
一.环境概述
Kubernetes版本:1.12.6
Docker版本:17.06.2-ce-3
操作系统版本:CentOS 7.4.1708
二.问题现象
1.钉钉收到Pod容器运行状态异常和服务接口超时监控告警,查看到K8s Worker节点频繁处于NotReady状态,如重启Kubelet和节点恢复正常一会后又变成NotReady。
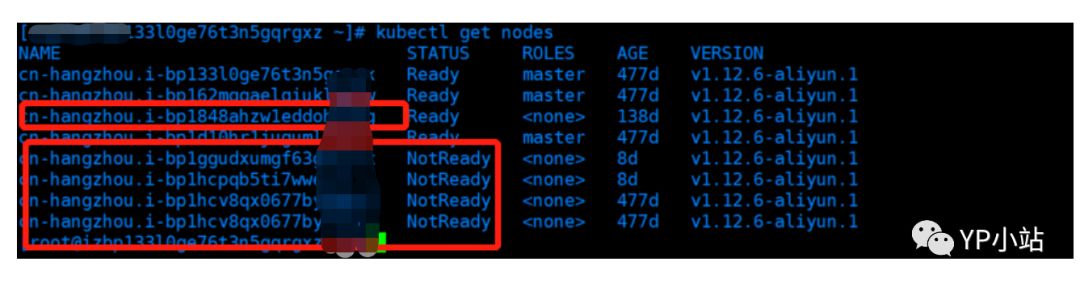
2.容器大部分处于Exit状态,Pod大部分处于Pending、Unknown等状态。这里说一下,Pod处于Pending、Unknown等状态代表什么含义,前者基本上是scheduler失败的问题如节点资源不足等,后者则是Pod所在的节点有问题如kublet和其他K8s组件通信异常等。
三.问题排查
定位问题的思路
A. 查看notReady节点状态信息,提示无法连接到docker,实际上该节点的docker服务是处于Active运行状态的,这就说明k8s的某个组件和docker daemon交互有问题。不用想,K8s组件中和docker daemon交互最紧密的服务当然是Kubelet。
$ kubectl describe node $NODE_NAME
提示错误信息,这里忘记截图了。
