
硬盘组成与读写
硬盘,拆过机的同志应该知道就是一块小刚体嘛。拆过主机硬盘和笔记本硬盘也应该知道不同的硬盘的接口是不一样的,主机的硬盘一般会有一条线连接到主板而笔记本的硬盘直接有插槽。这个概念只是为了引起硬盘有不同的种类存在,当我们在linux系统中输出命令fdisk -l的时候,大致会有设备名称等信息。其中有可能有**/dev/sd[a-p][1-15]或者/dev/hd[a-d][1-63]**等等,前者表示SCSI,SATA,USB等接口的磁盘文件名,后者表示IDE接口磁盘文件名(这个比较老了)。
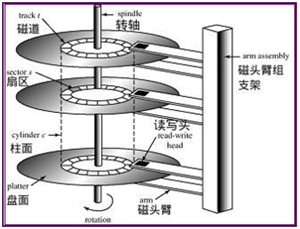
磁盘会有多个概念,为了方便理解,先设定一个场景,假定我们在吃鸡游戏的地图上,这个地图只有一个圆柱大楼,每层楼都是一个环形操场跑道。
- track磁道,就是操场上的某一条跑道。
- cylinder柱面,就是缩毒的时候毒边界所在的跑道,这指的是每层楼的处在毒边界的跑道。
- Sector扇区,就是如果把跑道划成不同小格的话,这么说吧,就是把环形甜甜圈切成好多小块,每个小块近似于小矩形,这个矩形就是扇区。
- Head磁头,如上图就是每层楼都有一只手臂读取某一跑道上的数据。
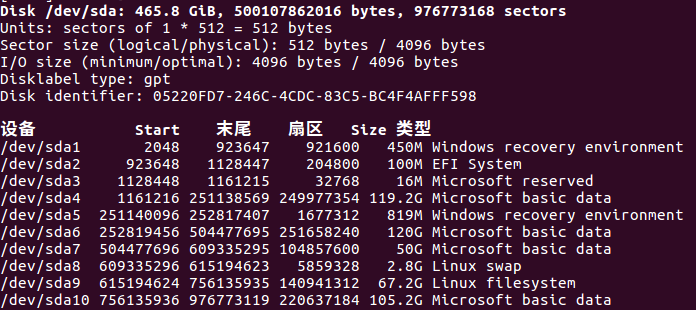
这是我的电脑的磁盘分布,一个扇区是512bytes,一次io读取是8个扇区能读到4KB。总的容量很明显是由255盘面*n柱面*m扇区(512bytes)构成的。
磁盘是如何读取数据的呢,我们知道买磁盘是有转速指标的,所以我们可以设想磁头不动当靠旋转就可以获得某柱面的所有磁道的数据。其实磁盘IO步骤就是如此。
- 寻道时间,磁头径向移动到达指定的磁盘位置
- 旋转延迟,等到指定的扇区到达磁头下
- 存取时间,读取目标扇区的数据
