
一直想写一篇关于数据中台正面文章,现在有闲时做些总结,想充分诠释一下DT内部人如何看待数据中台。
数据中台的概念是最早由阿里巴巴首次提出,是为了应对内部众多业务部门千变万化的数据需求和高速时效性的要求而成长起来的,它既要满足业务部门日常性的多个业务前台的数据需求,又要满足像双十一,六一八这样的业务高峰、应对大规模数据的线性可扩展问题、应对复杂活动场景业务系统的解耦问题,而在技术、组织架构等方面采取的一些变革。
数据中台的定义
阿里巴巴数据中台是阿里云上实现数据智能的最佳实践,它是由数据中台方法论+组织+工具所组成,数据中台方法论采用实现企业数据的全局规划设计,通过前期的设计形成统一的数据标准、计算口径,统一保障数据质量,面向数据分析场景构建数据模型,让通用计算和数据能沉淀并能复用,提升计算效能;数据中台的建设实施必须有能与之配合的组织,不仅仅相应岗位的人员要配备齐全,而且组织架构建设也需要对应,有一个数据技术部门统筹企业的数字化转型,数据赋能业务中形成业务模式,在推进数字化转型中实现价值;数据中台由一系列的工具和产品组成,阿里云数据中台以智能数据构建与管理Dataphin产品、商业智能QuickBI工具和企业参谋产品为主体等一系列工具组成。

阿里云在过去几年中经过数十个实际项目沉淀形成实施标准化流程和方法论。阿里云OneData数据中台解决方案基于大数据存储和计算平台为载体,以OneModel统一数据构建及管理方法论为主干,OneID核心商业要素资产化为核心,实现全域链接、标签萃取、立体画像,以数据资产管理为皮,数据应用服务为枝叶的松耦性整体解决方案。其数据服务理念根植于心,强调业务模式,在推进数字化转型中实现价值。
数据中台的概念来自于阿里巴巴“大中台,小前台”业务战略下的数据化实践,它是关于“数据价值化和数据资产化”的一整套解决方案,内容包括数据中台方法论,组织,数据产品三个方面。
数据中台建设成果主要体现在两方面:一个是数据的技术能力,另一个是数据的资产。今天阿里的各个业务都在共享同一套数据技术和资产。阿里内部为这个统一化的数据体系命名为“OneData”。Onedata体系包括OneModel,OneID,OneService3个方面,在OneData体系之下,不断扩大的业务版图内的各种业务数据,都将按统一的方式接入中台系统,之后通过统一化的数据服务反哺业务。
如下图所示:
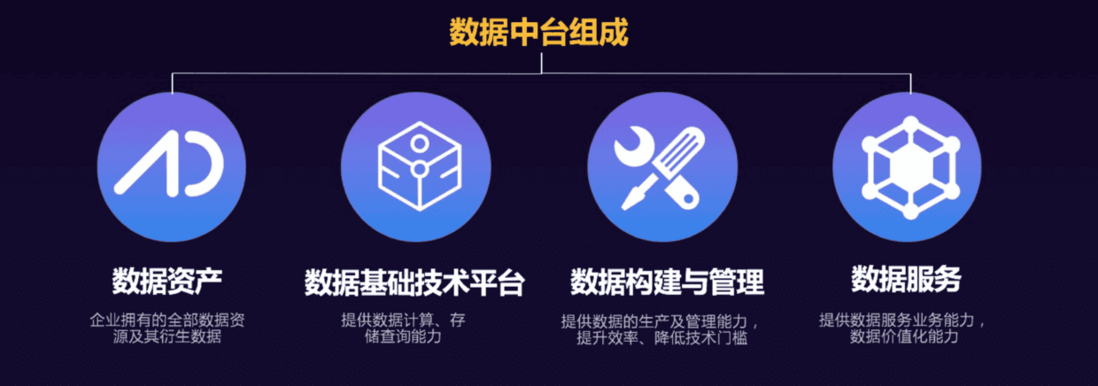
数据中台顶层设计
数据中台定位于计算后台和业务前台之间,其关键职能与核心价值是大数据以业务视角而非纯技术视角出发,智能化构建数据、管理数据资产与提供数据调用、数据监控、数据分析与数据展现等多种服务。承技术启业务,是建设智能数据和催生数据智能的引擎;而以数据中台内核价值为中段的数据中台业务模式不是纯数据、不是纯技术、也不是纯业务,它同时关注着与大数据能力相关的上下游,以大数据为中轴线,基于技术而又深入业务,它以数据产品+数据技术+方法论+场景实现的综合性输出,同时为智能化数据、技术极致提升和数据智能化业务负责。
