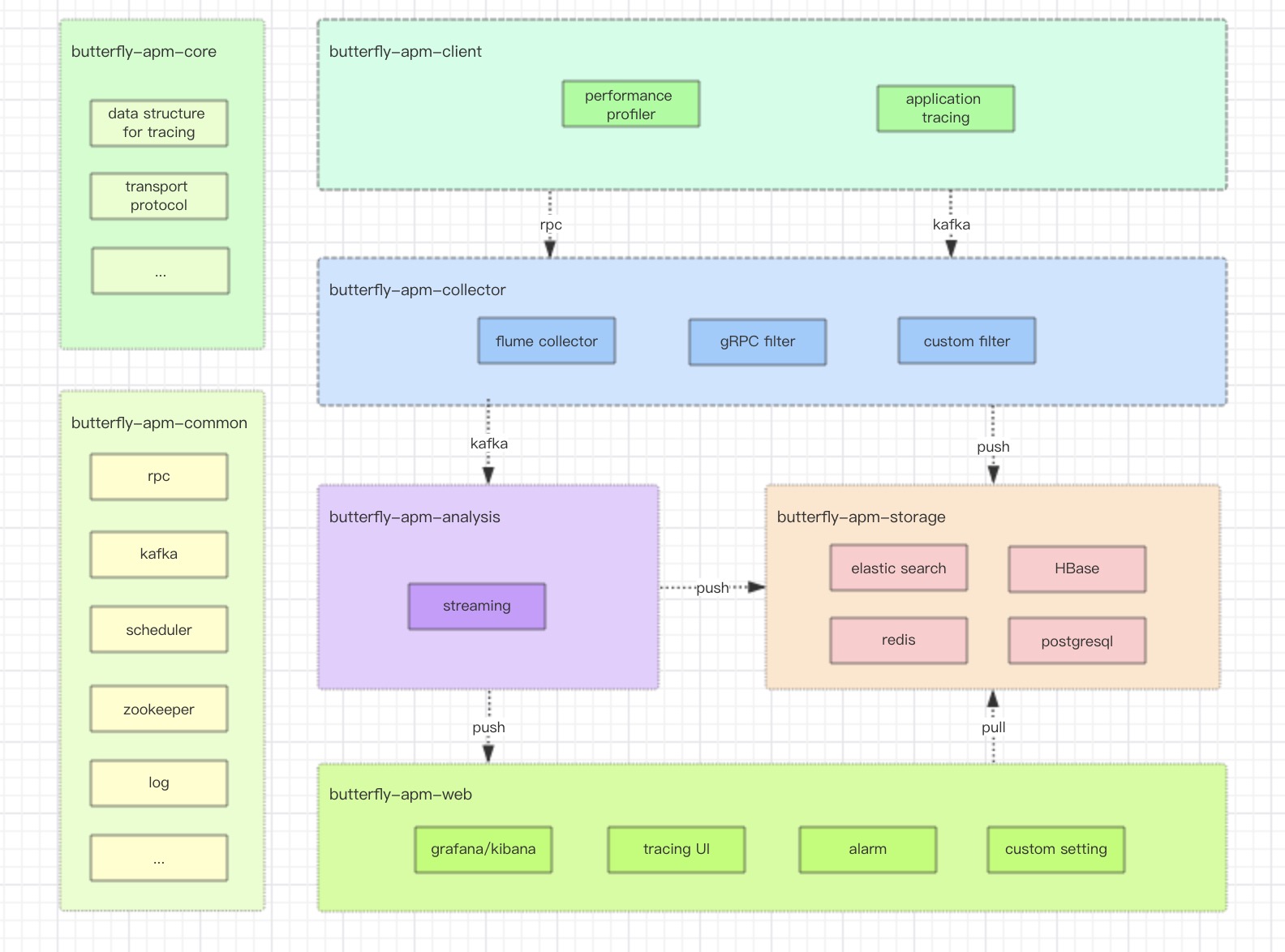
0. 技术选型参考
1. Collector
Keywords: Collector, Processor
名称
Beats
Fluentd-bit
Introduction
Beats are a collector and processor of lightweight (resource efficient, no dependencies, small) and open source log shippers that act as agents installed on the different servers in your infrastructure for collecting logs or metrics.
Fluent Bit was born to address the need for a high performance and optimized tool that can collect and process data from any input source, unify that data and deliver it to multiple destinations.
Owner
Elastic
Treasure Data
Open Source
True
True
Github Stars
5742
608
License
Apache License v2.0
Apache License v2.0
Scope
Containers / Servers / K8S
Containers / Servers / K8S
Language
Go
C
Memory
~10MB
~500KB
Performance
High
High
Dependencies
Zero dependencies, unless some special plugin requires them.
Zero dependencies, unless some special plugin requires them.
