
消息发送流程:
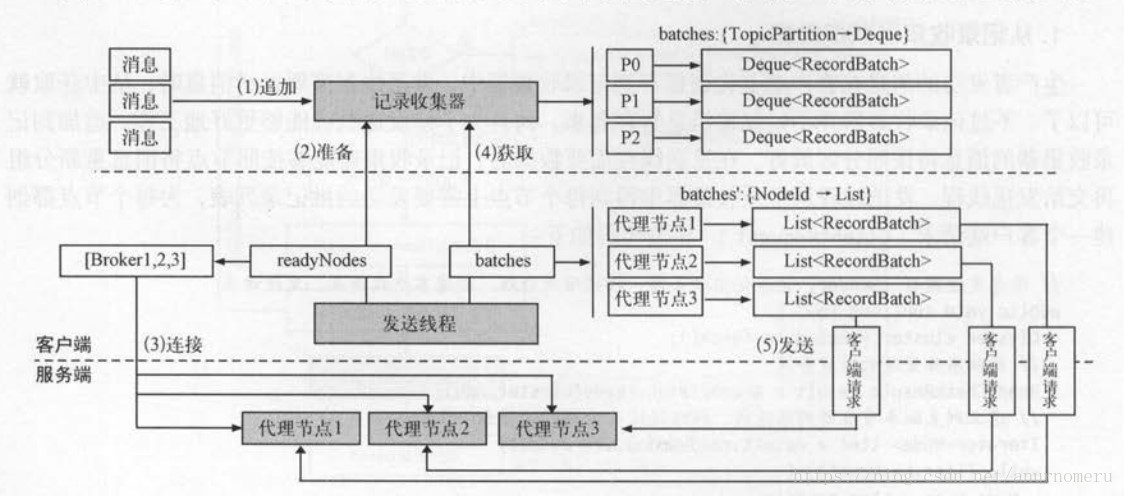
消息发送组件:
其中消息的追加包含以下几个组件。我们在KafkaProducer中调用send方法发送一个消息,在消息追加步骤,最终是将消息添加到了ByteBuffer中。
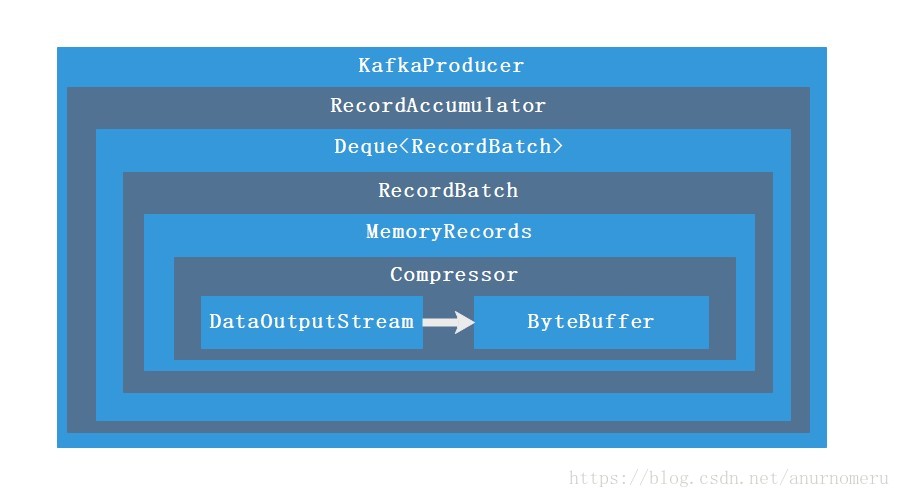
消息追加器流程:
##一、KafkaProducer #####1.1、拦截器的实现 我们发现在send的时候,如果存在拦截器,则调用onSend方法。
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
onSend方法的实现非常简单,实际上这就是将注册到该Producer的拦截器进行轮询,并进行调用,从源码中我们也可以知道,这个拦截器是有顺序要求的,解析配置文件时是依半角逗号来隔开的。
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
// be careful not to throw exception from here
if (record != null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);
else
log.warn("Error executing interceptor onSend callback", e);
}
}
return interceptRecord;
}
// 解析配置时:
case LIST:
if (value instanceof List)
return (List<?>) value;
else if (value instanceof String)
if (trimmed.isEmpty())
return Collections.emptyList();
else
return Arrays.asList(trimmed.split("\\s*,\\s*", -1));
else
throw new ConfigException(name, value, "Expected a comma separated list.");
所以我们的配置文件可以这么写,来注册拦截器,注意,拦截器必须继承ProducerInterceptor。我们在InterceptorPlus 中,把我们即将发送的value强转为了int,然后为其++;
Properties props = new Properties();
String classNames = InterceptorPlus.class.getName() + "," + InterceptorMultiply.class.getName();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.CLIENT_ID_CONFIG, "ProducerTest");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, classNames);
// 拦截器:
/**
* Created by Anur IjuoKaruKas on 2018/9/5
*/
public class InterceptorPlus implements ProducerInterceptor {
@Override
public ProducerRecord onSend(ProducerRecord record) {
Integer val = Integer.valueOf(record.value()
.toString());
String result = String.valueOf(val + 1);
return new ProducerRecord(record.topic(),
record.key(),
result);
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
#####1.2、消息分区的实现 首先,先从元数据拿到集群的信息,集群信息中的partitions是以 Map<\String, List<\PartitionInfo>>来存储的。这里根据我们指定的topic名字来获取partitions。这里通过两种方式来确定消息发往哪个分区:
如果未指定key:在这个分区器中,保存了一个全局的AtomicInteger counter,通过一个简单的取模来确定到底发送到哪一个分区,DefaultPartitioner.toPositive(int num)方法来确保一个值一定为正数,我们知道负数取模是会得到一个负数的。
如果指定了key:我们知道,消息可以被指定一个key。DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions,同一个key,hash算出来的数字总会是相同的,只要保证分区数量不变,就可以计算出同一个partition,而同一个partition,可以确保消息发送的顺序。
/** * Compute the partition for the given record. * 为消息计算分区 * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes serialized key to partition on (or null if no key) * @param value The value to partition on or null * @param valueBytes serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List
