
一、前言
最近在线上遇到了因缓存和数据库数据不一致而引发的问题。经排查后,发现是因为我们写操作采用的策略是先写数据库,再删缓存。如果写操作后马上去读的话,由于缓存被删,会去数据库查数据。又由于数据库主从延迟,会加载从库的旧数据到缓存。于是发生了数据库已被修改为新数据,但缓存依然是旧数据的情况。
这次线上的事情,引申出了一个老生常谈的话题,如何保证数据库与缓存一致性?今天我们就来谈谈这个事。

二、不一致场景分析
1、 无并发时
首先看一下最简单的情况。当一个写请求希望把数据从D1改成D2。
由于我们写请求需要进行两个操作:1、写数据库;2、更新/删除缓存。这两个操作并非是一个事务,所以必然有可能发生其中一个成功一个失败的情况(一般是后一个,因为如果前一个操作失败,一般不会再做第二个操作)。这样会引申出以下两种情况。

- 先将DB数据由D1修改为D2
- 再删除或更新缓存(该步骤发生异常,即失败了)
最终,数据库数据是D2,缓存数据依旧为D1。

- 先更新缓存数据由D1到D2
- 更新数据库发生异常
最终,数据库数据是D1,缓存数据已被修改为D2。
2、 并发时
接下来讨论更复杂的情况,也就是在读写并发时可能发生的不一致。
首先明确的是,在读未命中缓存的时候,我们的做法一般是去查数据库,然后把查到的值写入到缓存中。但在写数据时,策略往往不尽相同。我们常常会考虑两个问题。1)先操作缓存还是先操作数据库;2)删缓存还是更新缓存。
1)先DB后缓存
1. 写数据库后更新缓存
- 首先是未命中读+写操作并发的场景。

- 线程A读缓存,未命中
- 线程A读DB,得到Data1
- 线程B写DB,将数据从Data1更新至Data2
- 线程B写缓存,更新为Data2
- 线程A写缓存,更新为之前读到的Data1
最终,DB值为Data2,但缓存中值为Data1。
- 其次是写操作并发的场景。

- 线程A写DB,写入Data1
- 线程B写DB,写入Data2
- 线程A更新缓存,写入Data1
- 线程B更新缓存,写入Data2
最终,DB值为Data2,缓存值为Data1.
2. 写数据库后删除缓存
写数据库之后删除缓存,似乎可以解决以上的问题,如下图所示。

但这不是万能的,就例如我在开篇提到的线上问题,采用的正是写DB+删缓存策略。由于我们项目读QPS非常大,但写QPS不高。故采用了读写分离的主从架构。写请求都在主库上进行,读请求则访问从库,并依赖主从同步保证数据一致。由于主从同步需要时间,就可能发生以下的情况导致DB与缓存数据不一致。
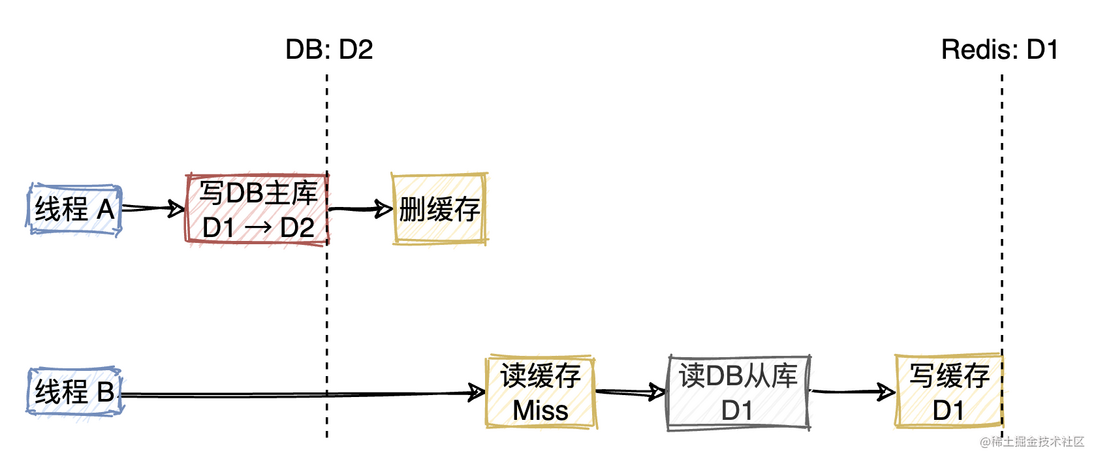
2)先缓存后DB
1. 删缓存后写数据库