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
B. 到有问题的节点上查看kubelet的日志
$ journalctl -f -u kubelet
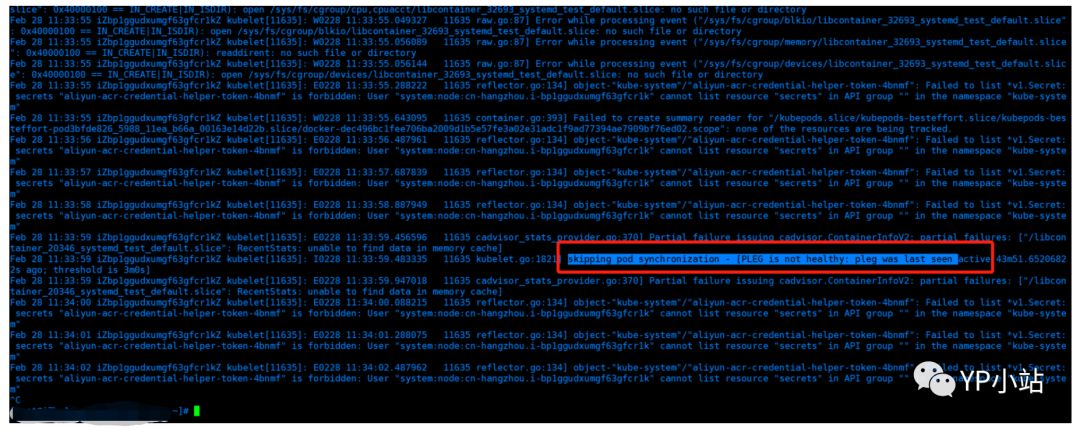
OK,这里看到有关信息了。由于此非线上环境相对不是特别急,因此看看能否从其他线索中发现更多具体有用信息。
C. 查看系统日志(没看到有用信息)
$ tail -n 40 -f /var/log/messages
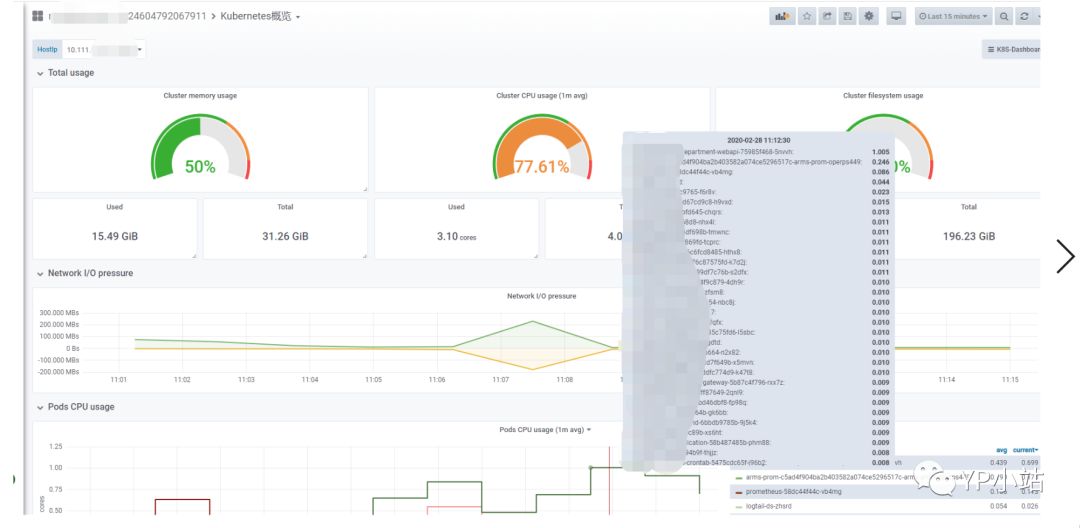
D. 查看有问题的主机负载和该节点上的Pod资源使用率,可以看到主机资源使用率和负载还是非常高的
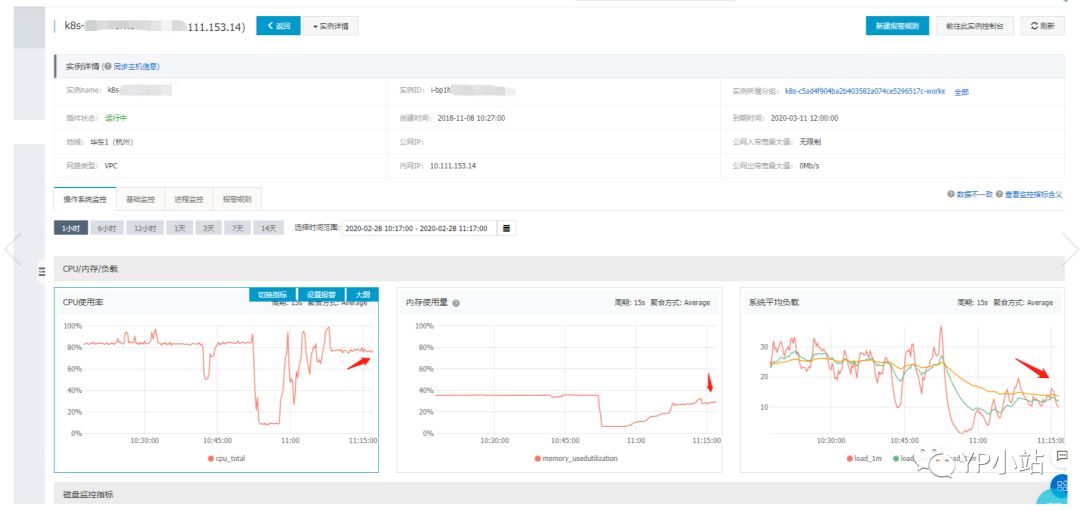
没有资源使用异常高的Pod,或者说并不是某个Pod资源使用异常导致节点有问题。
E. 下下策,重启docker、Kubelet、节点(无效果,此非线上环境,线上环境请慎重)
$ systemctl restart kubelet
进一步查找问题原因
根据上面B步骤定位问题时提示的Kubelet问题信息,可以大概知道与Pleg问题有关。
什么是Pleg?
