
一、搭建环境的前提条件
环境:ubuntu-16.04
hadoop-2.6.0
jdk1.8.0_161。这里的环境不一定需要和我一样,基本版本差不多都ok的,所需安装包和压缩包自行下载即可。
因为这里是配置Hadoop的教程,配置Java以及安装VMware Tools就自行百度解决哈,这里就不写了(因为教程有点长,可能有些地方有些错误,欢迎留言评论,我会在第一时间修改的)。
二、搭建的详细步骤
1.配置免密码登陆ssh
先判断是否安装ssh,输入命令:ssh localhost,若提示输入密码,即已经安装。如果没有安装,输入命令:sudo apt-get install openssh-server 安装

修改ssh配置文件:
输入命令:vim /etc/ssh/ssh_config 将其中的 Port 22 字段和 PermitLocalCommand no 字段前面的 '#’删除,并且,将 PermitLocalCommand 后面的 no 改为 yes
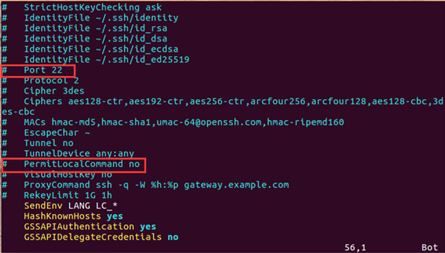
修改过后截图:
查看在根目录下是否存在.ssh文件夹:
输入命令:cd
ls -a

若没有则在根目录下创建.ssh文件夹,输入命令:mkdir .ssh
产生密钥,输入命令:cd /root/.ssh
ssh-keygen -t rsa
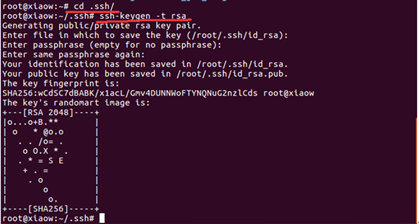
将生成的公钥追加到授权的key中去
输入命令:cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
验证安装是否成功,输入命令:ssh –version
ssh localhost 提示不需要输入密码则安装成功。

2. 配置Hadoop
将下载好的Hadoop压缩包文件拖进Linux下,为了后续的学习的过程,最好单独创建一个文件夹存放这些文件。我这里使用命令:mkdir /home/xiaow/hadoop2.0创建了一个名为hadoop2.0的文件夹,再将hadoop2.6.0压缩包拖进里面并解压。
配置环境变量,输入命令:cd /etc
vim profile
在末尾追加:export HADOOP_HOME=/home/xiaow/hadoop2.0/hadoop-2.6.0
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
注意:这里的路径为自己解压后的路径,每个人的路径不相同。
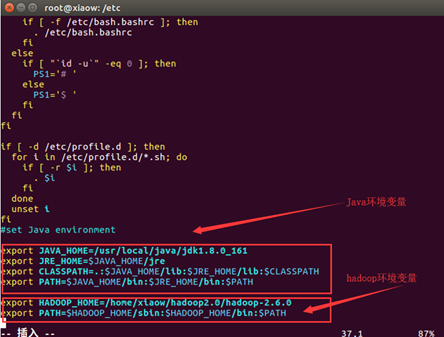
配置完环境变量后,需要系统配置一下环境变量,以便生效。
输入命令:source /etc/profile