- 线程A写请求,先删缓存
- 线程B读缓存,未命中
- 线程B读DB,得到D1
- 线程A写数据库,D1更新为D2
- 线程B写缓存D1
最终,DB的数据是D2,而缓存是D1。
2. 更新缓存后写数据库
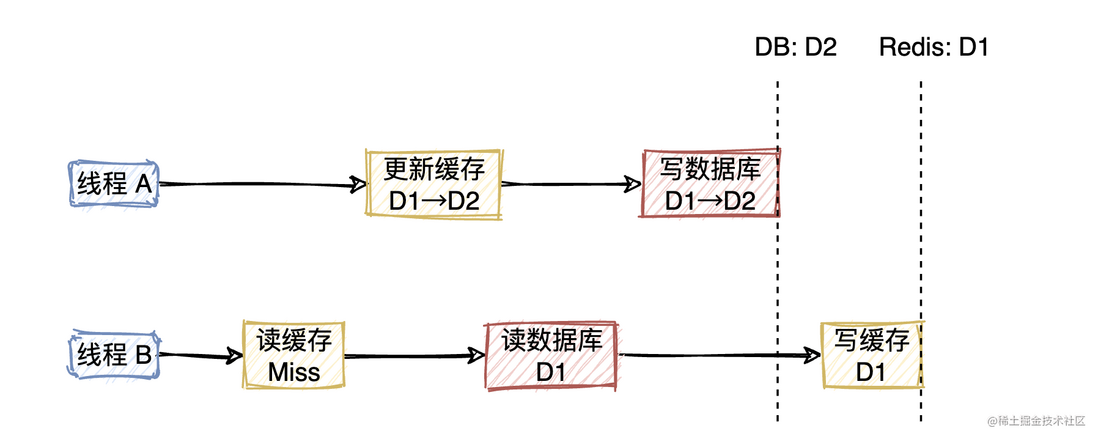
- 线程B读缓存,未命中
- 线程A写请求,缓存由D1更新至D2
- 线程B读DB,得到D1
- 线程A写DB,有D1更新至D2
- 线程B写缓存D1
最终,DB的数据是D2,缓存的数据是D1。
三、不一致的处理方式
在缓存与数据库不一致之后,若过期时间非常长,且期间没有写操作,会造成读的时候有很长一段时间数据是错误的。那么如何去修正或者说尽量保证一致呢?
1、延迟双删
顾名思义,延迟双删就是在写完数据库之后,隔一小段时间\( \Delta(T) \),再删一次缓存。当然第二次删缓存是异步进行的。
对以下两种情况,采用延迟双删策略后,都能保证在一段时间后,缓存中的脏数据被删除。也就是达到了最终一致性。但期间可能有请求读到的是脏数据。

这一小段时间\( \Delta(T) \)该怎么取值呢?首先知道,\( \Delta(T) \)之后再删一次的目的是为了删除并发的未命中读产生的脏数据。所以一般要略大于一次读的请求,且略大于主从同步的延迟。
2、删除缓存重试机制
删缓存这一步可能会发生异常,为了保证删缓存成功,可以引入重试机制。对于删缓存失败的操作,进入重试队列。重试队列选型可以是Kafka,也可以是Redis中的列表。对于一致性要求没那么高的,甚至可以在单机内存中存放队列。
3、读取binlog校对缓存
使用组件/中间件获取数据库的binlog。binlog若采用Row模式,解析后一般会有数据行最新数据的信息。通过这个信息去查缓存,若发现不一致则删除缓存;若一致,则不作处理。
四、总结
其实最终使用哪种策略去写数据,都要依据自己服务的特性来做取舍,并没有万能的策略(除非使用串行化或者做很多限制保证数据强一致,这时会降低系统可用性)。
业界经常使用的Cache Aside策略,也就是对于写请求先更新数据库再删缓存的这种做法,在我们的服务中会遇到不少问题。所以最终改成了先更新数据库再更新缓存。
对于线上的情况,可以尝试不同的策略,并在后台做数据库与缓存的一致性统计,结合业务特点选择最合适的方案。


