
Kafka 入门和 Spring Boot 集成
概述
kafka 是一个高性能的消息队列,也是一个分布式流处理平台(这里的流指的是数据流)。由java 和 Scala 语言编写,最早由 LinkedIn 开发,并 2011年开源,现在由 Apache 开发维护。
应用场景
下面列举了一些kafka常见的应用场景。
消息队列 : Kafka 可以作为消息队列使用,可用于系统内异步解耦,流量削峰等场景。
应用监控:利用 Kafka 采集应用程序和服务器健康相关的指标,如应用程序相关的日志,服务器相关的 CPU、占用率、 IO、内存、连接数、 TPS、 QPS等,然后将指标信息进行处理,从而构建一个具有监控仪表盘、曲线图等可视化监控系统。 例如, 很多公司采用 Kafka 与 ELK(ElasticSearch、 Logstash 和Kibana)整合构建应用服务的监控系统。
流处理:比如将 kafka 接收到的数据发送给 Storm 流式计算框架处理。
基本概念
record(消息):kafka 通信的基本单位,每一条消息称为record
producer (生产者 ):发送消息的客户端。
consumer(消费者 ):消费消息的客户端。
consumerGroup (消费者组):每一个消费者都属于一个特定的消费者组。
消费者和消费者组的关系:
- 如果a,b,c 属于同一个消费者组,那一条消息只能被 a,b,c 中的某一个消费者消费。
- 如果a,b,c 属于不同的消费者组(比如 ga,gb,gc) ,那一条消息过来,a,b,c 三个消费者都能消费到。
topic (主题): kafka的消息通过topic来分类,类似于数据库的表。 producer 发布消息到 topic,consumer订阅 topic 进行消费
partition( 分区):一个topic会被分成一到多个分区(partition),然后多个分区可以分布在不同的机器上,这样一个主题就相当于运行在了多台机子上,kafka用分区的方式提高了性能和吞吐量
replica (副本):一个分区有一到多个副本,副本的作用是提高分区的 可用性。
offset(偏移量):偏移量 类似数据库自增int Id,随着数据的不断写入 kafka 分区内的偏移量会不断增加,一条消息由一个唯一的偏移量来标识。偏移量的作用是,让消费者知道自己消费到了哪个位置,下次可以接着从这里消费。如下图: 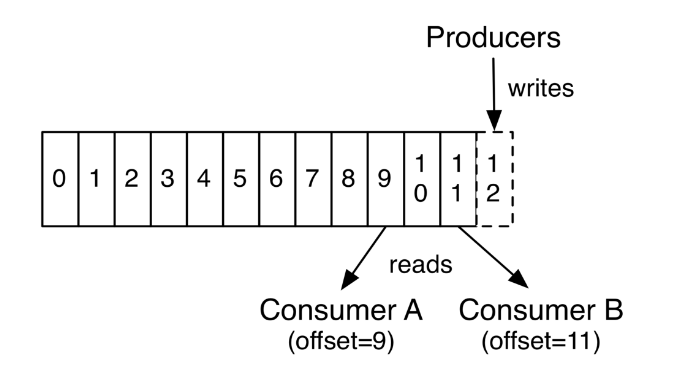 消费者A 消费到了 offset 为 9 的记录,消费者 B 消费到了offset 为 11 的记录。
消费者A 消费到了 offset 为 9 的记录,消费者 B 消费到了offset 为 11 的记录。
基本结构
kafka 最基本的结构如下,跟常见的消息队列结构一样。 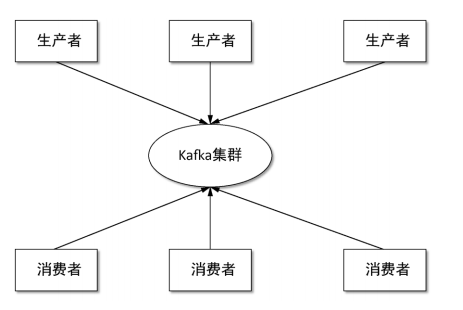 消息通过生产者发送到 kafka 集群, 然后消费者从 kafka 集群拉取消息进行消费。
消息通过生产者发送到 kafka 集群, 然后消费者从 kafka 集群拉取消息进行消费。
和Spring Boot 集成
集成概述
本集成方式采用的是 spring boot 官方文档说的集成方式,官方链接,集成的大体思路是,通过在 spring boot application.properties 中配置 生产者和消费者的基本信息,然后spring boot 启动后会创建 KafkaTemplate 对象,这个对象可以用来发送消息到Kafka,然后用 @KafkaListener 注解来消费 kafka 里面的消息,具体步骤如下。
集成环境
spring boot:1.5.13 版本 spring-kafka:1.3.5 版本 kafka:1.0.1 版本
kafka 环境搭建
先启动Zookeeper:
docker run -d --name zookeeper --publish 2181:2181 --volume /etc/localtime:/etc/localtime zookeeper:latest
再启动Kafka:替换下面的IP为你服务器IP即可
docker run -d --name kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --env KAFKA_ADVERTISED_HOST_NAME=192.168.10.253 --env KAFKA_ADVERTISED_PORT=9092 --volume /etc/localtime:/etc/localtime wurstmeister/kafka:1.0.1
Spring Boot 和 Spring for Apache Kafka 集成步骤
首先pom中引入 Spring for Apache Kafka
org.springframework.kafka spring-kafka 1.3.5.RELEASE 然后 application.properties 配置文件中加入如下配置: 各个配置的解释见:spring boot 附录中的 kafka 配置,搜索kafka 关键字即可定位。
server.port=8090
####### kafka
producer 配置
spring.kafka.producer.bootstrap-servers=192.168.10.48:9092 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
consumer 配置