Pleg,即Pod生命周期事件生成器,Pleg是Kubelet二进制文件中的内部模块,主要职责就是通过每个匹配的 Pod级别事件来调整容器运行时的状态,并将调整的结果写入缓存,使 Pod 的缓存保持最新状态。对于 Pod,Kubelet 会从多个数据来源 watch Pod spec 中的变化。对于容器,Kubelet 会定期(默认是10s)轮询容器运行时,以获取所有容器的最新状态。
随着 Pod 和容器数量的增加,轮询会产生不可忽略的开销,并且会由于 Kubelet 的并行操作而加剧这种开销(为每个 Pod 分配一个 goruntine,用来获取容器的状态)。轮询带来的周期性大量并发请求会导致较高的 CPU 使用率峰值(即使 Pod 的定义和容器的状态没有发生改变),降低性能。最后容器运行时可能不堪重负,从而降低系统的可靠性。
PLEG is not healthy 如何发生?
Kubelet 在一个同步循环(SyncLoop() 函数)中会定期(默认是 10s)调用 Healthy() 函数。Healthy() 函数会检查 relist 进程(PLEG 的关键任务,重新列出节点上的所有容器(例如 docker ps),并与上一次的容器列表进行对比,以此来判断容器状态的变化)是否在 3 分钟内完成。如果 relist 进程的完成时间超过了 3 分钟,就会报告 PLEG is not healthy。一般而言当节点上运行有大量的Pod,亦或者负载过高性能下降,或者出现Bug时,PLEG便无法在3分钟内完成所有这些操作。
Kubelet的PLEG问题出现的原因包括但不限于:
RPC 调用过程中容器运行时响应超时(有可能是性能下降,死锁或者出现了 bug)。
节点上的 Pod 数量太多,导致 relist操作无法在 3 分钟内完成。事件数量和延时与 Pod 数量成正比,与节点资源无关。
relist 出现了死锁,该 bug 已在 Kubernetes 1.14 中修复。
获取 Pod 的网络堆栈信息时CNI插件出现了bug(简而言之即容器管理系统和网络插件之间通过 JSON 格式的文件进行通信,实现容器的网络功能)。
此处摘自,https://fuckcloudnative.io/posts/understanding-the-pleg-is-not-healthy/