时间花费,1w转的磁盘旋转一圈是不到6ms,存取也就是零点几毫秒不然磁盘都转过去了是不是还要等一圈再来读取。。所以我们可以猜到寻道时间是最长的大概是3-15ms。
因此进行磁盘分区的时候,我们划分标准是以柱面作为分区****partition的最小单位。不然按照盘面来分区,那寻道时间的比重会增加自然增加了IO时间。可以看到上图,按照扇区连续性进行了分区。
我们应该清楚,现在只是分区完成,每一个区可以有自己独立的文件系统进行管理它所分配到的区域。有不同的文件系统体制,我们假定分配到的区域每一扇区给个序号从1到100。对于FAT格式,一个文件表示形式是链表的样式,可能是8->6->7->67->5等等,对于ext2格式,它将1-4作为一个inode的节点代表了一个文件,存储了这个文件的实际数据存储的block序号(5,6,7,8,67),我们成为索引式文件系统。
以上说的概念可以这么理解,地球就是一块硬盘,每一个国家就是一个分区,每一个国家自己的文件系统格式可以是资本主义也可以是社会主义。
Ext2文件系统(inode)
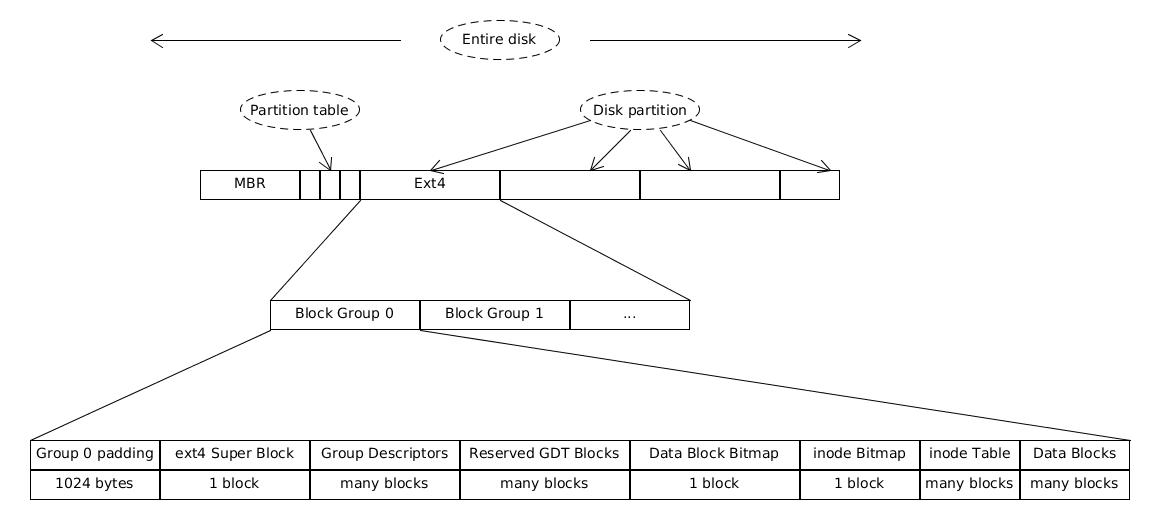
虽然我们标题说的是Ext2文件系统,但是图片放的是Ext4文件系统,区别只是GDT而已,为了跟进时代加进来无妨。
先谈谈该图的总体概念,Entire disk=MBR+Partition table+Partitions. Partition=boot sector+block group. block group=super lock+Group Descriptors+Reserved GDT Blocks+Data Block Bitmap+inode Bitmap+inode Table+Data Blocks.