partitions = cluster.partitionsForTopic(topic);// 先从集群中取出所有分区 int numPartitions = partitions.size(); if (keyBytes == null) { // 没有key的情况走这个分支 int nextValue = counter.getAndIncrement(); // 计数服务+1 List availablePartitions = cluster.availablePartitionsForTopic(topic);// 取出可用的分区 if (availablePartitions.size() > 0) { int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part) .partition(); } else { // no partitions are available, give a non-available partition // 没有可用的分区,只能返回一个不可用的分区 return DefaultPartitioner.toPositive(nextValue) % numPartitions; } } else { // hash the keyBytes to choose a partition return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }
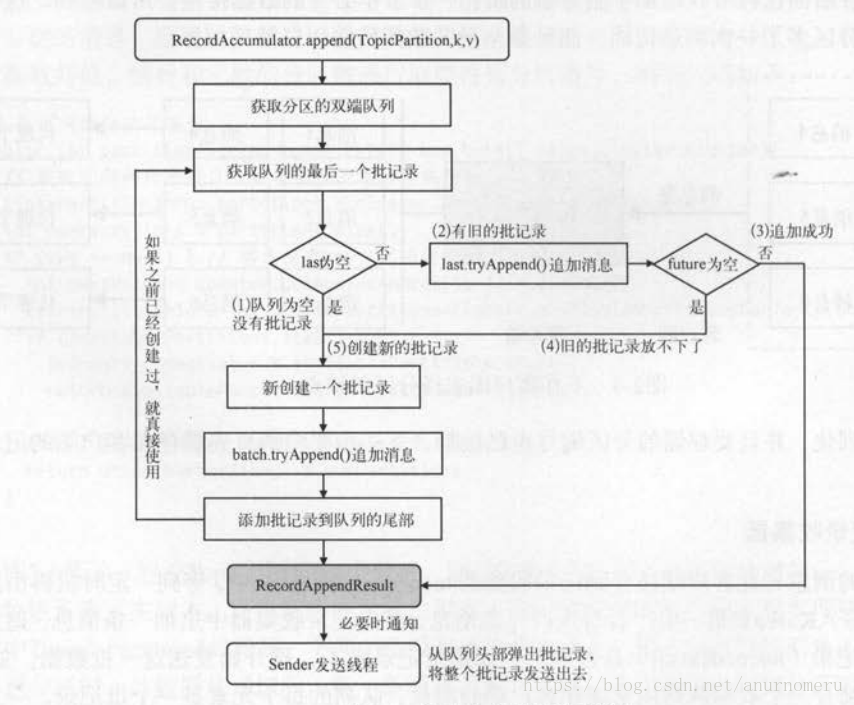
##二、RecordAccumulator #####2.1、双重检查锁与分段锁 ######2.1.1、分段锁 这是存在RecordAccumulator中的一段逻辑,我们在追加消息时需要根据Topic来获取到Deque<\RecordBatch>,这后面的一系列操作,都是非线程安全的,所以在操作dq对象时,这里采用了分段锁的概念。我们每一个Topic都维护了一个Deque,它们的append操作并不互相影响,所以不必为整个<\String /* topic */ , Deque<\RecordBatch>>加锁,只需对某个topic下的dq加锁即可。
######2.1.2、双重检查锁 双重检查锁,适用于先检查,后执行。我们发现上下两段临界区的代码有一部分很像,实际上就是使用了双重检查锁,比如像下面这个简单的单例模式的创建。
public static Singleton getInstanceDC() {
if (_instance == null) { // Single Checked
synchronized (Singleton.class) {
if (_instance == null) { // Double checked
_instance = new Singleton();
}
}
}
return _instance;
}
// check if we have an in-progress batch
Deque<RecordBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed) {
throw new IllegalStateException("Cannot send after the producer is closed.");
}
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
return appendResult;
}
}
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed) {
throw new IllegalStateException("Cannot send after the producer is closed.");
}
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
##三、RecordBatch RecordBatch(一个批发送对象,可以存放很多条消息,它有一定的存储空间上限,当新的消息放不下时,Kafka就会在RecordAccumulator中申请空间 ByteBuffer buffer = free.allocate(size, maxTimeToBlock) )
我们在调用KafkaProducer的send方法时,可以指定一个回调。这里不过多讲述RecordBatch。在消息追加时这个回调就会与RecordBatch进行绑定。
这个回调就是在RecordBatch层面被调用,会在正常响应、超时、或关闭生产者时调用这个。比如我们可以在非正常响应时将消息保存在本地或者将异常日志打印出来,以便恢复之类的。
producer.send(new ProducerRecord<>(topic, messageNo, messageStr), new DemoCallBack(startTime, messageNo, messageStr));
每一条消息追加进来,都会生成一个新的Thunk对象,Kafka中应用了很多这种设计,例如 【仿照Kafka,实现一个简单的监听器 + 适配器吧!】。原理都是在对象中维护一个类似List<方法>之类的列表,然后在适当的时候(异常、正常、或者执行到某个步骤时)循环取出列表,并调用里面的方法。
// FutureRecordMetadata主要包含了 RecordBatch里的 ProduceRequestResult
FutureRecordMetadata future = new FutureRecordMetadata(
this.produceFuture,
this.recordCount,
timestamp,
checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
if (callback != null) {
thunks.add(new Thunk(callback, future));
