
我们先抛出一个问题:
LSM树是HBase里使用的非常有创意的一种数据结构。在有代表性的关系型数据库如MySQL、SQL Server、Oracle中,数据存储与索引的基本结构就是我们耳熟能详的B树和B+树。而在一些主流的NoSQL数据库如HBase、Cassandra、LevelDB、RocksDB中,则是使用日志结构合并树(Log-structured Merge Tree,LSM Tree)来组织数据。
首先,我们从B+树讲起
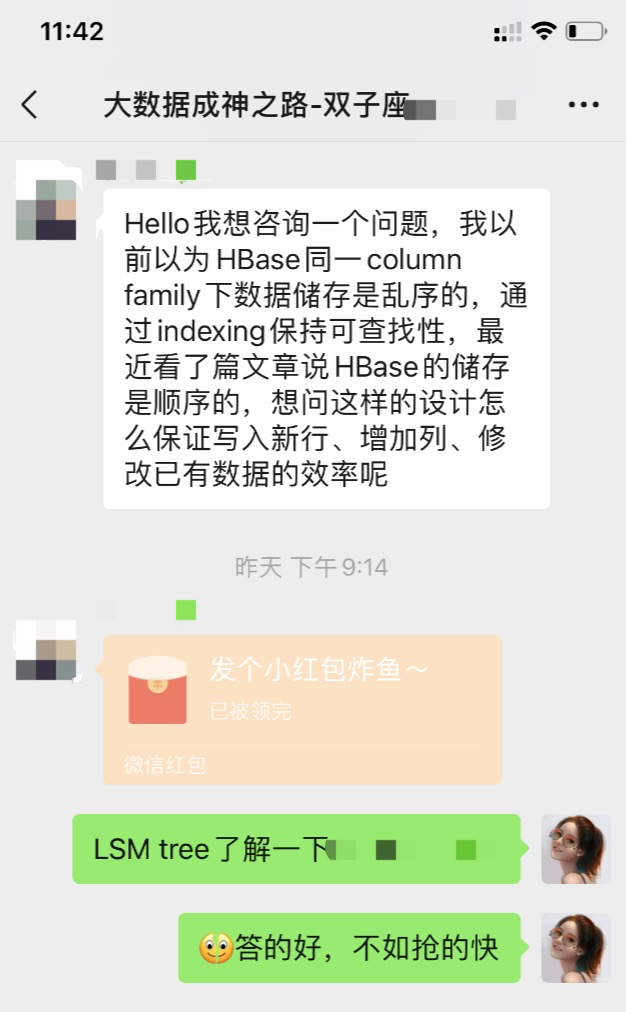
为什么在RDBMS中我们需要B+树(或者广义地说,索引)?一句话:减少寻道时间。在存储系统中广泛使用的HDD是磁性介质+机械旋转的,这就使得其顺序访问较快而随机访问较慢。使用B+树组织数据可以较好地利用HDD的这种特点,其本质是多路平衡查找树。一个典型的B+树如下图所示:
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
如果你对B+树不够熟悉,可以参考这里:https://blog.csdn.net/b_x_p/article/details/86434387
那么,B+树有什么缺点呢?