其实这里设计到了启动操作系统的过程,这个以后再详细描述。大概思路是当我们经过了通电自检等进入BIOS到指定到磁盘启动,第一扇区是MBR和Partition table,分区表只有64B,我们知道磁盘分区最低单位是柱面,柱面范围是0-255,八个bit就可以表示,所以16B表示一个分区范围。一个磁盘理论上只能四个分区,所以为了拓展允许有3个主分区和一个扩展分区,这个扩展分区可以拥有多个逻辑分区。那么我们分好的每一个分区就是一个文件系统了。每一个分区都预留的boot sector是载入操作系统内核的引导代码,它的副本将放在MBR中,当然说双系统你可能更容易理解,每个分区可以指定一个系统,但是只有一个boot loader能放在MBR中,其中linux的boot loader可以释放权限加载别的文件系统的boot sector从而加载双系统了。
而且实际并不是每一个Block Group都是如此排布,太多super block说实话浪费空间,冗余的超级块和组描述符的副本只保留在组号为 0 或组号为 3,5,7 的倍数的块组中。同时还会有纯粹的数据存储块,只有后四者。
- 图中Group 0 padding 只存在于Block Group 0 中,实际上它就是boot sector。
- Super Block,记录整个文件系统相关的信息,是整个文件系统的首脑。记录了inode、block等信息包括修改挂载时间等。所以它有备份Block。
- Group Descrptor,文件系统描述符,具体记录inode的位置范围,block的位置范围等
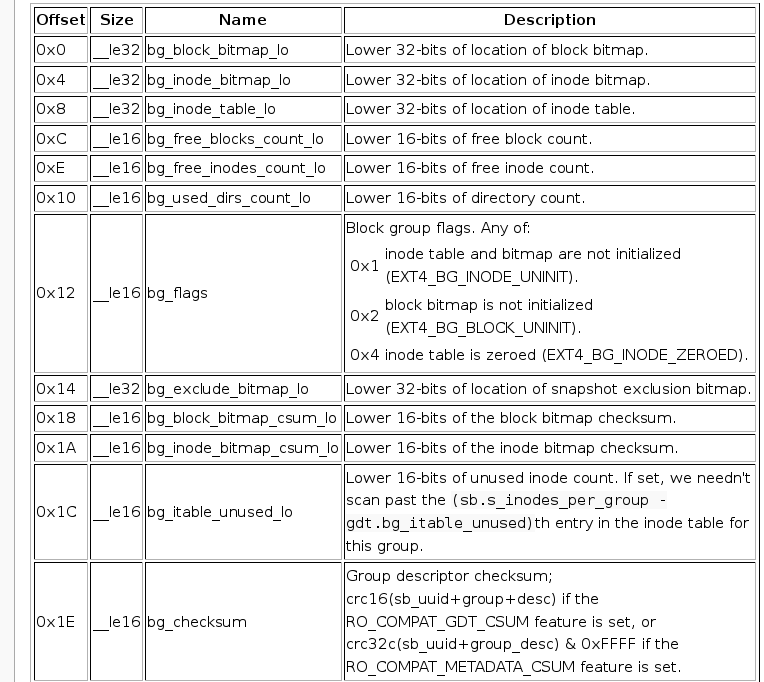
- Reserved GDT Blocks。用于文件系统未来的拓展
- Data Block Bitmap。用于记录块组内部数据块的使用情况。
- inode Bitmap。用于记录 inode table 中的 inode 的使用情况。
