与同Flink on Yarn/Mesos一样。
做好以下准备工作就可以从你的flink客户端直接提交flink任务到K8S集群。
KubeConfig, 位于
~/.kube/config,需要具备查看、创建与删除pod与service对象的权限,可以在K8S客户端通过kubectl auth can-i <list|create|edit|delete> pods来验证;Kubernetes开启DNS服务;
一个Kubernetes账户,需要具备创建与删除pod的权限。
原生模式同样支持Session模式玉Per-job两种方式提交任务。
原生Session模式
与Standalone模式中的Session模式类似,还是分为两步,先启动一个集群,然后向集群提交任务。可以通过运行kubernetes-session.sh文件来启动一个集群
./bin/kubernetes-session.sh
或者通过一些超参数来对集群进行设置
./bin/kubernetes-session.sh \ -Dkubernetes.cluster-id=<ClusterId> \ -Dtaskmanager.memory.process.size=4096m \ -Dkubernetes.taskmanager.cpu=2 \ -Dtaskmanager.numberOfTaskSlots=4 \ -Dresourcemanager.taskmanager-timeout=3600000
然后在flink客户端,通过flink命令提交任务
./bin/flink run -d -e kubernetes-session -Dkubernetes.cluster-id=<ClusterId> examples/streaming/WindowJoin.jar
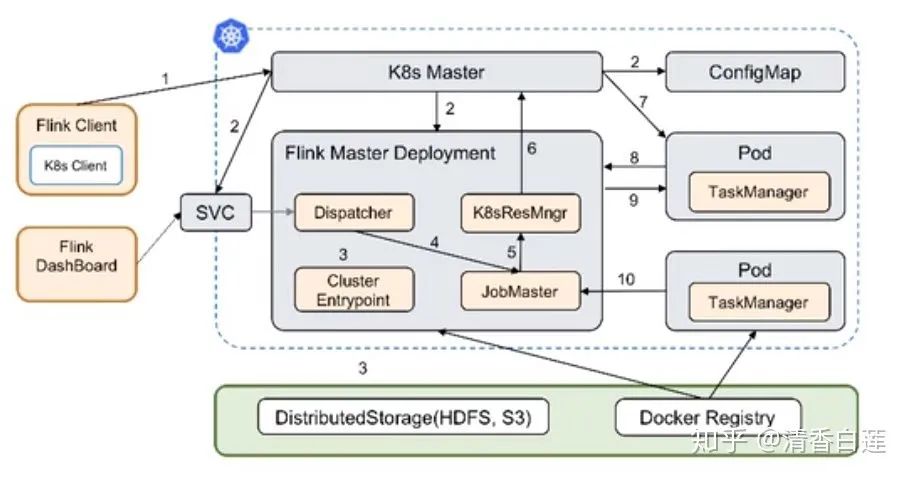
原生Session cluster的创建流程为:
Flink客户端先通过K8S的ApiServer提交cluster的描述信息,包括ConfigMap spec, Job Manager Service spec, Job Manager Deployment spec等;
K8S接收到这些信息后就会拉取镜像、挂载卷轴来启动Flink master,这时候Dispatcher 与KubernetesResourceManager也会被启动,从而可以接受Flink job;
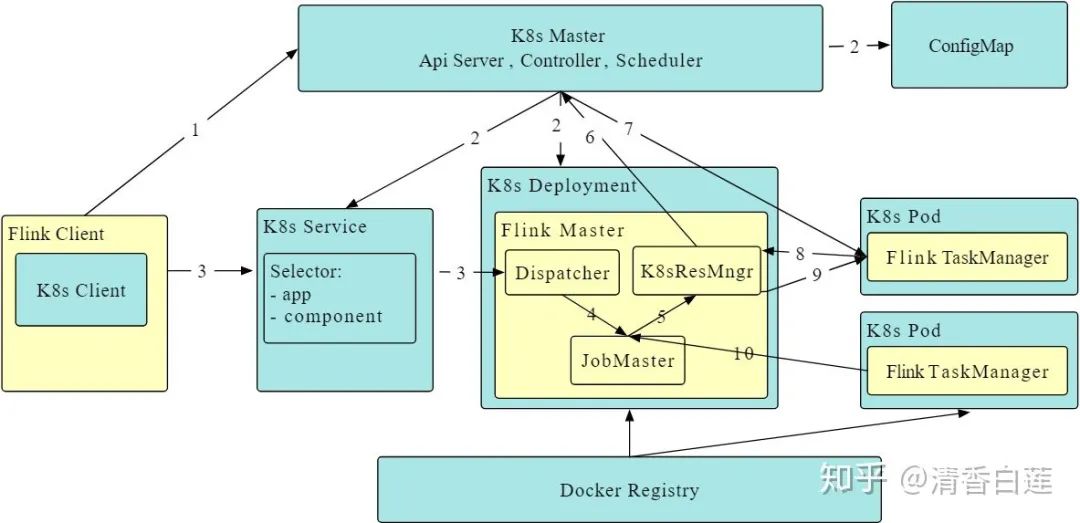
当用户通过Flink客户端提交一个job时,客户端就会生成这个job的job graph,并与这个job的jar包一起提交到Dispatcher,然后就会生成这个job的JobMaster;
最后JobMaster会向KubernetesResourceManager申请slot来执行这个job graph,如果集群中slot数量不够,KubernetesResourceManager会启动新的TaskManager pod并将它注册到集群中。
原生Per-Job模式
目前尚处于实验阶段,在Flink 1.11版本中才支持。
官方的使用方式也是与前面Standalone-Per-Cluster模式类似,先创建一个包含用户jar的用于启动Flink Master的docker image,然后在客户端通过flink命令根据该image提交任务,从而创建一个运行该任务的独立集群。
./bin/flink run -d -e kubernetes-per-job -Dkubernetes.cluster-id=<ClusterId> -Dtaskmanager.container.image=<your image> -Dtaskmanager.memory.process.size=4096m \ -Dkubernetes.taskmanager.cpu=2 \ -Dtaskmanager.numberOfTaskSlots=4 \ -Dresourcemanager.taskmanager-timeout=3600000 -Dkubernetes.container-start-command-template="%java% %classpath% %jvmmem% %jvmopts% %logging% %class% %args%"
Per-Job模式的运行过程与Session模式的不同点在于Flink Master的启动,其他步骤都一样。Flink Master Deployment里面已经有Flink任务的jar包,在启动Flink Master时Cluster Entrypoint就会运行该jar包的main函数产生job graph,并将该job graph与jar包提交给Dispatcher。
当然这种方式的缺点与Standalone-Per-Cluster一样,每个用户jar都需要一个单独的镜像,实际还是建议将用户jar放在外部,在运行时挂载或者下载到容器中。
总结
本文介绍了Flink on K8S的各种方案,鉴于不需要事先指定taskmanager数量,原生模式相对于Standalone模式更有优势,但目前尚处于实验阶段。他们两者都支持Session模式与Per-Job模式,至于选择哪种,看你实际的任务类型。如果式以频繁提交的短期任务,如批处理为主,则适合Session模式,如果以长期运行的流式任务为主,则适合用Per-Job模式。
REFERENCE:https://zhuanlan.zhihu.com/p/141152885


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











