
Apache Kafka 2.1.0正式支持ZStandard —— ZStandard是Facebook开源的压缩算法,旨在提供超高的压缩比(compression ratio),具体细节参见https://facebook.github.io/zstd/。本文对Kafka支持的这几种压缩算法(GZIP、Snappy、LZ4、ZStandard)做了一下基本的性能测试,希望能够以不同维度去衡量不同压缩算法在Kafka中的表现。
一、环境准备
本次测试使用了两台云主机,一台作为Kafka的服务器,跑broker进程;另一台作为client,运行Kafka的客户端程序(producer和consumer),具体配置如下:

软件配置如下:

二、测试topic准备
依次创建4个topic:test1、test2、test3、test4,分别用于LZ4、ZStandard、Snappy和GZIP的测试,这些topic都是单分区单副本。
三、测试producer端
使用kafka-producer-perf-test.sh脚本依次为4个topic发送60,000,000条消息,每条消息1KB大小,去计算各种压缩算法的TPS以及其他指标。结果如下:
1、客户端CPU使用率统计图
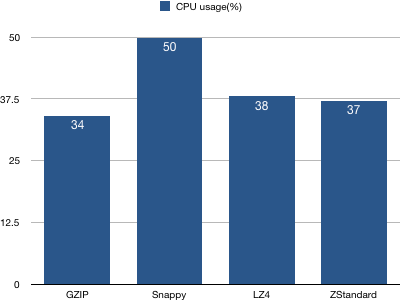
结论:Snappy算法使用的CPU资源最多,其他3种压缩算法相差不多。
2、Broker服务器带宽统计
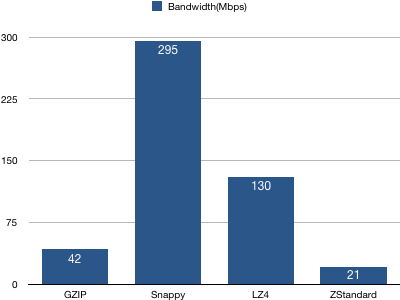
结论:Snappy算法占用的带宽最多且遥遥领先,LZ4次之,而新引入的ZStandard使用的带宽最少。一个可能的原因是ZStandard有较高的压缩比,减少了总体的网络IO传输量。
3、producer吞吐量(TPS)统计
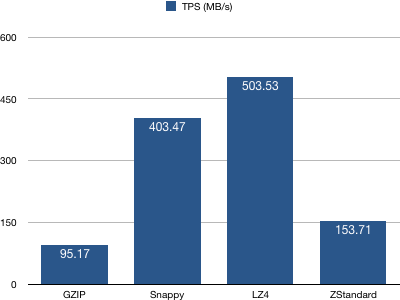
结论:配置LZ4的producer TPS最高——LZ4算法有着最快的压缩时间(至少是top3),故整体TPS最高也不令人惊讶。Snappy次之,ZStandard位居第三位。说明ZStandard不是一个很快的压缩算法。
4、producer延时分布统计
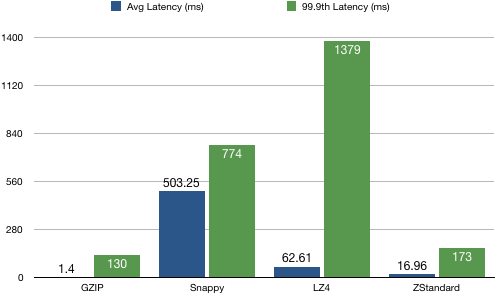
结论:GZIP算法的延时最低,ZStandard次之。有意思的是,Snappy算法的平均值和99.9分位均值比较接近,而LZ4算法方差较大(当然也可能因为异常点导致)。总之从延时角度来看GZIP最优。
5、磁盘占用统计
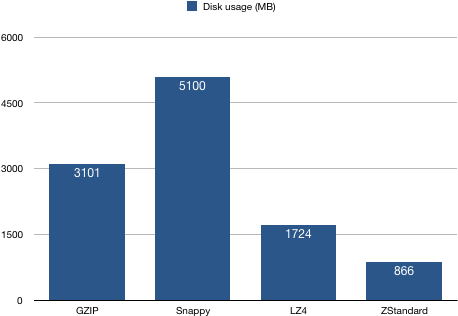
结论:配置ZStandard算法producer生产的消息有着最高的压缩比,这符合ZStandard算法官方的定位:"Zstd can trade compression speed for stronger compression ratios." —— 即该算法牺牲一部分压缩速度去换取更高的压缩比。
四、测试consumer端
使用kafka-consumer-perf-test.sh脚本依次消费4个topic,每个topic消费60,000,000条消息,去计算consumer端解压缩性能以及其他核心指标,结果如下:
1、客户端CPU使用率统计
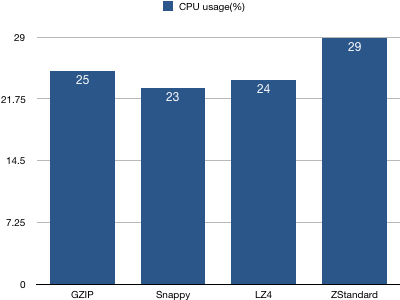
结论:基本上4种压缩算法的客户端CPU使用率基本持平,ZStandard算法略高一些
2、Broker端带宽占用统计
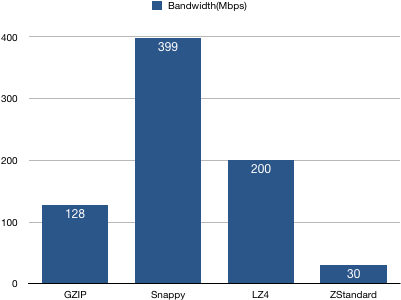
结论:Snappy占用带宽最多,ZStandard最少——同理,这是因为ZStandard有最高的压缩比,极大地降低了网络IO传输量。
3、consumer吞吐量(TPS)统计
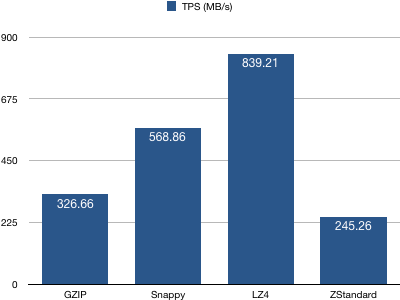
结论:配置LZ4算法的consumer有着最高的TPS,而ZStandard算法最低。
五、总结
相比于其他压缩算法,ZStandard有着最高的压缩比,相同的消息量占用最少的磁盘容量,因此带宽的占用也是比较少的,但是在TPS方面的表现并不抢眼,因此对于那些在乎磁盘和带宽资源的用户而言,配置ZStandard算法似乎是个不错的选择,但如果追求应用TPS,就目前的Kafka而言LZ4依然是最好的选择。