- inode table。每一个文件的meta信息就是一个inode,这个table表示该块内能指示的所有文件表。
- Data Block。文件的meta信息指向的实际存储内容数据段。
超级块信息
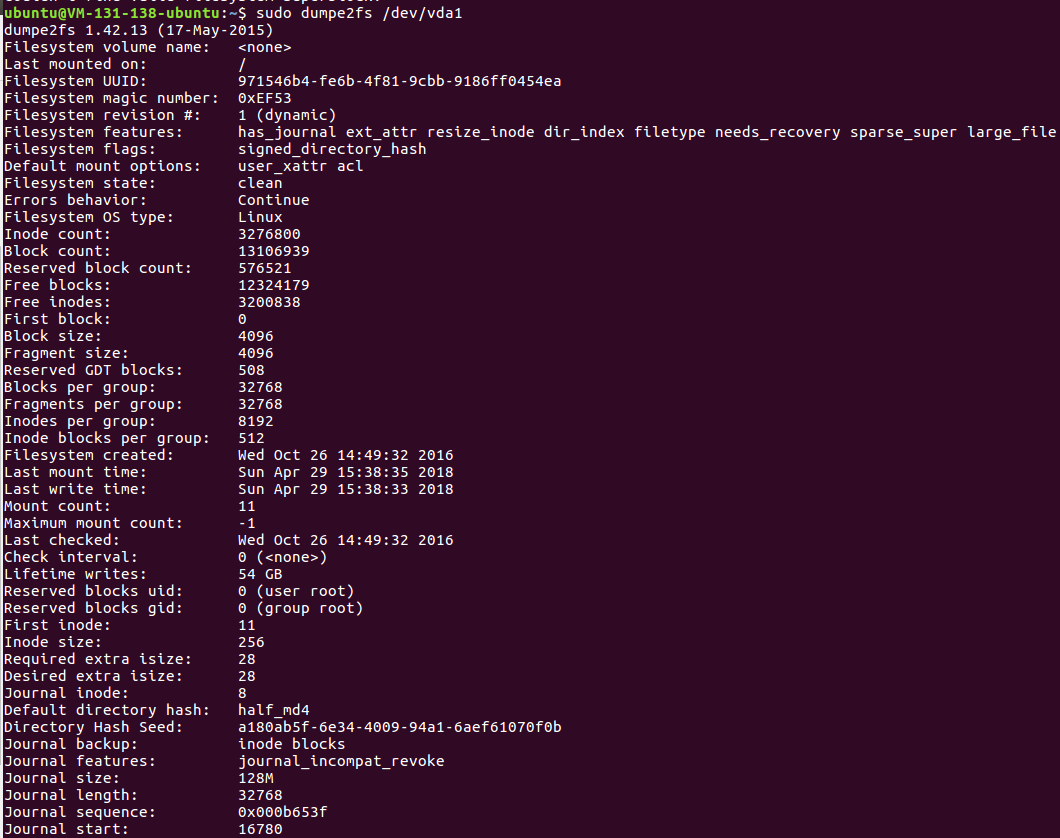
Group Block,注意信息有所不同
G0是起始的primary superblock,G1是存有super block,G2是纯粹数据存储。
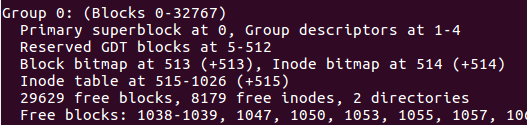
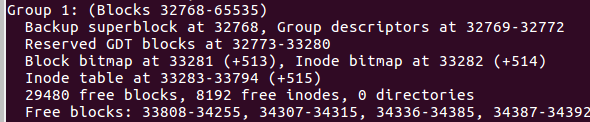
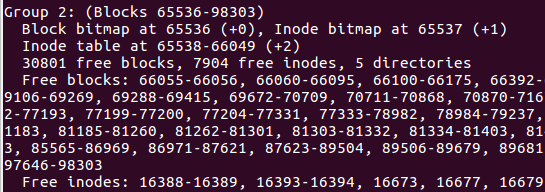
inodeTable
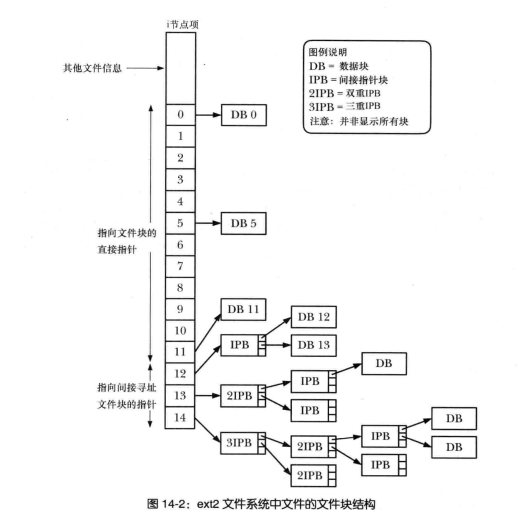
- 每一个文件仅占有一个inode而已。文件系统能够创建的文件数量和inode的数量有关系。
- 一个inode文件信息中,包括了访问的模式权限,所有者和组,大小,create time,access time,last modification time,deletion time,pointer,flag等。其中时间属性在原来ext3之前是32bytes,后来进行扩展到64bytes,使得有效时间从2038延长到了2466年。
- 就算是ext4中inode节点达到了256B(以前是128B),似乎也无法记录该文件中那么多block节点,所以前12个是直接block索引,然后还有间接、双间接、三间接索引,原理就是以block存储block。所以看图大概能明白。
Block data
这是block块的一种线性目录结构,它表述了存储的特殊数据表示格式,例如是目录文件的block,它将目录下的文件名及其对应的inode号记录在目录的block中。