Category
Auditbeat,Filebeat,Heartbeat,Metricbeat,Packetbeat,Winlogbeat
NaN
Configuration
File(.yml)/Cmd
File(custom file extension and syntax)/Cmd
Essence
Collector & Processor
Collector & Processor
Input/Module
File, Docker, Syslog, Nginx, Mysql, Postgresql, etc
File,CPU, Disk, Docker, Syslog, etc
Output
Elasticsearch, Logstash, Kafka, Redis, File, Console
ES, File, Kafka, etc
1.1 Filebeat 架构图
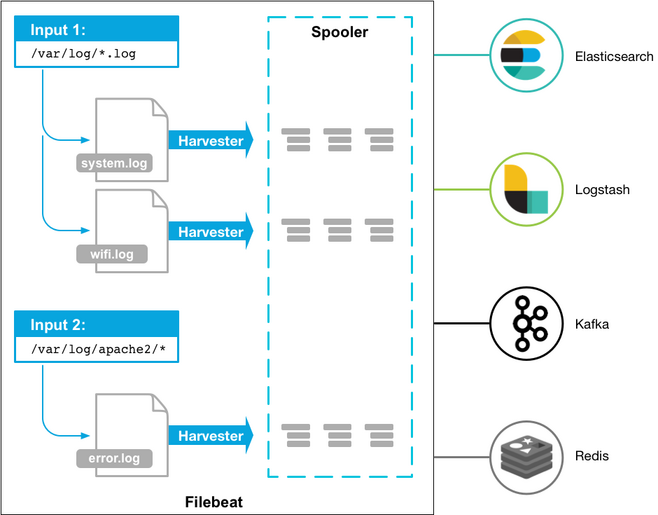
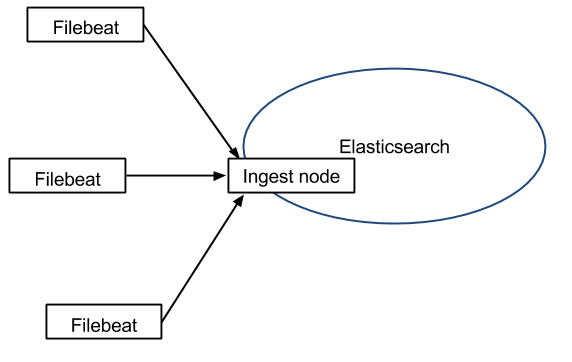
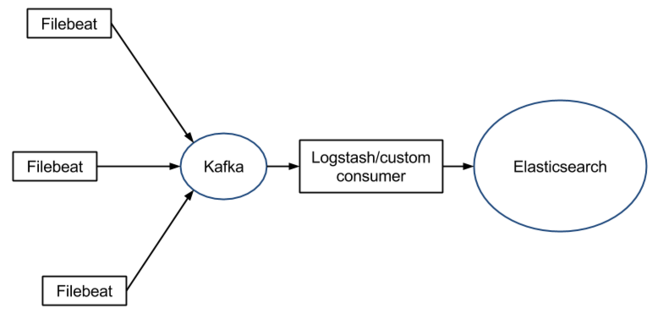
- Ingest Node - A es plugin which pre-process documents before the actual document indexing happen and replace for Logstash. The ingest node intercepts bulk and index requests, it applies transformations, and it then passes the documents back to the index or bulk APIs. Define a pipeline(Processors) that specifies a series of processors, then register the pipeline id in Filebeat configuration file.
- Kafka - Prevent loss of data and manage logging output speed.
1.2 Fluent bit 架构图

Name
Description
Samples
Input
Entry point of data. Implemented through Input Plugins, this interface allows to gather or receive data.
Parser
Parsers allow to convert unstructured data gathered from the Input interface into a structured one. Parsers are optional and depends on Input plugins.
Prospector and processors in Filebeat
Filter
The filtering mechanism allows to alter the data ingested by the Input plugins. Filters are implemented as plugins.
Prospector and processors in Filebeat
Buffer
By default, the data ingested by the Input plugins, resides in memory until is routed and delivered to an Output interface.
Routing
Data ingested by an Input interface is tagged, that means that a Tag is assigned and this one is used to determinate where the data should be routed based on a match rule.
Output
An output defines a destination for the data. Destinations are handled by output plugins. Note that thanks to the Routing interface, the data can be delivered to multiple destinations.
2. Log Transporter
Keywords: Collector, Processor, Aggregator
名称
Logstah
Fluentd
Introduction
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your stash.
Fluentd is an open source data collector, which lets you unify the data.
Owner
Elastic
Treasure Data
Open Source
True
True
Github Stars
9105
6489
License
Apache License v2.0
Apache License v2.0
Scope
Containers / Servers / K8S
Containers / Servers / K8S
Language
JRuby(JVM)
Ruby & C
Memory
200MB+
~40MB
Performance
Middle
High
Dependencies
JVM
Ruby Gem
Configuration
File(custom file extension and syntax)/Cmd
File(custom file extension and syntax)/Cmd
Essence
Collector, Processor, Aggregator
CCollector, Processor, Aggregator
Input/Module
Limited only by your imagination(Serilog)
Limited only by your imagination(Nlog)
Output
Limited only by your imagination
Limited only by your imagination
Further Reading: Fluentd vs. Logstash: A Comparison of Log Collectors
3. 初步总结
比较
Beats + Logstash
Fluentd bit + Fluentd
说明
功能实现
√
√
基本一致
安装与配置简易性
√
内存占用
√
JVM 特性使然
可靠性
√
√
前者使用 registry file + redis 实现可靠性,后者使用内置 buffering 实现可靠性
可扩展性
√
√
插件生态和可扩展性基本一致。后者为分布型插件管理
趋势
√
ELK -> EFK
其他
√
√
前者更倾向于使用 go & java 技术栈,后者有 docker, k8s 官方 log driver 类型和案例支持
Tips: 任一层级都可以自由替换.