}
##四、MemoryRecord、Compressor 这两个对象在消息追加中算是最底层的角色了。我们在前面申请到的空间ByteBuffer对象,就是由这两者进行维护。Compressor负责消息的写入,它生成了一个bufferStream用于向ByteBuffer写入数据。(还有一个appendStream负责压缩数据,这块还没看太明白)
创建 ByteBufferOutputStream bufferStream 十分简单,实际上就是将ByteBuffer的引用交给 bufferStream。
public class ByteBufferOutputStream extends OutputStream {
private ByteBuffer buffer;
public ByteBufferOutputStream(ByteBuffer buffer) {
this.buffer = buffer;
}
ByteBufferOutputStream 中巧妙的便是它的ByteBuffer自动扩容方法。我们来看看最基础的一个写入
public void write(byte[] bytes, int off, int len) {
if (buffer.remaining() < len)
expandBuffer(buffer.capacity() + len);
buffer.put(bytes, off, len);
}
如果要写入的内容过大,会进行一次ByteBuffer的扩容,比如说我的RecordBatch默认都为10M,现在已经9.9M了,最后一条消息进来,如果正好大了一点,那么就依靠这个扩容方法,临时扩充一下ByteBuffer的大小。
因为前面在判断能否继续追加消息的时候,只是对消息大小进行了预估,尤其是指定了压缩方式后,这个预估可能会没那么准确,这个时候,就需要ByteBuffer的扩容机制来进行兜底。
private void expandBuffer(int size) {
int expandSize = Math.max((int) (buffer.capacity() * REALLOCATION_FACTOR), size);
ByteBuffer temp = ByteBuffer.allocate(expandSize);
temp.put(buffer.array(), buffer.arrayOffset(), buffer.position());
buffer = temp;
}
##五、Kafka的ByteBuffer内存管理 第二步中说道的RecordAccumulator中,有一个内存申请的操作,实际上就是Kafka BufferPool来完成的。
先看看BufferPool的构造方法,我们在创建RecordAccumulator时(KafkaProducer),会传入一个参数,叫做totalMemorySize。这个totalMemorySize,是在KafkaProducer的构造方法里面获取的。
我们可以在配置中:
指定ProducerConfig.BUFFER_MEMORY_CONFIG来配置BufferPool的大小, 指定ProducerConfig.BATCH_SIZE_CONFIG 来配置每一个ByteBuffer的大小。
从构造方法和上面的分析我们可以知道,内存的消耗随着Producer的增多而增多,ByteBuffer默认大小如果不合理,将可能导致RecordAccumulator经常性的阻塞。
-------------------- KafkaProducer 构造方法:
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// accumulator相关配置的创建与更新
this.accumulator = new RecordAccumulator(config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.totalMemorySize,
this.compressionType,
config.getLong(ProducerConfig.LINGER_MS_CONFIG),
retryBackoffMs,
metrics,
time);
-------------------- RecordAccumulator 构造方法:
this.free = new BufferPool(totalSize, batchSize, metrics, time, metricGrpName);
-------------------- BufferPool 构造方法:
public BufferPool(long memory, int poolableSize, Metrics metrics, Time time, String metricGrpName) {
this.poolableSize = poolableSize;
this.lock = new ReentrantLock();
this.free = new ArrayDeque<ByteBuffer>();
this.waiters = new ArrayDeque<Condition>();
this.totalMemory = memory;
this.availableMemory = memory;
this.metrics = metrics;
this.time = time;
this.waitTime = this.metrics.sensor("bufferpool-wait-time");
MetricName metricName = metrics.metricName("bufferpool-wait-ratio",
metricGrpName,
"The fraction of time an appender waits for space allocation.");
