关于无限级分类
第一种方案:
使用递归算法,也是使用频率最多的,大部分开源程序也是这么处理,不过一般都只用到四级分类。 这种算法的数据库结构设计最为简单。category表中一个字段id,一个字段fid(父id)。这样可以根据WHERE id = fid来判断上一级内容,运用递归至最顶层。
分析:通过这种数据库设计出的无限级,可以说读取的时候相当费劲,所以大部分的程序最多3-4级分类,这就足以满足需求,从而一次性读出所有的数据,再对得到数组或者对象进行递归。本身负荷还是没太大问题。但是如果分类到更多级,那是不可取的办法。
这样看来这种分类有个好处,就是增删改的时候轻松了…然而就二级分类而言,采用这种算法就应该算最优先了。
第二种方案:
设置fid字段类型为varchar,将父类id都集中在这个字段里,用符号隔开,比如:1,3,6
这样可以比较容易得到各上级分类的ID,而且在查询分类下的信息的时候,
可以使用:SELECT * FROM category WHERE pid LIKE “1,3%”。
分 析:相比于递归算法,在读取数据方面优势非常大,但是若查找该分类的所有 父分类 或者 子分类 查询的效率也不是很高,至少也要二次query,从某种意义看上,个人觉得不太符合数据库范式的设计。倘若递增到无限级,还需考虑字段是否达到要求,而且 在修改分类和转移分类的时候操作将非常麻烦。
暂时,在自己项目中用的就是类似第二种方案的解决办法。就该方案在我的项目中存在这样的问题, 如果当所有数据记录达到上万甚至10W以上后,一次性将所以分类,有序分级的现实出来,效率很低。极有可能是项目处理数据代码效率低带来的。现在正在改良。
第三种方案:
无限级分类----改进前序遍历树
那 么理想中的树型结构应具备哪些特点呢?数据存储冗余小、直观性强;方便返回整个树型结构数据;可以很轻松的返回某一子树(方便分层加载);快整获以某节点 的祖谱路径;插入、删除、移动节点效率高等等。带着这些需求我查找了很多资料,发现了一种理想的树型结构数据存储及操作算法,改进的前序遍历树模型 (The Nested Set Model)。
原理:
我们先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写 上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你沿着树的边界走啊走(这就是“遍历”),然后同时在每个节点的左边和右边写上 数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
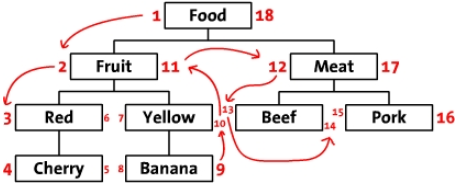
我 们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个值, 所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit” 节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
表结构设计:

那 么我们怎样才能通过一个SQL语句把所有的分类都查询出来呢,而且要求如果是子类的话前面要打几个空格以表现是子分类。要想查询出所有分类很好 办:SELECT * FROM category WHERE lft>1 AND lft<18 ORDER BY lft这样的话所有的分类都出来了,但是谁是谁的子类却分不清,那么怎么办呢?我们仔细看图不难发现如果相邻的两条记录的右值第一条的右值比第二条的大那 么就是他的父类,比如food的右值是18而fruit的右值是11 那么food是fruit的父类,但是又要考虑到多级目录。于是有了这样的设计,我们用一个数组来存储上一条记录的右值,再把它和本条记录的右值比较,如 果前者比后者小,说明不是父子关系,就用array_pop弹出数组,否则就保留,之后根据数组的大小来打印空格。
以上内容引用出处:https://www.cnblogs.com/badbo...
