
概述
记录自己在工作中将生产的数据按月保存在ES中(通过logstash采集kafka数据到ES),由于生产环境数据量比较庞大(一天的日志量大概在2500万条左右),为了后期减轻服务器压力,方便我们维护,所以需要对我们的日志进行处理,按月建立不同的ES索引库,能够查询最近6个月的日志,关闭前6个月不用的日志。
创建模板
如果用户每次新建一个索引的时候都需要手动创建mapping非常麻烦,es内部维护了template,template定义好了mapping,只要index的名称被template匹配到,那么该index的mapping就按照template中定义的mapping自动创建。而且template中定义了index的shard分片数量、replica副本数量等等属性。
模板样例
{
"order": 0, // 模板优先级
"template": "sample_info*", // 模板匹配的名称方式
"settings": {...}, // 索引设置
"mappings": {...}, // 索引中各字段的映射定义
"aliases": {...} // 索引的别名
}
settings定义了索引的属性,包括分片数量、副本数量、写入flush时间间隔。
"settings": {
"index": {
"refresh_interval": "10s",//每10秒刷新
"number_of_shards" : "5",//主分片数量
"number_of_replicas" : "2",//副本数量
"translog": {
"flush_threshold_size": "1gb",//内容容量到达1gb异步刷新
"sync_interval": "30s",//间隔30s异步刷新(设置后无法更改)
"durability": "async"//异步刷新
}
}
}
编写template,写入es
通过命令 put _template/[template名]{……}命令写入es
通过命令 get _template/[template名]查看是否写入template成功。如果template编写错误重新执行put命令覆盖即可
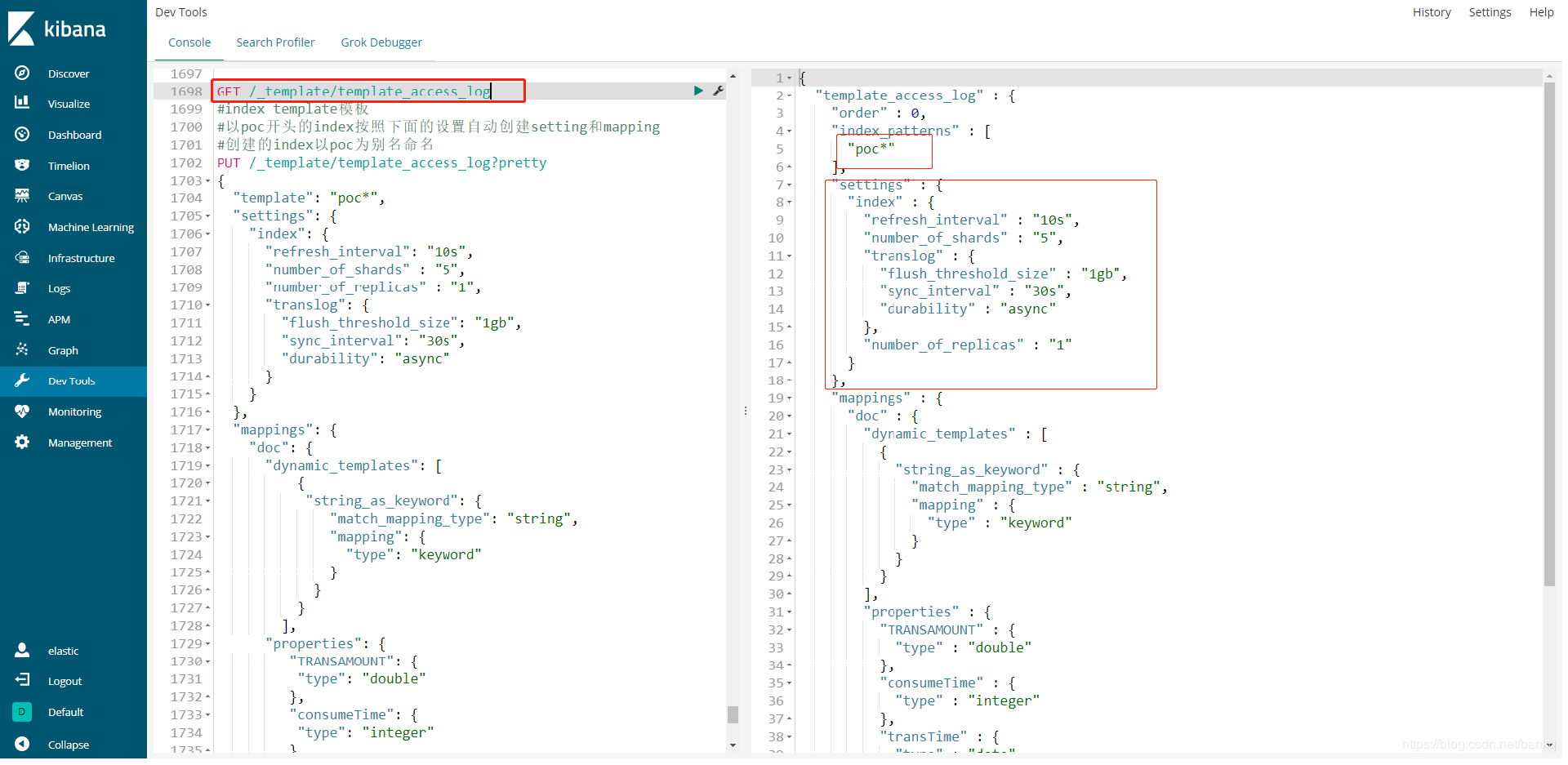
附 自己的template
PUT /_template/template_access_log
{
"template": "poc*",
"settings": {
"index": {
"refresh_interval": "10s",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"translog": {
"flush_threshold_size": "1gb",
"sync_interval": "30s",
"durability": "async"
}
}
},
"mappings": {
"doc": {
"dynamic_templates": [
{
"string_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"TRANSAMOUNT": {
"type": "double"
},
"consumeTime": {
"type": "integer"
},
"transTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
},
"aliases" : {
"poc" : {}
}
}
logstash6.5.4配置文件修改
input {
kafka{
group_id=> "logstash_bkq_test001"
topics=> "test_bkq"
bootstrap_servers=> "192.168.8.21:9092"
key_deserializer_class=> "org.apache.kafka.common.serialization.IntegerDeserializer"
value_deserializer_class=> "org.apache.kafka.common.serialization.StringDeserializer"
auto_offset_reset=> "latest"
client_id=> "logstash_bkq_test001"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["192.168.8.23:9200","192.168.8.24:9200","192.168.8.25:9200"]
index => "poc%{+yyyyMMdd}"
user => "elastic"
password => "******"
}
}
logstash往ES灌数据的时候按照index => "poc%{+yyyyMMdd}" 灌数据。