一方面专注于从业务视角,建设标准统一、融会贯通、资产化、服务化、闭环自优化的数据中台智能数据体系,同时极致化追求技术上的降本提效。另一方面,致力于智能数据与业务场景深度融合的业务数据化与数据业务化中的各类智能化价值创新。
数据中台与传统数据仓库差异
数据仓库已经经历了40多年的发展,广泛应用于大型商业企业,帮助业务人员和高层人员做分析和决策,它起源于决策支持系统(decision support system),其展现形式更多以报表方式实现。因此数据仓库是一个面向主题的、集成的、非易失性的,随时间变化的用来支持管理人员决策的数据集合。
传统的企业级数仓还是以TD,Oracle,IBM/DB2等传统数据库为主, 由于受限于数据的处理能力,很少有EDW的数据容量超过1TB,因此不能对基础数据进行跨域的处理(原因是RMDBS对大数据量的关联join处理耗时非常长),因此要对新的指标分析的时候需要从基础数据重新生成汇总表,耗时耗力,使用方法上无法实现跨数据集或数据域的处理。新一代的数据仓库采用分布式架构,一般基于MPP数据库或大数据平台实现数据分析,因此传统的数据仓库具有以下几个特点:
- 业务主题性:传统的数仓要求解决服务问题,比如对一个生产型企业来说公司的主题域是产品、订单、销售商、材料等,要解决应用问题可能是库存、销售、销售商等。其有业务是面向主题的。
- 系统集成性:在传统数据仓库中,集成是最重要的,由于计算和存储的成本原因,其数据需要从不同的数据源抽取过来并集中,其数据的冗余度需要尽可能的降低,因此数据进入数据仓库中需要进行转化、格式化、重新排列和汇总等操作,其所有数据具有单一物理特性,都是结构化方式存在。在系统架构方面,也是以集中式存储和计算方式存在,新一代的数仓采用分布式计算,但软件产品采用集中部署方式存在。
- 非易失性:数仓系统会记录所有记录,与业务系统相比,它不会对记录进行变化操作(update和delete),它会保留所有记录的变化,但受限于成本和计算能力考虑,数仓不会记录全量明细数据,特别是日志数据,因此大部分数仓平台的数据容量在TB级别。
- 时间变化性:数据仓库中每个数据单元只是在某一时间是准确的,因此数据单元的准确性与时间相关,数据仓库中的数据时间范围5-10年。
- 系统一体化: 传统数仓以系统整体设计为特性,软件平台围绕着数据库或计算平台以整套服务为主,结合度缜密,对外服务也较单一。
传统的数仓采用集
中式数据库作为数据和计算平台,近10年来,新兴企业采用分布式数据库和大数据技术实现OLAP类数仓建设,但其本质还是基于一个整体来考虑的。
在系统和服务上数据中台与传数仓有很多明显的区别,首先表现在服务对象方面,传统的数仓只是满足领导数据决策的需要,因此更多的体现在报表输出,使用者以小部分的业务人员和决策层为主,新需求的开发周期以月甚至到年为计。而数据中台由于起家于互联网企业,其使用对象扩大到一线服务人员和商家企业,其业务需求更繁杂,很难用一套报表系统满足需求,因此催生出一个生态的数据服务。