目录树
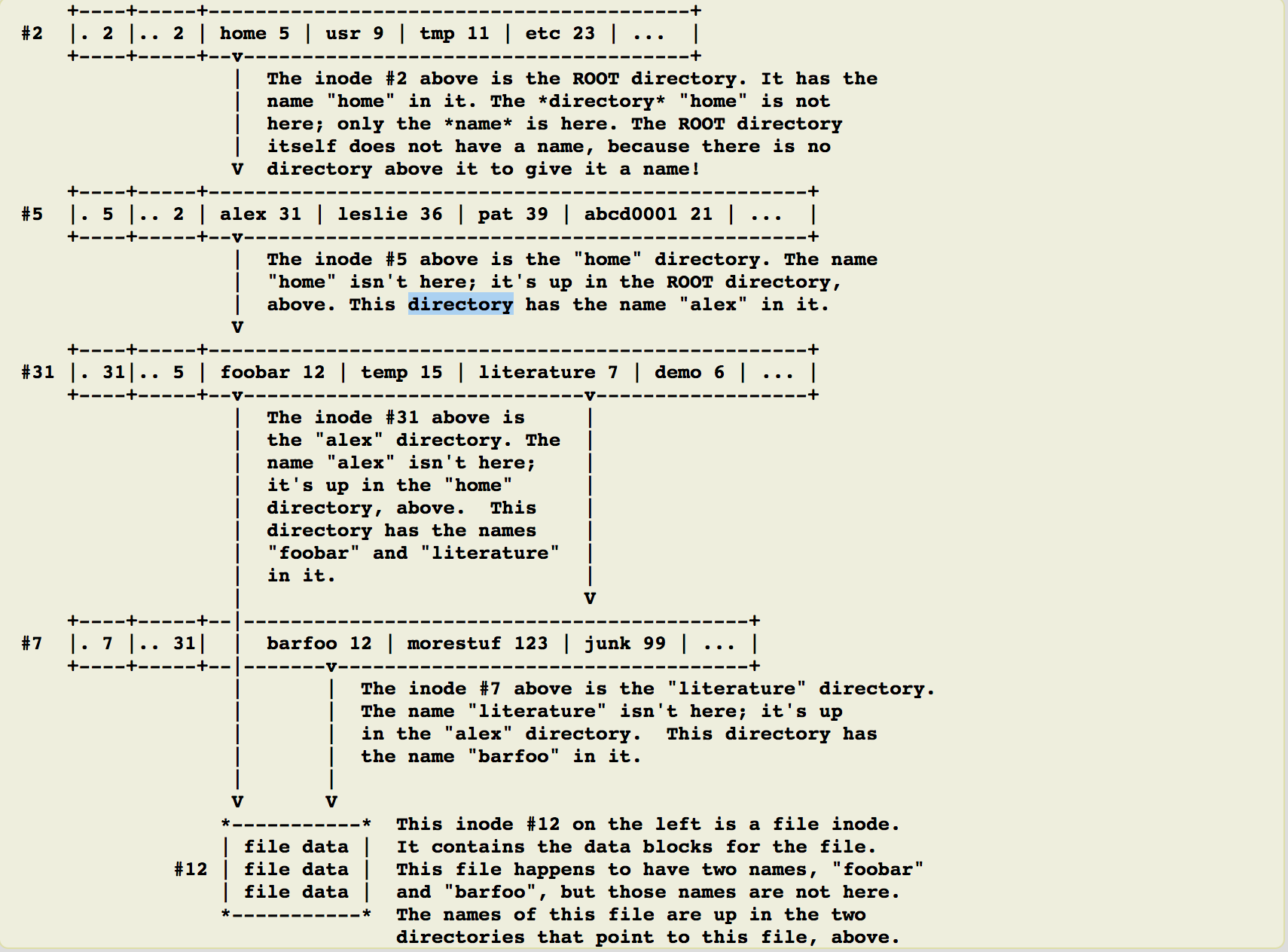
我们知道目录也是一个文件,一个文件的文件名由目录文件存储,文件系统新建一个目录时会分配一个inode与至少一个block给该目录,inode记录目录的相关权限和属性,分配到的block记录目录下的文件名和该文件名占用的inode号码信息。所以indoe本身不记录文件名,文件名记录在目录的block中,因此新增/删除/重命名文件名与目录的w权限有关。那么因为文件名记录在目录的block中,因此当我们要读某一个文件,必须经过目录的inode与block然后才能找到哪个待读取的文件的inode才能读到block数据。

目录树是由根目录读起,系统通过挂载点的挂载信息就可以找到挂载点的inode号码,通常一个文件系统的最顶层indoe号码是2(1是指向不占空间的proc目录),然后通过根目录一层层往下读。
如图我们访问/etc/passwd需要通过/+rx权限(r是读,x是进入该目录)然后一步步找到下一个inode节点。
其他
- Ext3文件系统加入了日志文件系统,有点像数据库的日志模式,当系统要写入文件数据之前先记录,然后实际写入,跟新中间数据(super block等),结束后再日志中写上完成。
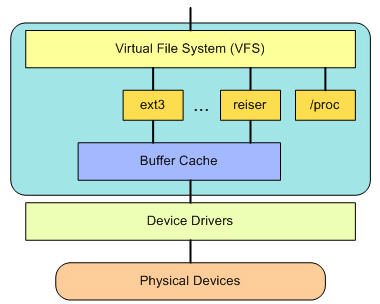
- 文件系统的操作一般会有缓存,是为了避免频发的IO,可以通过sync强迫内存中设置为Dirty的文件回写到磁盘。
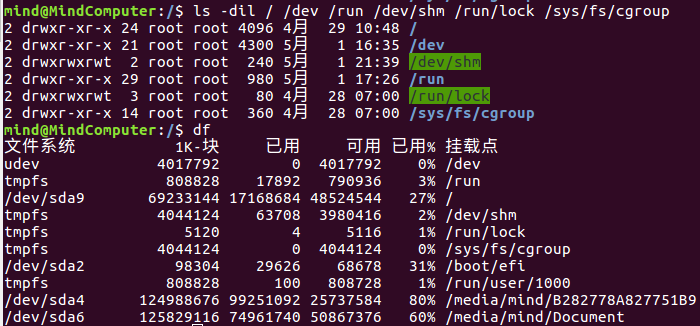
- 挂载点,一个文件系统和目录树结合的操作成为挂载,挂载点一定是目录,该目录为进行该文件系统的入口。如下图,不同的目录对应inode都为初始的2,是不同的文件系统。
- VFS
参考











