
大魏说:
Topic的Speaker是IBM的两位专家。、
Istio是一个迭代非常快的开源项目,在2019年初1.0版本发布,如今最新版本已经是1.2。在1.1版本中,我进行过一些测试,Istio绝大多数的功能是没问题的。但在测试限流的时候,有时候不生效。Istio1.1的限流需要借助于memqouta或redisqouta。前者不能做HA,后者需要在K8S中部署redis(通过缓存做限流)。希望在1.2版本这个功能能够更健壮。注入sidecar会造成性能下降。这也是红帽在OCP中不启动Sidecar的全自动注入的方式原因。
Istio分为控制平面和数据平面。数据平面是pod中的sidercar,实际上就是代理。有了代理,好处是可以通过代理用声明式的配置调整路由等策略。缺点是代理必然会带来性能的损耗。Istio官方公布的数据,在Istio内部微服务之间通讯,端到端的延迟会增加10毫秒(出栈2毫秒,入栈8毫秒)。整体性能损耗30%左右。此外,在很多Istio的测试中,很多同学表示Istio的并发上不去。之前我由于缺乏大规模的测试环境,无法做性能测试,因此没找到太多的方法。IBM两位专家分享的内容是很有借鉴意义的。



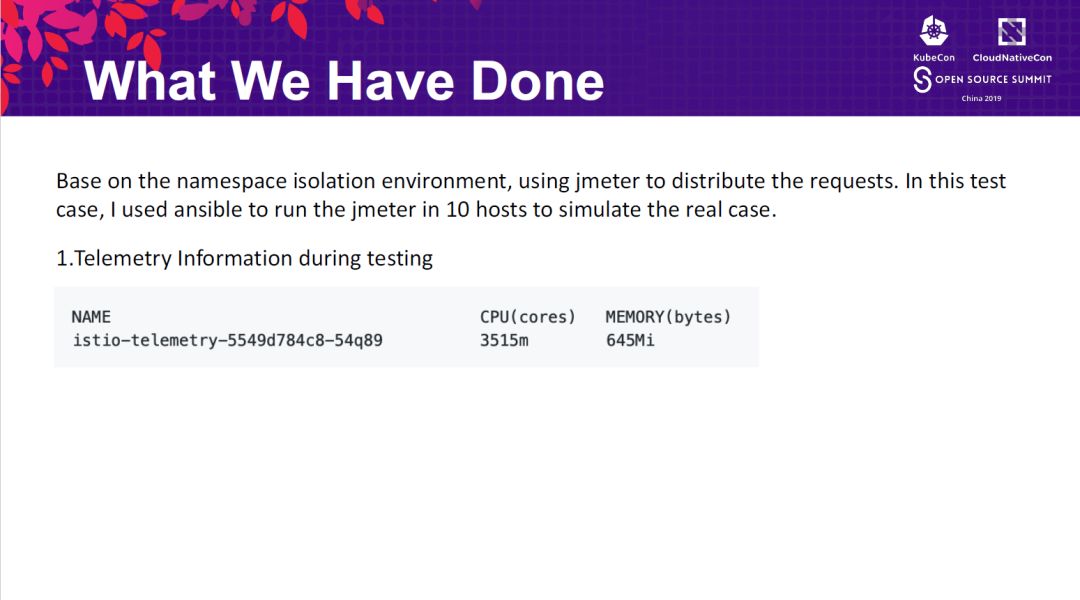
下图可以看到,测试是基于做了sidecar注入的6000个pod(3000个service),和4000个未被注入sidecarpod(1000个service)做的。两类pod分别未在100个namesapce里。当集群中部署了4000个未注入sidecar的pod时,我们可以看到,由于pod未和istio发生任何关系,Istio占用资源不高。

当6000个注入sidecar的pod也创建完毕以后,Istio组件占用资源的数量激增。由于启用了HPA,所以istio-polot自动做了横向扩展,每个实例占用大量内存,但是,Istio和envoy的连接数远远没到6000。也就是说,Istio把资源占了,但压力上不去。

解决这个问题的第一个方法是启用命名空间隔离。这是istio1.1中的功能。这个功能会创建一个全局的Istio命名空间,负责存放istio组件,然后将不同的受控微服务放到不同的命名空间,这些命名空间之间是相互隔离的。但他们都可以和全局的Istio命名空间之间通信。这样做的好处是减少微服务之间不必要的交互,但前提是需要做好微服务之间的规划。

除此之外,IBM的专家们在每一个namespace中创建一个ingressgateway。默认情况下,一个Istio配置一个ingressgateway,作为微服务流量的入口。如果部署到Openshift上,会自动在router上创建ingressgateway的路由。这样入口流量会先经过router再经过ingressgateway。如果我们在每个namespace中都配置一个ingressgateway,那么只需要在router上进行控制即可。这样做的好处是降低全局ingressgateway的瓶颈。当然,此时如果入口流量过大,router同样可能存在性能的瓶颈。这时候可以配置多个router,在前段配置硬件负载均衡器。