其次是体系架构上,数据中台是由多系统组成,除了计算平台外,其方案由多个分布式服务系统提供,满足不同业务需求和高并发和系统自动扩容需求,除了大数据存储和计算平台外,还包含数仓建设、工作台开发IDE、任务调度、数据同步服务、对外统一数据服务、资产管理系统、实时流计算平台和开发平台、oneID计算和查询模块,敏捷BI报表开发等多个组件,通过多个维度组件组成一整套方案。
再则,在服务表现形式上数据中台体现的更多样化,数据中台不仅能提供报表基础服务功能,而且为了满足各个业务部门不同需求,会提供领导决策系统、行业分析、业务洞察、业务重塑,自助查询等多个功能,满足从领导层、PD、业务人员、开发人员等各个层级的需求。
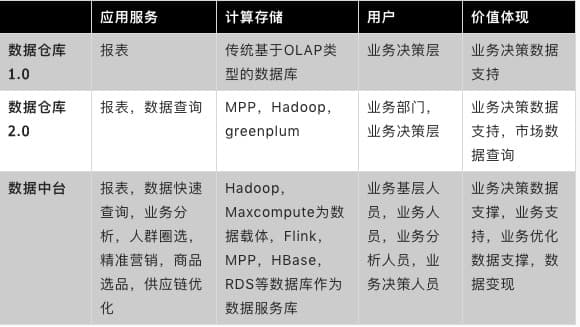
在继承性方面,数据中台采用传统的数仓Kimball维度建模法,按照事实表,维表来构建数据中台的数据模型。
数据中台与数据湖区别
业界近3年对datalake说的比较多,是结合近10年来大数据理念兴起的,首次由Dan Woods在2011年7月福布斯上的“Big Data Requires a Big, New Architecture”中提出,它提出CIO们应该考虑数据湖(“Data lake”)这个思维方式来替代数据仓库(“data warehouse”)的思维,它的架构和理念是把原先不存储的基础数据也存储起来,汇总各个数据源的数据方便以后的数据分析和查询,因此数据湖是数据的聚集、加工为目的数据资源池,但是数据湖只是解决了聚集问题,在数据加工方面由于不可控制的需求变得异常繁重,由于数据的繁杂和混乱引入数据治理让数据的加工更是举步维艰。
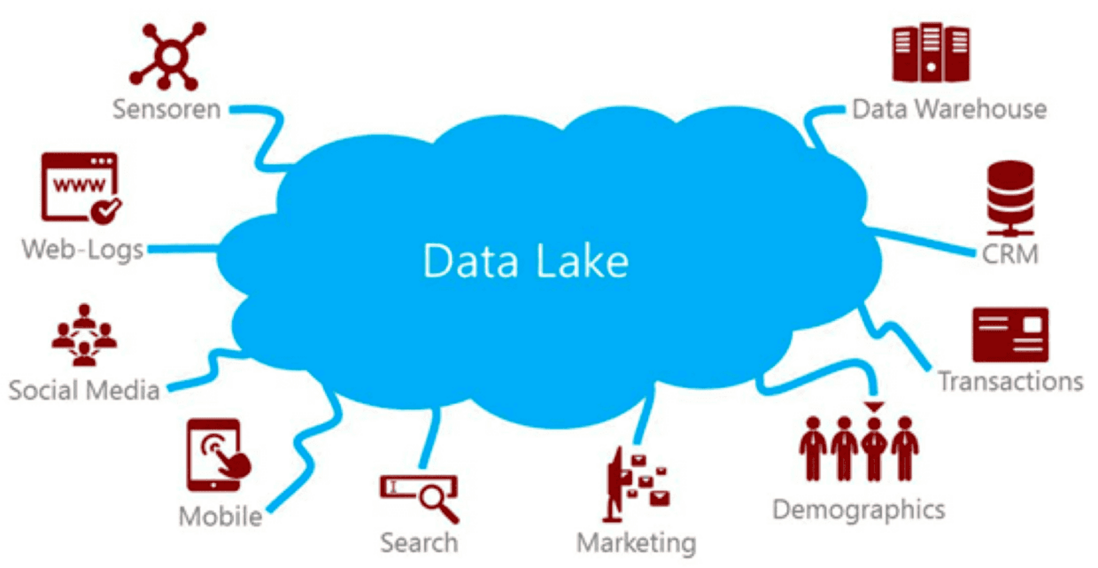
传统上数据湖中的数据会存储原始数据,量大并且非结构化和半结构化的数据较多,需要有一个低成本分布式存储和计算架构来承载这些数据,属于ODS层,缺乏数据主题和加工能力,因此近期对数据湖上的数据治理项目和应用越来越多。
数据湖汇集了原始ODS数据,解决了传统数仓基础数据缺乏的问题,作为企业数仓平台的补充,有其重要的意义,但数据湖的作用在于汇集企业的各个数据源,有一个存放和分析之地,在规划中没有一个整体的数据资产规划和管理职能,这会导致其功能薄弱性,不能承担整体的数据处理和管理之重,实际在一些大型企业,使用数据湖其数据陷阱就会马上出现,业务人员的需求需要DBA或IT人员经过繁杂的处理步骤才能实现达到业务人员的数据分析目的,其会耗费开发人员的时间耗以周计,原因之一是数据湖没有一个数据构建和管理平台去管理和计算这些数据,因此不讲治理的杂乱无章的数据看似能提升数据获取,数据分析的效率,实际上并不能承担企业智能化的使命。
