
一、GraphLab
示例1:GraphLab完成对V0邻接顶点的求和计算
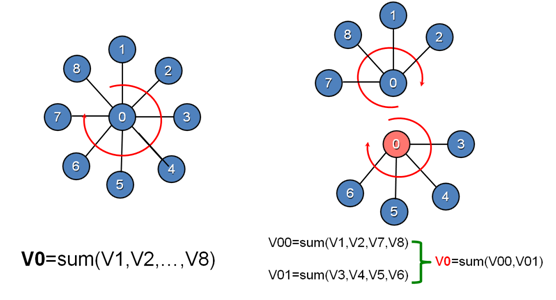
示例中,需要完成对V0邻接顶点的求和计算,串行实现中,V0对其所有的邻接点进行遍历,累加求和。而GraphLab中,将顶点V0进行切分,将V0的边关系以及对应的邻接点部署在两台处理器上,各台机器上并行进行部分求和运算,然后通过master顶点和mirror顶点的通信完成最终的计算。
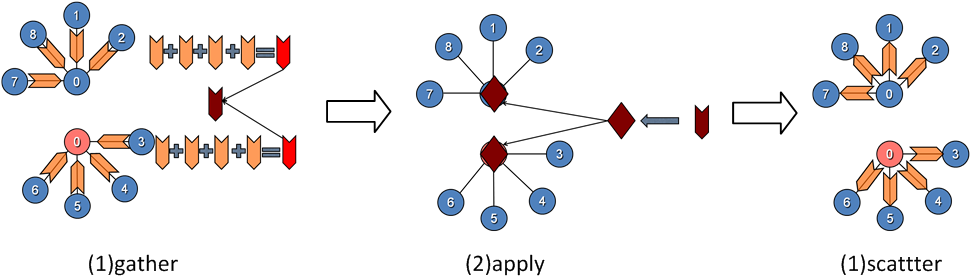
每个顶点每一轮迭代经过gather->apple->scatter三个阶段。
1) Gather阶段
工作顶点的边 (可能是所有边,也有可能是入边或者出边)从领接顶点和自身收集数据,记为gather_data_i,各个边的数据graphlab会求和,记为sum_data。这一阶段对工作顶点、边都是只读的。
2) Apply阶段
Mirror将gather计算的结果sum_data发送给master顶点,master进行汇总为total。Master利用total和上一步的顶点数据,按照业务需求进行进一步的计算,然后更新master的顶点数据,并同步mirror。Apply阶段中,工作顶点可修改,边不可修改。
3) Scatter阶段
工作顶点更新完成之后,更新边上的数据,并通知对其有依赖的邻结顶点更新状态。这scatter过程中,工作顶点只读,边上数据可写。
在执行模型中,graphlab通过控制三个阶段的读写权限来达到互斥的目的。在gather阶段只读,apply对顶点只写,scatter对边只写。并行计算的同步通过master和mirror来实现,mirror相当于每个顶点对外的一个接口人,将复杂的数据通信抽象成顶点的行为。
下面这个例子说明GraphLab的执行模型:
================================================================
分割线
================================================================
二、Pregel
实例二

从图中可以看出,数值6是图中的最大值,在第0步超级步中,所有的节点都是活跃的,系统执行用户函数_F_(vertex):节点将自身的数值通过链接关系传播出去,接收到消息的节点选择其中的最大值,并和自身的数值进行比较,如果比自身的数值大,则更新为新的数值,如果不比自身的数值大,则转为不活跃状态。
在第0个超级步中,每个节点都将自身的数值通过链接传播出去,系统进入第1个超级步,执行_F_(vertex)函数,第一行和第四行的节点因为接收到了比自身数值大的数值,所以更新为新的数值6。第二行和第三行的节点没有接收到比自身数值大的数,所以转为不活跃状态。在执行完函数后,处于活跃状态的节点再次发出消息,系统进入第2个超级步,第二行节点本来处于不活跃状态,因为接收到新消息,所以更新数值到6,重新处于活跃状态,而其他节点都进入了不活跃状态。Pregel进入第3个超级步,所有的节点处于不活跃状态,所以计算任务结束,这样就完成了整个任务,最大数值通过4个超级步传递给图中所有其他的节点。算法14.1是体现这一过程的Pregel C++代码。

三、GraphLab和Pregel中Vertex区别
GraphLab
Pregel
操作
GetValue()
四、数据同步(消息)
GraphLab
Pregel
mirror (sync_vertex_data())
SendMessageToAllNeighbors()
SendMessageTo()
五、
有一个重要的区别在Pregel和GraphLab之间,动态计算是如何表达的。GraphLab从数据的移动中分离了未来计算的调度。作为结果,GraphLab更新函数可以访问数据在相邻的顶点,即使相邻顶点没有调用当前的更新。相反,Pregel更新函数通过消息初始化并且只能访问在消息中的数据,限制了所能表达的内容。例如,动态PageRank是很困难的表达在Pregel上, 计算给定页面PageRank值需要的所有相邻的PageRank值,即使所有相邻的页面最近的一些相邻的页面并没有改变。因此,发送数据 (PageRank值)给相邻的顶点的决定不能由发送顶点来做出(根据Pregel的要求),但必须由接收顶点决定。GraphLab,自然表示了抽取模型,由于相邻顶点只负责调度和更新函数,可以直接读取相邻定点的值,即使他们没有改变顶点值。