关于第三种设计的更多资料请点击查看原文,因为过于复杂(过重)被使用的频率不高。
引出痛点
无限级分类(父子)是一种比较常用的表设计,每种设计方式突出优势的同时也带来缺陷,如:
- 第一种方案:表设计中只有 parent_id 字段,写入数据方便,困扰:查询麻烦,许多使用了 ORM 的项目被迫使用 SQL 解决该场景;
- 第二种方案:表设计中冗余子级id便于查询,困扰:添加/更新/删除的时候需要重新计算;
- 第三种方案:表设计中存储左右值编码,困扰:同上;
第一种方案的设计最简单,本文后面的内容是在该基础上,使用 FreeSql 实现 ToTreeList(内存加工树型)、AsTreeCte(实现递归向下/向上查询),满足大众日常使用。
关于 FreeSql
FreeSql 是功能强大的对象关系映射技术(O/RM),支持 .NETCore 2.1+ 或 .NETFramework 4.0+ 或 Xamarin,以 MIT 开源协议托管于 github,单元测试数量 4528个,nuget 下载量 151K,支持 MySql/SqlServer/PostgreSQL/Oracle/Sqlite/达梦/人大金仓/神州通用/Access;
源码地址:https://github.com/dotnetcore/FreeSql

作者说过:每一个功能代表他的一撮头发!
第一步:定义导航属性
FreeSql 导航属性之中,有针对父子关系的设置方式,ToTreeList/AsTreeCte 依赖该设置,如下:
public class Area
{
[Column(IsPrimary = true)]
public string Code { get; set; }
public string Name { get; set; }
public virtual string ParentCode { get; set; }
[Navigate(nameof(ParentCode)), JsonIgnore] //JsonIgnore 是 json.net 的特性
public Area Parent { get; set; }
[Navigate(nameof(ParentCode))]
public List<Area> Childs { get; set; }
}关于导航属性
定义 Parent 属性,在表达式中可以这样:
fsql.Select<Area>()
.Where(a => a.Parent.Parent.Parent.Name == "中国")
.First();定义 Childs 属性,在表达式中可以这样(子查询):
fsql.Select<Area>()
.Where(a => a.Childs.AsSelect().Any(c => c.Name == "北京"))
.First();定义 Childs 属性,还可以使用【级联保存】、【贪婪加载】 等等操作。
添加测试数据
fsql.Delete<Area>().Where("1=1").ExecuteAffrows();
var repo = fsql.GetRepository<Area>();
repo.DbContextOptions.EnableAddOrUpdateNavigateList = true;
repo.DbContextOptions.NoneParameter = true;
repo.Insert(new Area
{
Code = "100000",
Name = "中国",
Childs = new List<Area>(new[] {
new Area
{
Code = "110000",
Name = "北京",
Childs = new List<Area>(new[] {
new Area{ Code="110100", Name = "北京市" },
new Area{ Code="110101", Name = "东城区" },
})
}
})
});第二步:使用 ToTreeList 返回树型数据
配置好父子属性之后,就可以这样用了:
var t1 = fsql.Select<Area>().ToTreeList();
Assert.Single(t1);
Assert.Equal("100000", t1[0].Code);
Assert.Single(t1[0].Childs);
Assert.Equal("110000", t1[0].Childs[0].Code);
Assert.Equal(2, t1[0].Childs[0].Childs.Count);
Assert.Equal("110100", t1[0].Childs[0].Childs[0].Code);
Assert.Equal("110101", t1[0].Childs[0].Childs[1].Code);查询数据本来是平面的,ToTreeList 方法将返回的平面数据在内存中加工为树型 List 返回。
[
{
"ParentCode": null,
"Childs": [
{
"ParentCode": "100000",
"Childs": [
{
"ParentCode": "110000",
"Childs": [],
"Code": "110100",
"Name": "北京市"
},
{
"ParentCode": "110000",
"Childs": [],
"Code": "110101",
"Name": "东城区"
}
],
"Code": "110000",
"Name": "北京"
}
],
"Code": "100000",
"Name": "中国"
}
]第三步:使用 AsTreeCte 递归查询
若不做数据冗余的无限级分类表设计,递归查询少不了,AsTreeCte 正是解决递归查询的封装,方法参数说明:
| 参数 | 描述 |
|---|---|
| (可选) pathSelector | 路径内容选择,可以设置查询返回:中国 -> 北京 -> 东城区 |
| (可选) up | false(默认):由父级向子级的递归查询,true:由子级向父级的递归查询 |
