
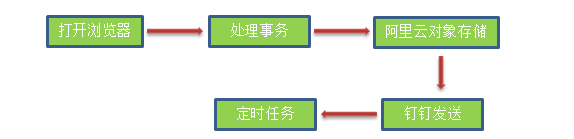
在进行Python截取网络报表并发送钉钉群过程中,碰到一些问题,也用到一些工具,在这里做一下简单总结。整个过程归纳如图:
1 版本配置
windows 10
Google Chrome 74.0.3729.131(正式版本) (64 位)
python 3.7.1 selenium:3.141.0
2 打开浏览器
2.1 打开浏览器
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('log-level=3') # suppress selenium logging to stdout
options.add_argument('Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36')
driver = webdriver.Chrome(options=options)
执行上面的代码,会出现以下错误:
WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
这是因为没有找到 chromedriver.exe 可执行文件,两种解决方案如下:
1.找到 chromedriver.exe 的路径,并将其作为参数添加(注意,不是 chrome.exe 的路径)
driver = webdriver.Chrome(executable_path='/path/to/chromedriver.exe', options=options)
2.安装 webdriver_manager 模块,并设置参数
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
3.浏览器有时打不开,可能是由于 Google Chrome 版本自动更新之后,chromedriver.exe 版本不再对其支持,因此需要及时更新版本,或者停止 Google Chrome 自动更新。
2.2 浏览器无界面模式最大化(headless)
options.add_argument('--headless')
driver = webdriver.Chrome(ChromeDriverManager().install(), options = options)
在浏览器使用 headless 模式时,如果调整窗口大小,需要使用如下方法:
driver.set_window_position(0, 0)
driver.set_window_size(1366, 768) # 分辨率为 1366 X 768
如果浏览器不使用 headless 模式, 则也可以用如下两种方法,下面两种方法在 headless 模式下不会执行(原因不确定):
options.add_argument('--start-maximized')
# 或者
driver.maximize_window()
3 查找节点
Selenium 提供了一系列查找节点的方法,还可以查找单个节点和多个节点。具体语法为 find_element_by_...(),如果有多个节点,用这种方法查找,只能得到第一个节点,这时候可以使用 find_elements_by_...() 方法。

from selenium import webdriver
driver = webdriver.Chrome() # 假设可以正常打开浏览器
driver.get('https://www.taobao.com')
# 根据 id 查找
driver.find_element_by_id('q')
# 根据 CSS 选择器查找
driver.find_element_by_css_selector('#q')
# 根据 XPath 查找
driver.find_element_by_xpath('//*[@id="q"]')
# 两个类 ng-star-inserted 和 caption
driver.find_elements_by_css_selector("div.ng-star-inserted.caption")
# 通过两级类名查找
driver.find_elements_by_xpath("//div[contains(@class, 'chart-title-wrap')]/ancestor::div[contains(@class,'smartchart-box')]")
# 通过两个类查找
driver.find_elements_by_xpath("//input[@name='login' and @type='submit']")
# 其它方法
find_element_by_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_tag_name()
find_element_by_class_name()
4 阿里云对象存储(Object Storage Service,简称 OSS)
我在报表制作过程中,主要是进行网页截图和本地代码作图,并将它们保存到本地,然后将这些图像上传到阿里云对象存储空间获取图像外链,最后将外链嵌入到要发送钉钉的 Markdown 消息中。
注:直接将本地图片链接嵌入到 Markdown 消息中未取得成功,不知道有没有解决方法。
使用 OSS 管理控制台来完成 OSS 基本操作步骤如下:

还可以通过使用图形化管理工具 ossbrowser、命令行管理工具 ossutil,和 API/SDK 的方式来完成基本操作。
几个概念
存储空间(Bucket):存储空间是您用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间
对象/文件(Object):对象是 OSS 存储数据的基本单元,也被称为 OSS 的文件。对象由元信息(Object Meta)、用户数据(Data)和文件名(Key)组成。对象由存储空间内部唯一的 Key 来标识。
访问密钥(AccessKey):AccessKey,简称 AK,指的是访问身份验证中用到的 AccessKeyId 和 AccessKeySecret。
下面以 Python SDK 的方式来完成整个过程:
创建存储空间
import oss2
# 阿里云主账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM账号进行API访问或日常运维
auth = oss2.Auth('<yourAccessKeyId>', '<yourAccessKeySecret>')
# Endpoint以杭州为例,其它Region请按实际情况填写。
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', '<yourBucketName>')
# 设置存储空间为私有读写权限。
bucket.create_bucket(oss2.models.BUCKET_ACL_PRIVATE)
上传文件
# <yourObjectName>为文件上传到bucket后的名称
# <yourLocalFile>由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt
bucket.put_object_from_file('<yourObjectName>', '<yourLocalFile>')
下载文件
# <yourLocalFile>由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt
bucket.get_object_to_file('<yourObjectName>', '<yourLocalFile>')
列举文件
from itertools import islice
# oss2.ObjectIteratorr用于遍历文件,制定存储空间下的10个文件
for b in islice(oss2.ObjectIterator(bucket), 10):
print(b.key)
删除文件
# <yourObjectNmae> 为存储空间上的制定文件
bucket.delete_object('<yourObjectName>')
上传本地图像至存储空间,并获得其外链
fig_url = bucket.sign_url('GET', os.path.basename(p), 180) # 生成图片外链,180s后取消
5 钉钉群发送报表
首先在钉钉 “群设置“ 中点击 “群机器人”,然后点击 “添加机器人”,点击 “自定义”,出现如下页面,其中 webhook 就是后面要用到推送报表至钉钉的链接。
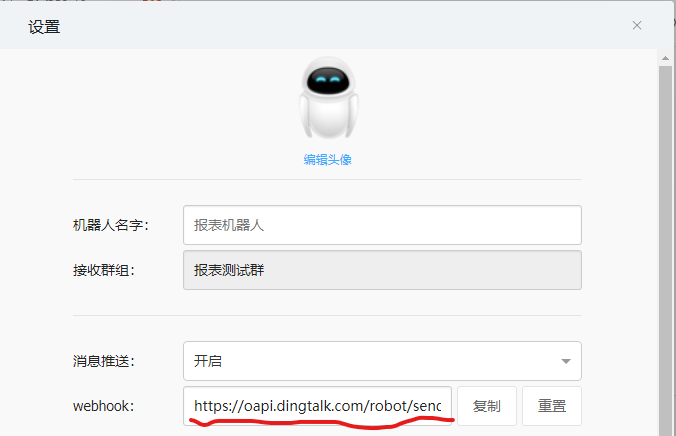
下面以推送 markdown 类型消息为例,列出解决方法。
5.1 使用 Python 模块 requests 发送
headers = {"Content-Type": "application/json"}
# 消息类型和数据格式参照钉钉开发文档
data = {
"msgtype": "markdown",
"markdown": {
"title": "首屏会话透出的展示内容",
"text": "# 这是支持markdown的文本 \n## 标题2 \n* 列表1 \n "
}
}
r = requests.post(webhook, data=json.dumps(data), headers=headers)
5.2 使用 Python 模块 DingtalkChatbot 发送
import dingtalkchatbot.chatbot as cb
robot = cb.DingtalkChatbot(webhook)
robot.send_markdown(title='首屏会话透出的展示内容',
text="# 这是支持markdown的文本 \n## 标题2 \n* 列表1 \n ")
6 定时发送消息
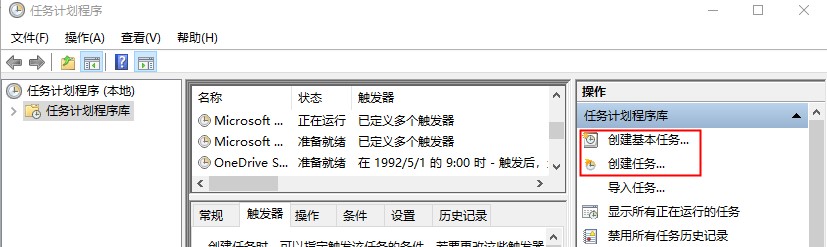
windows 10 找到 任务计划程序,然后选择创建基本任务或者创建任务。
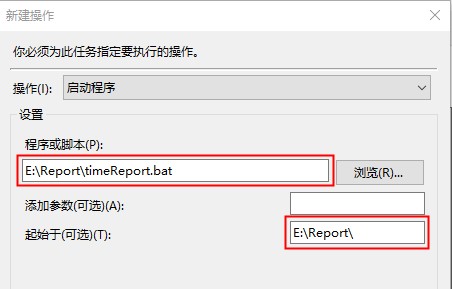
设置自己的选项,主要是红色方框里面的内容一定要填写,这里启动的是 .bat 文件。
下面是 .bat 文件的内容,由于 timeReport.py 文件路径和 .bat 文件路径一致,因此不需要再加上 timeReport.py 文件路径。

在运行上面的定时任务时,会自动跳出命令行窗口,这样有可能会影响我们的工作,也有可能我们不小心影响到定时任务的运行。因此,如果能隐藏命令行窗口的话,那绝对是很妙的。设置如下:

后面我们在 任务计划程序 中运行 timeReport.vbs 文件就可以了,当然也要注意路径的设置。