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
LSM Tree
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
LSM Tree(Log-structured merge-tree)起源于1996年的一篇论文:The log-structured merge-tree (LSM-tree)。当时的背景是:为一张数据增长很快的历史数据表设计一种存储结构,使得它能够解决:在内存不足,磁盘随机IO太慢下的严重写入性能问题。
LSM Tree(Log-structured merge-tree)广泛应用在HBase,TiDB等诸多数据库和存储引擎上:

我们来看看大佬设计这个数据结构:
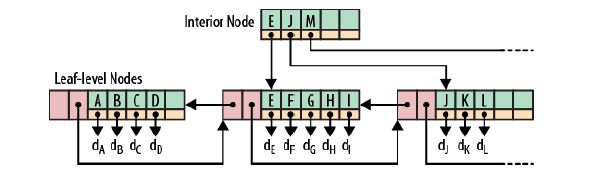
Ck tree是一个有序的树状结构,数据的写入流转从C0 tree 内存开始,不断被合并到磁盘上的更大容量的Ck tree上。由于内存的读写速率都比外存要快非常多,因此数据写入的效率很高。并且数据从内存刷入磁盘时是预排序的,也就是说,LSM树将原本的随机写操作转化成了顺序写操作,写性能大幅提升。不过它牺牲了一部分读性能,因为读取时需要将内存中的数据和磁盘中的数据合并。
回到Hbase来,我们在之前的文章中《Hbase性能优化手册》中提到过Hbase的读写流程:
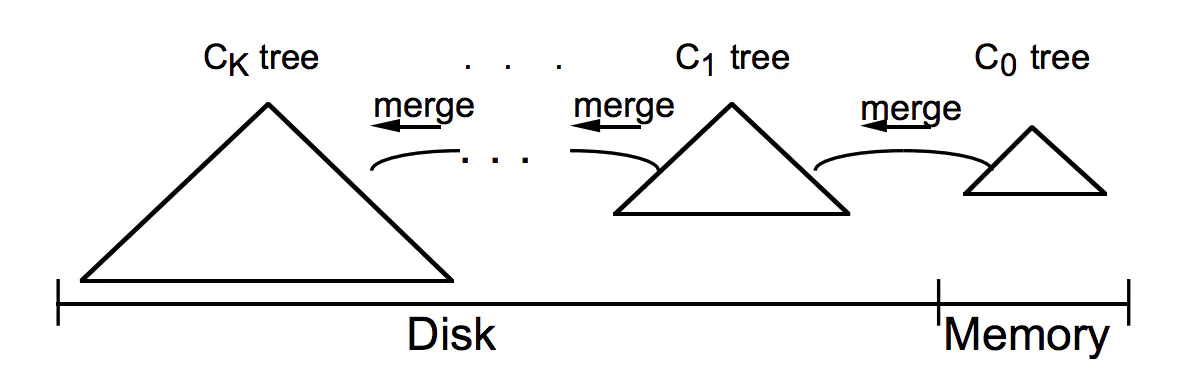
MemStore是HBase中C0的实现,向HBase中写数据的时候,首先会写到内存中的MemStore,当达到一定阀值之后,flush(顺序写)到磁盘,形成新的StoreFile(HFile),最后多个StoreFile(HFile)又会进行Compact。
memstore内部维护了一个数据结构:ConcurrentSkipListMap,数据存储是按照RowKey排好序的跳跃列表。跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。
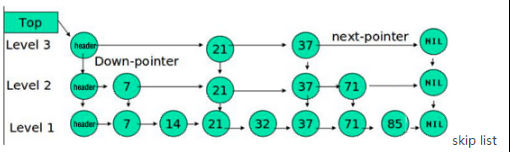
HBase为了提升LSM结构下的随机读性能,还引入了布隆过滤器(建表语句中可以指定),对应HFile中的Bloom index block,其结构图如下所示。
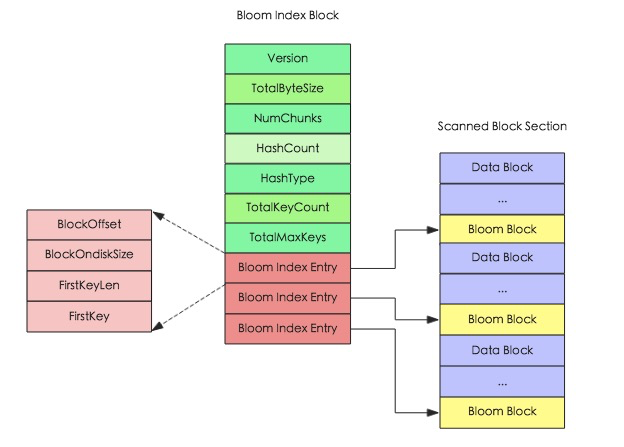
通过布隆过滤器,HBase就能以少量的空间代价,换来在读取数据时非常快速地确定是否存在某条数据,效率进一步提升。