| (可选) pathSeparator | 设置 pathSelector 的连接符,默认:-> |
| (可选) level | 设置递归层级 |
通过测试的数据库:MySql8.0、SqlServer、PostgreSQL、Oracle、Sqlite、达梦、人大金仓
姿势一:AsTreeCte() + ToTreeList
var t2 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte() //查询 中国 下的所有记录
.OrderBy(a => a.Code)
.ToTreeList(); //非必须,也可以使用 ToList(见姿势二)
Assert.Single(t2);
Assert.Equal("100000", t2[0].Code);
Assert.Single(t2[0].Childs);
Assert.Equal("110000", t2[0].Childs[0].Code);
Assert.Equal(2, t2[0].Childs[0].Childs.Count);
Assert.Equal("110100", t2[0].Childs[0].Childs[0].Code);
Assert.Equal("110101", t2[0].Childs[0].Childs[1].Code);
// WITH "as_tree_cte"
// as
// (
// SELECT 0 as cte_level, a."Code", a."Name", a."ParentCode"
// FROM "Area" a
// WHERE (a."Name" = '中国')
// union all
// SELECT wct1.cte_level + 1 as cte_level, wct2."Code", wct2."Name", wct2."ParentCode"
// FROM "as_tree_cte" wct1
// INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code"
// )
// SELECT a."Code", a."Name", a."ParentCode"
// FROM "as_tree_cte" a
// ORDER BY a."Code"姿势二:AsTreeCte() + ToList
var t3 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte()
.OrderBy(a => a.Code)
.ToList();
Assert.Equal(4, t3.Count);
Assert.Equal("100000", t3[0].Code);
Assert.Equal("110000", t3[1].Code);
Assert.Equal("110100", t3[2].Code);
Assert.Equal("110101", t3[3].Code);
//执行的 SQL 与姿势一相同姿势三:AsTreeCte(pathSelector) + ToList
设置 pathSelector 参数后,如何返回隐藏字段?
var t4 = fsql.Select<Area>()
.Where(a => a.Name == "中国")
.AsTreeCte(a => a.Name + "[" + a.Code + "]")
.OrderBy(a => a.Code)
.ToList(a => new {
item = a,
level = Convert.ToInt32("a.cte_level"),
path = "a.cte_path"
});
Assert.Equal(4, t4.Count);
Assert.Equal("100000", t4[0].item.Code);
Assert.Equal("110000", t4[1].item.Code);
Assert.Equal("110100", t4[2].item.Code);
Assert.Equal("110101", t4[3].item.Code);
Assert.Equal("中国[100000]", t4[0].path);
Assert.Equal("中国[100000] -> 北京[110000]", t4[1].path);
Assert.Equal("中国[100000] -> 北京[110000] -> 北京市[110100]", t4[2].path);
Assert.Equal("中国[100000] -> 北京[110000] -> 东城区[110101]", t4[3].path);
// WITH "as_tree_cte"
// as
// (
// SELECT 0 as cte_level, a."Name" || '[' || a."Code" || ']' as cte_path, a."Code", a."Name", a."ParentCode"
// FROM "Area" a
// WHERE (a."Name" = '中国')
// union all
// SELECT wct1.cte_level + 1 as cte_level, wct1.cte_path || ' -> ' || wct2."Name" || '[' || wct2."Code" || ']' as cte_path, wct2."Code", wct2."Name", wct2."ParentCode"
// FROM "as_tree_cte" wct1
// INNER JOIN "Area" wct2 ON wct2."ParentCode" = wct1."Code"
// )
// SELECT a."Code" as1, a."Name" as2, a."ParentCode" as5, a.cte_level as6, a.cte_path as7
// FROM "as_tree_cte" a
// ORDER BY a."Code"更多姿势...请根据代码注释进行尝试