企业数据智能需要解决企业数据智能所面临的诸多问题,企业数据智能需要解决数据的快速计算和结果产出;需要对企业数据资产有整体规划和掌控;需要有一个好的方法论处理业务逻辑繁杂的统计;需要有一个好的构建和管理平台面向业务使用方和开发使用方...这些都是数据湖所不能解决的问题。

数据中台是由阿里巴巴在2015年在内部技术演进和组织优化中提出中台战略中提到的,数据湖本身的缺陷正是数据中台强项,二者可以起到方案补充的作用,在现有技术框架中数据中台可以基于Hadoop数据湖平台作为数据存储和计算载体,实现数据的加工和处理,数据中台更多实现数据的管理,强调利用数据的能力,强调数据开发和高效的使用,数据中台的数据资产管理可以对数据湖中的数据按照数据域方式进行管理并结合业务的逻辑实现整个数据模型的加工和开发。
数据中台与数据域相比,数据中台强调方法论,组织和工具的建设。非常强调数据赋能业务,衍生出很多的数据业务产品。比如在阿里面向商家的生意参谋,面向人物属性的标签服务、面向行业小二的行业洞察…这些都极大的扩展了数据价值,其次数据中台按分析的原子指标和派生指标方式做计算并存储在Maxcompute平台上,如有及时查询要求会同步分析结果数据给MPP或其他DB。这块在数据顶层设计,全域资产、统一技术、产品业务上与Datalke及EDW是不同的。
现有大数据平台厂商和云服务厂商推崇数据湖有其商业目的,AWS认为“云数据湖代表未来,能从数据中挖掘出更多价值”。AWS对数据湖的理解是基于同一存储、对接各类引擎进行分析查询工作,因此推崇Amazon S3来构建数据湖;微软推崇“Azure Data lake”基于HDinsight(原先Hortonworks公司产品,现是Cloudera产品)上层使用hive,spark,U-SQL计算引擎实现计算和查询;华为推荐DAYU数据湖运营平台,强调统一管理和功能的丰富性。这些解决方案非常强调存储服务和想配套的硬件销售。
最后说到底都是企业提供数据计算、存储和应用的平台,最终各种平台的目的都是要更好地服务于业务。
数据中台所面临的调战
随着数据中台理念的普及,各行各业逐步接受了这个概念,很多厂商通过招投标采购、自身投入等各种方式建设了数据中台,但在建设和具体运营中发现了很多问题,诸如数据运营是否能产生效益,对业务是否有推动价值,取数是否快速敏捷等问题…
数据中台建设是一个徐徐渐进的建设过程,数据积累和分析维度都有一个数据和知识积累,认知的过程,和业务系统的“交钥匙”工程有本质不同,营销,市场和供应链的数据是在不断变化中,营销活动,产品也在不断发展和更新中,因此,数据中台建设是一个不停迭代和发展的过程,需要持续投入是数据中台运营部门所面临的最大的挑战。