4. Visualizer
Keywords: Query, Analyze, Monitor
名称
Kibana
Grafana
Introduction
Kibana is an open source data visualization plugin for Elasticsearch.
Data visualization & Monitoring with support for Graphite, InfluxDB, Prometheus, Elasticsearch and many more databases.The leading open source software for time series analytics.
Owner
Elastic
Grafana
Open Source
True
True
Github Stars
9k+
22k+
License
Apache License v2.0
Apache License v2.0
Scope
ElasticSearch only
ElasticSearch, InfluxDB, PostgreSQL etc
Language
Javascript
Go & Typescript
Configuration
File(.yml)/Cmd
File(custom file extension and syntax)/Cmd
Simple Query
Lucene syntax and filter components
filter components.Different from each other data source
Full-Text Query
Yes
No
Security
Plugins or libraries
Integration
Notification
Plugins or libraries
Integration
Advantages
Log, ES
Multiple data source, APM, Timeseries
Working together.
5. Log Storage and Analyzer
Keywords:Storage, ES, Postgresql, Zombodb, Arangodb
5.1 ElasticSearch
- 同时支持单文档的对象搜索+模糊搜索+全文搜索
- Skywalking 官方支持存储媒介
- 作为流行 Output 支持绝大部分 Log 相关系统
- 天生分布式
- 一键设置过期窗口,索引重建
- ……
- 占用资源较多,对存储介质要求高
- 运维成本更高
- 持久化
- 安全性 - Search Guard
- ……
6. 总结
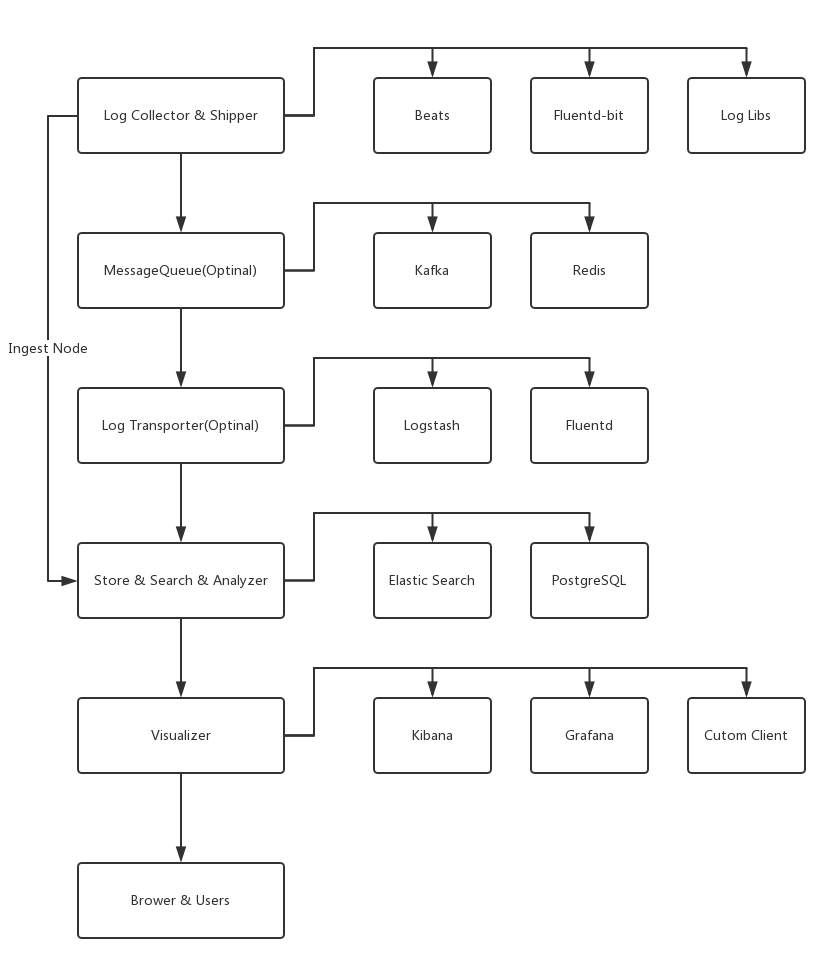
- Sinks(Log sinks, Beats, Fluentd-bit) -> Storages(ElasticSearch, Postgresql,Zombodb etc).
- Collctors(Beats, Fluentd-bit) -> Kafka -> Fluentd -> Storages(ElasticSearch, Postgresql,Zombodb etc).
7. 扩展