由此,问题原因即每台K8s Worker节点运行的Pod数量过多(80+)导致系统负载过高性能下降(机器配置8核32GB),Docker守护程序无法及时响应,relist 进程无法在 3 分钟内完成,进而导致Kubelet节点Notready,Pod反复创建又导致数量攀升(节点达到了110个pod,Jenkins在发布项目),进一步加剧了服务的崩溃。(也有可能是Bug诱发导致) 。
在 Kubernetes 社区中,PLEG is not healthy 成名已久,只要出现这个报错就有很大概率造成 Node 状态变成 NotReady。GitHub上相关Issue,请见:
四.当前解决办法
1.添加一台Worker节点,让每台节点运行合适数量的Pod;
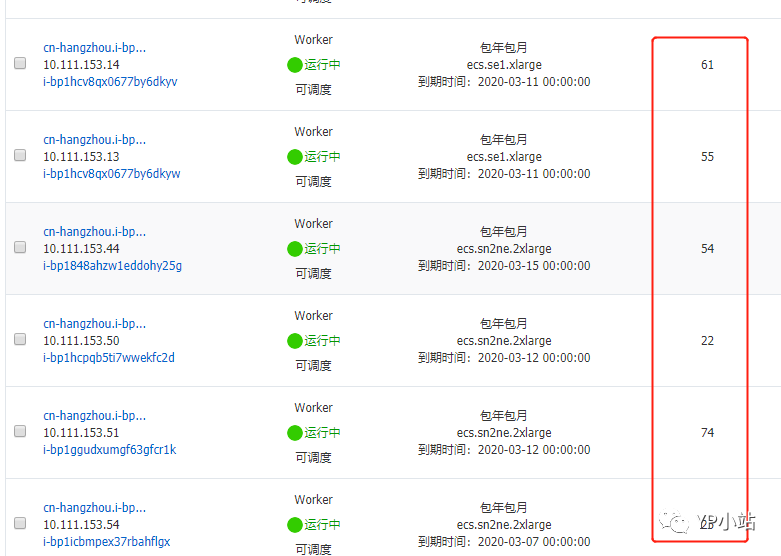
2.依序重启所有的Worker节点,让Pod全部重新调度启动;
五.防范措施
重启节点是有风险的,特别是线上环境。如何长效规避该类似问题的发生特别重要。如下:
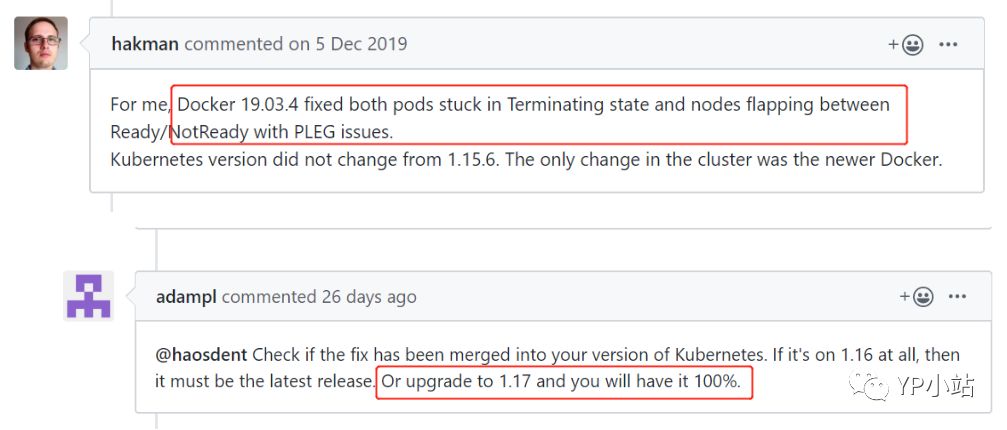
1.当前使用的Kubernetes 1.12版本和Docker版本客观上比较老,当前版本存在Bug(一定条件下触发),应尽可能使用Kubernetes新版本(如1.17)和Docker新版本(如19.03.4);
2.部署的Pod,应尽可能设置Resource的request和limit,不能任其使用主机系统资源;
3.每台Worker节点应当为系统设置预留资源,如预留4核6GB内存给Kubernetes服务和Systemd管理的进程使用;
4.Kubernetes集群每台Worker节点Pod运行数量不宜太多(基于现有配置从当前正常的线上环境来看不应超过70个),集群负载非常高时需及时扩容节点;
5.修改PLEG的检查时间为30s,可参考IBM文章
https://www.ibm.com/support/knowledgecenter/SSFC4F\_1.1.0/troubleshoot/docker\_pods\_overload.html
6.除了针对Pod运行状态进行监控告警,还需要支持K8s节点运行状态的监控告警,这样能第一时间发现问题,介入处理降低风险;
往期精彩文章
您的关注是小站的动力

欢迎大家关注交流,定期分享自动化运维、DevOps、Kubernetes、Service Mesh和Cloud Native
扫码『加群』交流技术

本文分享自微信公众号 - YP小站(ypxiaozhan)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