业务数据的分析需求会有很大变化,回顾互联网或传统产业的发展历程,在2007年iPhone智能手机以一个全新的形式推向市场前,传统的数据分析需求还是停留在PC或线下数据的分析,而今天,几乎所有的分析维度几乎都是来自线上终端(手机)需求或由线上数据来推动线下运营的需求。而今天随着5G和AI技术的发展,越来越多的IOT设备产生的数据开始支撑着数据分析场景,比如商场、饭店已经开始使用摄像头等传感器来收集游客对商品或服务的喜好,这些都触动对数据中台的分析需求,这2个小小例子说明数据中台的分析需求是在不断变化中,因此数据中台建设也需要持续迭代和发展,而不是自我运行的,这需要开发人员在不断迭代中找到事物发展的规律,总结形成数据服务应用,满足普遍化的业务需求。在GPS传感器集成到手机中前,人们无法获知运动中的人位置,通过定位传感器衍生出位置服务,比如大众点评中的餐饮家政等生活圈的服务,这些数据会催生出人新的位置标签,生活圈等指标数据,这些对业务运营有非常大的帮助,因为有了这个信息,你不会再给一个偶尔因为差旅去商家消费的顾客再发送促销信息,也不会给偶尔消费的人有促销广告,这会帮助你的营销更有针对性,更精准。
传统企业在数仓建设都有一个分析平台,固化了很多分析指标,这些分析指标每天发生一些变化,为决策层提供了决策支撑,但指标的更替和变化确以月和年计,这导致对新业务和事物的业务反馈不够及时,因此面对这一挑战需要有一个灵活的数据中台加工机制来满足这些需求。这首先需要有一个组织来支撑这个运营目标,使得运营和开发团队为这个目标达成这个目标,在阿里巴巴内部数据技术及产品部门就是这个组织的典型代表,通过组织机制来推动运营,满足业务部门不间断的数据需求,同时基于需求开创了一套方法论并开发了一系列的工具帮助业务部门达成这一业务目标。这需要数据中台的开发团队开发一套方便,便捷的自助取数工具来满足业务部门的需求。
诚然,在数据建设中还会碰到一些其他潜在问题,诸如需求不明确,分析场景设计不合理,数据指标和分析思路不够能解决用户痛点等情况,但这些都可以通过增加投入,特别是加强咨询和调研的力度来解决这些问题。
尾声 更多内容详见数据中台官网[https://dp.alibaba.com ]
数据中台是很多传统企业做数字化转型的重点投入,这需要从战略、方法论、工具、执行和组织层面做系统规划、有序执行,阿里过去多年经历了内部多年的建设沉淀出多个工具和数据产品,经过央视网、海底捞、飞鹤、联华商超、南航等多个传统行业落地项目的淬炼得出实施的方法论,这些转型先锋为中国企业的数字化转型具有借鉴意义。
阿里巴巴数据中台团队,致力于输出阿里云数据智能的最佳实践,助力每个企业建设自己的数据中台,进而共同实现新时代下的智能商业!
阿里巴巴数据中台解决方案,核心产品:
- Dataphin,以阿里巴巴大数据核心方法论OneData为内核驱动,提供一站式数据构建与管理能力;
- Quick BI,集阿里巴巴数据分析经验沉淀,提供一站式数据分析与展现能力;
- Quick Audience,集阿里巴巴消费者洞察及营销经验,提供一站式人群圈选、洞察及营销投放能力,连接阿里巴巴商业,实现用户增长。
欢迎志同道合者一起成长!
本文作者:谭虎、陈晓勇
本文为云栖社区原创内容,未经允许不得转载。
