spring.kafka.consumer.bootstrap-servers=192.168.10.48:9092 spring.kafka.consumer.group-id=anuoapp spring.kafka.consumer.enable-auto-commit=true spring.kafka.consumer.auto-commit-interval=100 spring.kafka.consumer.max-poll-records=1 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.listener.concurrency=5
创建 Kafka Producer 生产者
package com.example.anuoapp.kafka;
import com.alibaba.fastjson.JSON; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import org.springframework.util.concurrent.ListenableFuture;
@Component public class KafkaProducer { @Autowired KafkaTemplate kafkaTemplate; public void kafkaSend() throws Exception { UserAccount userAccount=new UserAccount(); userAccount.setCard_name("jk"); userAccount.setAddress("cd"); ListenableFuture send = kafkaTemplate.send("jktopic", "key", JSON.toJSONString(userAccount)); } }
创建 Kafka Consumer 消费者
package com.example.anuoapp.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component;
@Component public class KafkaConsumer {
public static final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class); @KafkaListener(topics = {"jktopic"}) public void jktopic(ConsumerRecord consumerRecord) throws InterruptedException { System.out.println(consumerRecord.offset()); System.out.println(consumerRecord.value().toString()); Thread.sleep(3000); }}
创建一个rest api 来调用 Kafka 的消息生产者
package com.example.anuoapp.controller;
import com.example.anuoapp.kafka.KafkaProducer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController;
@RestController @RequestMapping("/api/system") public class SystemController { private Logger logger = LoggerFactory.getLogger(SystemController.class); @Autowired KafkaProducer kafkaProducer; @RequestMapping(value = "/Kafka/send", method = RequestMethod.GET) public void WarnInfo() throws Exception { int count=10; for (int i = 0; i < count; i++) { kafkaProducer.kafkaSend(); } } }
用 post man 调用 第 5 步创建的接口, 就可以看到 如下消费者产生的输出信息
30 {"address":"cd","bind_qq":false,"bind_weixin":false,"card_name":"jk","passwordDirectCompare":false} 31 {"address":"cd","bind_qq":false,"bind_weixin":false,"card_name":"jk","passwordDirectCompare":false} 32 {"address":"cd","bind_qq":false,"bind_weixin":false,"card_name":"jk","passwordDirectCompare":false}
最后
恭喜你 ! spring boot kafka 集成完毕。
完整的基础源码见: 链接: https://pan.baidu.com/s/1E2Lmbj9A9uruTXG54uPl_g 密码: e6d6
踩过的坑
集成 spring kafka的时候注意版本要选对 ,目前spring boot 1.5.1 对应集成 spring kafka 1.x 版本 , 如果直接集成 spring kafka 2.x 版本 的话会报错, 要用 spring kafka 2.x 的话, 需要升级spring boot 到 2.x 版本。
消费者配置的时候 spring.kafka.consumer.max-poll-records=1 ,轮询拉取的最大记录数要设置成1,不然会出现重复消费,即:如果消费者程序崩了,再启动起来,会消费到以前消费过的数据,造成重复消费。 设置成 1 就没得这个问题了, 不知道是不是 spring kafka 这个lib封装得有问题。