this.waitTime.add(metricName, new Rate(TimeUnit.NANOSECONDS));
}
我们来看看ByteBuffer和核心方法,allocate。进来的第一个判断,size > this.totalMemory,如果要申请的大小直接大于ByteBuffer可持所有大小,直接抛出异常。
/** 代码1.1 */
/**
* Allocate a buffer of the given size. This method blocks if there is not enough memory and the buffer pool
* is configured with blocking mode.
*
* @param size The buffer size to allocate in bytes
* @param maxTimeToBlockMs The maximum time in milliseconds to block for buffer memory to be available
*
* @return The buffer
* @throws InterruptedException If the thread is interrupted while blocked
* @throws IllegalArgumentException if size is larger than the total memory controlled by the pool (and hence we would block
* forever)
*/
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory) {
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
}
//......
}
这上面的分支,实际上都是【有足够内存可分配的情况】
1、如果申请的内存为 poolableSize(最小分配大小) 且 private final Deque
则直接返回重复利用的ByteBuffer
2、如果申请的大小不是poolableSize,但现在可以立即满足,则freeUp一下。
/** 代码1.2 紧接着1.1 */
this.lock.lock();
try {
// check if we have a free buffer of the right size pooled
// 校验是否有合适的小的空闲的buffer
if (size == poolableSize && !this.free.isEmpty()) {
return this.free.pollFirst();
}
// now check if the request is immediately satisfiable with the
// memory on hand or if we need to block
// 校验现在的内存是否可以立即满足请求,或者是否需要阻塞
int freeListSize = this.free.size() * this.poolableSize;
// 如果可用内存+freeList大小大于申请大小
if (this.availableMemory + freeListSize >= size) {
// we have enough unallocated or pooled memory to immediately
// satisfy the request
// 有足够的被释放或存放在池中的内存来立即满足请求
freeUp(size);
this.availableMemory -= size;
lock.unlock();
return ByteBuffer.allocate(size);
} else {// 现在可用的内存大小无法满足
//.....
freeUp的逻辑十分简单,实际上就是当申请的内存大于可用内存availableMemory时,从free这个ByteBuffer列表循环 将free:List
/**
* Attempt to ensure we have at least the requested number of bytes of memory for allocation by deallocating pooled
* buffers (if needed)
*/
private void freeUp(int size) {
// 当free列表不为空,并且可用内存小于申请内存时
// :: 还是从free中取,这个取法,可以取多个
while (!this.free.isEmpty() && this.availableMemory < size) {
this.availableMemory += this.free.pollLast()
.capacity();
}
}
除了以上两种情况(1、够用,而且有现成的ByteBuffer可供调用。2、够用,但没有现成的ByteBuffer可供调用,需要申请),只剩下第三种情况了,即不够用。这种情况可想而知,只能等待更多的,已经使用的ByteBuffer释放内存。
它可以复用freeUp嘛?当然可以。但freeUp是不够的,因为我们知道freeUp是释放掉free:List
怎么解决?最简单的当然是写个循环,等待其他的线程把正在使用的ByteBuffer释放掉,内存就够用了。Kafka就是这么做的。
我们来看看kafka是如何实现的:
声明一个int accumulated,这个是现在已声明的内存大小。new一个Condition,进行condition内的阻塞(await),并释放锁,且每当已声明大小还不足以达到要求,就在condition上阻塞。
假如这是我们waiter里面的最后一个(也是第一个线程),它难道将永远阻塞?