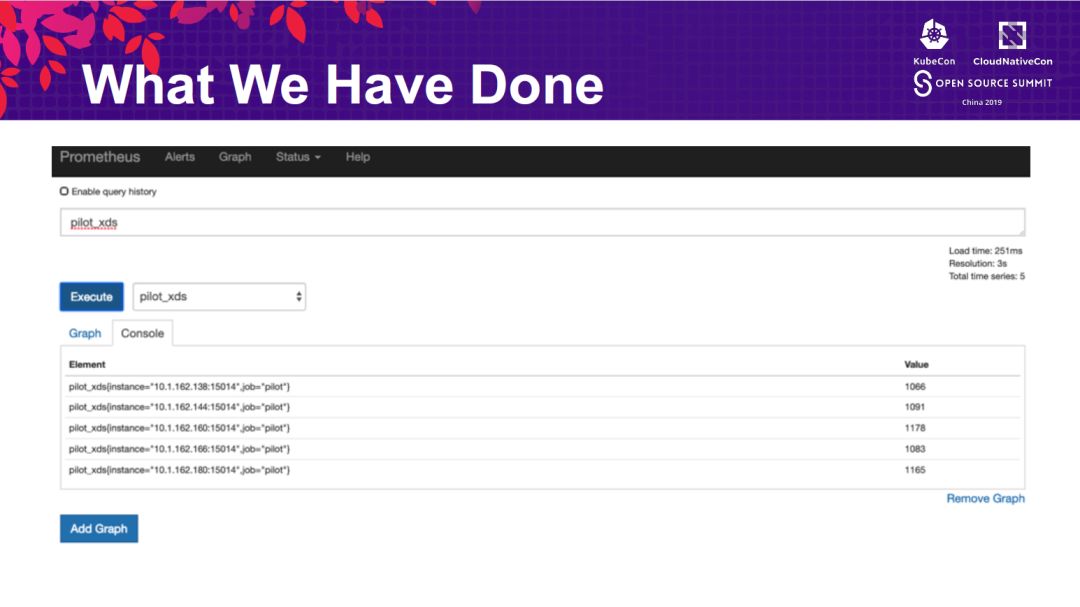
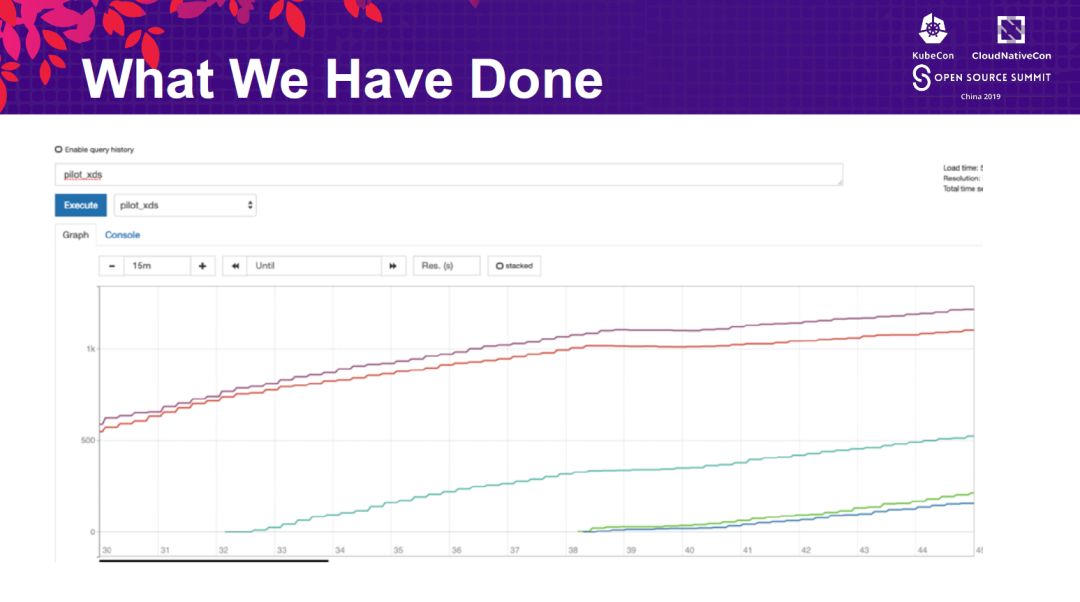
基于上面的调整,进行压力测试:
将注入sidecar和未注入sidecar的pod性能进行对比,注入sidecar会造成性能下降26%。低于官方的数字。


最佳实践如下:
启用命名空间隔离
每个命名空间创建一个ingressgateway
禁用policy组件(这个配置,在目前Istio on OpenShift上是建议打开的disablePolicyChecks:false,负责会造成一个istio配置不生效。因此这个建议需要进一步在OpenShift上验证)
调整普罗米修斯的参数以便减少内存和CPU消耗。

Istio参数调整建议如下。如果是在OCP上安装Istio,可以参照如下文档。由于红帽安装Istio的方式是通过Operator(社区目前大多采用helm方式安装),因此参数与下面列的并不是所有都可以调整,需要进一步在OCP上验证。https://docs.openshift.com/container-platform/3.11/servicemesh-install/servicemesh-install.html#custom-resource-parameters

本文分享自微信公众号 - 大魏分享(david-share)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。