3. 修改Hadoop配置文件
需要修改的 hadoop 的配置文件有 5 个,即 core-site.xml、hdfs-site.xml、yarn-site.xml、 slaves、hadoop-env.sh 五个文件。这5个文件的位置为:
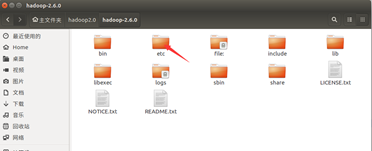
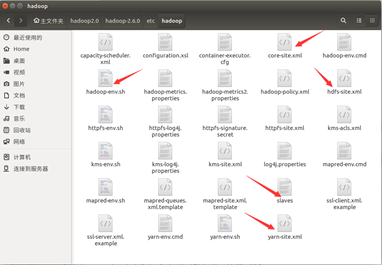
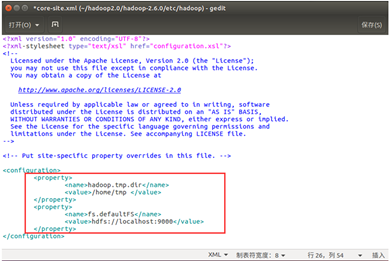
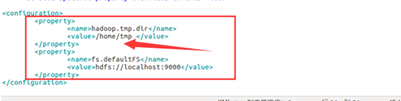
(1). 配置core-site.xml文件
<property>
<name>hadoop.tmp.dir</name>
<value>/home/tmp </value> 设置临时文件夹,只要在 home 下即可 </property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> 也可以改为本机 IP 地址
</property>
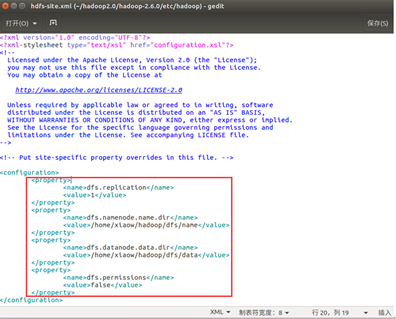
(2). 配置hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>1</value> 备份数目,单节点上是 1,多节点一般为 3
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/xiaow/hadoop/dfs/name</value> NameNode 所在路径
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/xiaow/hadoop/dfs/data</value> dataNode 所在路径
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> HDFS 的权限,默认就行
</property>
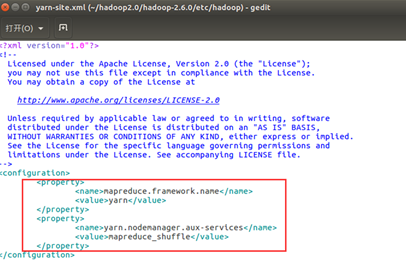
(3). 配置yarn-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
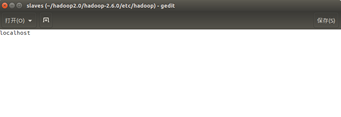
(4). 配置slaves文件
默认就好,不用修改
(5). 配置hadoop-env.sh
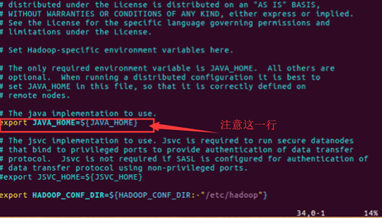
将里面的 JAVA_HOME=${JAVA_HOME}修改为自己安装的jdk地址
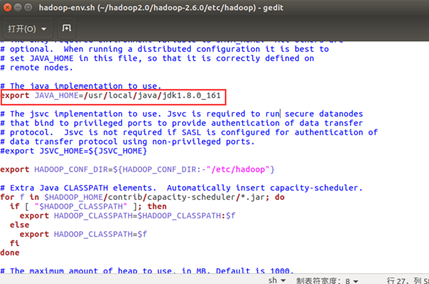
至此hadoop配置文件的修改,已经全部完成。
三、启动Hadoop
输入命令:
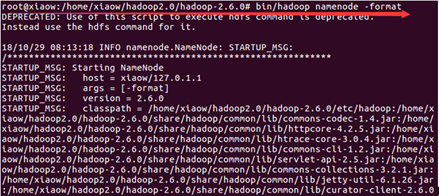
cd /home/xiaow/hadoop2.0/hadoop-2.6.0
bin/hadoop namenode –format
sbin/start-all.sh
jps
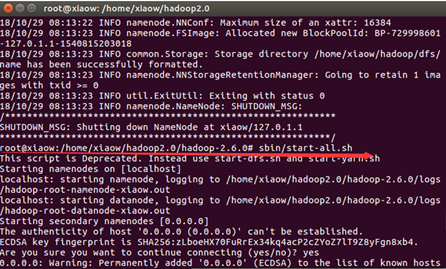
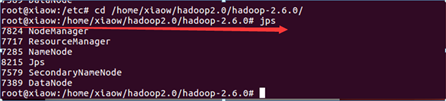
出现如下图所示6个Java进程,则Hadoop伪分布式成功搭建。
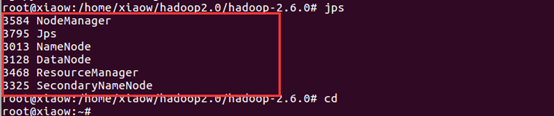
四、补充说明
1、如果出现下面这种情况

输入命令:source /etc/profile 即可解决
2、出现进程不够的情况(一般是少一个datanode进程)
应先输入 sbin/stop-all.sh 停止 hadoop所有进程
解决办法可能有以下两种:
1. 再仔细检查刚才配置文件是否出现错误。一般自己检查不出错误,可叫同学帮忙检查一下,必须仔细比对。 再依次使用这三个命令启动Hadoop:

2.可能是临时文件夹没删掉。
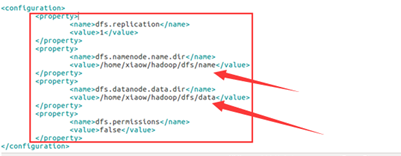
找到上图箭头所指示的文件夹并删掉,在重新启动hadoop,如此问题解决。