并不,实际上我们在释放内存时,会peek队列中第一个等待的线程进行signal,而且会将poolable的ByteBuffer塞进List
/** 代码1.3 紧接着1.2 */
} else {// 现在可用的内存大小无法满足
// we are out of memory and will have to block
int accumulated = 0;
ByteBuffer buffer = null;
Condition moreMemory = this.lock.newCondition();
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);
// loop over and over until we have a buffer or have reserved
// enough memory to allocate one
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
// 当前condition进行等待 remainingTimeToBlockNs 毫秒
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
this.waiters.remove(moreMemory);
throw e;
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
// 统计阻塞时间
this.waitTime.record(timeNs, time.milliseconds());
}
//.....
// 通知waiter队列的队头
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
this.availableMemory += size;
}
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null) {
moreMem.signal();
}
} finally {
lock.unlock();
}
}
在被通知之后,线程又会做什么呢?
1、首先如果超时了,直接报出异常。
2、再次判断申请的空间是不是 poolableSize,如果是,则直接从free中取一个(一般也只有一个,因为deallocate是加锁了的,释放完内存就会通知waiter),当然也可能free中为空(因为释放的ByteBuffer不是Poolable大小,它会被释放到availableMemory中,进入下一步)
3、走到了这个else分支里,首先会尝试从free中释放所需内存,然后看看剩余的availableMemory是否比剩余所要申请的大。如果是,申请的空间就算已经全部满足了。 int got = (int) Math.min(size - accumulated, this.availableMemory)。但如果没申请完,就会继续进入while循环,回到await状态,继续等有人通知。
4、如果已经申请完了,出队。此时如果还有空间,会通知waiter的第一个去拿内存,并返回申请的内存。
/** 代码1.4 紧接着1.3 */
if (waitingTimeElapsed) {// 第一步
this.waiters.remove(moreMemory);
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
// 没超时,剩余时间等于自己减去耗时
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
// 检查free list是否可以满足请求,不满足则申请内存
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {// 第二步
// just grab a buffer from the free list
// 和前面是一样的,从free list中取一个出来
buffer = this.free.pollFirst();
accumulated = size;
} else {// 第三步
//todo: 走到这里说明申请的大小要大于poolableSize,或者free为空
// we'll need to allocate memory, but we may only get
// part of what we need on this iteration
// 需要申请内存,但是在这个循环可能只能从中获取需要内存的一部分,也就是说太大了,会再获取一次
// size:要申请的大小。
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.availableMemory);
this.availableMemory -= got;
accumulated += got;
}
}
// remove the condition for this thread to let the next thread
// in line start getting memory
Condition removed = this.waiters.removeFirst();
if (removed != moreMemory) {
throw new IllegalStateException("Wrong condition: this shouldn't happen.");
}
// signal any additional waiters if there is more memory left
// over for them
// 第四步、通知其他waiters去拿内存
if (this.availableMemory > 0 || !this.free.isEmpty()) {
if (!this.waiters.isEmpty()) {
this.waiters.peekFirst()
.signal();
}
}
// unlock and return the buffer
lock.unlock();
if (buffer == null) {// buffer = null 代表内存时直接从free中轮询释放的
return ByteBuffer.allocate(size);
} else {// buffer不为空,是直接复用free中的内存
return buffer;
}
}
通过上面的分析我们知道,一旦有线程想要申请一块很大的内存的话,而且这个线程到了队头,它就成了大哥。所有释放的内存,都被分配给它,所以我们要尽量地去避免这种情况!
比如说我们突然发送一条需要占用很大内存的消息,那么对于kafka的效率来说,将是毁灭性的!
另,如果发送的消息比较平均,且ByteBuffer的poolableSize分配合理,则可以极大地提升kafka的效率!
参考书籍:
《Kafka技术内幕》 郑奇煌著 《Apache Kafka源码剖析》 徐郡明著











