
智联招聘创建于1994年,拥有1.4亿职场人用户,累计合作企业数达400万家。为了更好的支持公司的业务发展,我们于2017年底上线了基于kubernetes的容器云平台。当前我们内网共维护4套Kubernetes集群,主要服务于公司销售及职能体系。目前已经有200多个应用实现了容器化改造,实例数量600多个。本文主要和大家分享Kubernetes在智联内网应用的整体架构,以及我们在使用中踩过的一些坑。背景介绍

智联招聘内网开发团队多,项目众多,运维团队维护的项目数量超过200个。
这些项目均部署在虚拟机/物理机上,除了少数访问量较高的关键应用外,其他应用资源占比不高。
对于这些项目的管理,团队内部自研了一套部署平台做应用部署、回滚等操作,效果不错。但是仍然存在以下几个问题:
实例间资源隔离。尤其是在业务高峰期,虚拟机宿主实例间CPU/内存资源争抢。
应用出异常时需要人工干预,导致项目可用率降低。
回滚应用过程耗时较长 公司业务发展快,对系统稳定性要求越来越高,我们急需解决上述问题。
技术选型

容器技术近年来已经趋于成熟,越来越多的企业已经开始使用Docker。所以我们采用项目容器化来解决上述问题,对于容器集群的管理和编排工具,我们选择了Google开源的项目Kubernetes,优势如下:
服务负载均衡
服务发现
应用高可用
滚动升级
自动伸缩
快速部署
资源限制
网络隔离
使用到的Kubernetes组件如下:
镜像仓库(Harbor,VMware开源产品)
网络插件Calico(使用BGP模式,方便业务定位故障源)
日志收集(Filebeat -> Kafka –> Logstash -> Elasticsearch -> Kibana)
DNS插件CoreDNS
服务暴露(Nginx Ingress)
监控(Prometheus+Grafana)
自研部署系统集成Kubernetes应用部署
集群架构
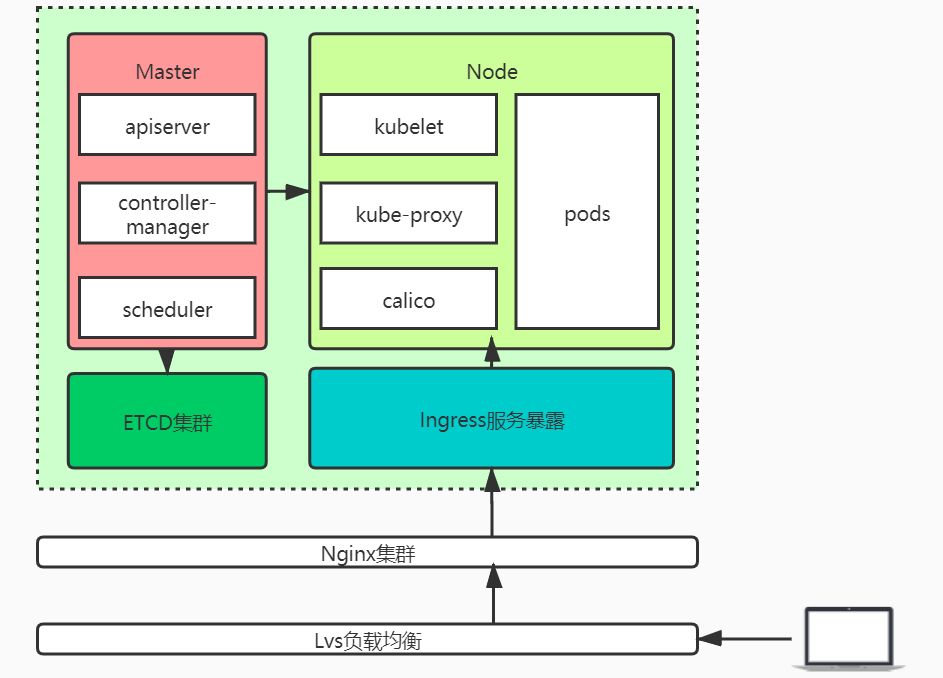
Kubernetes高可用架构图(借用官方架构图https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/):
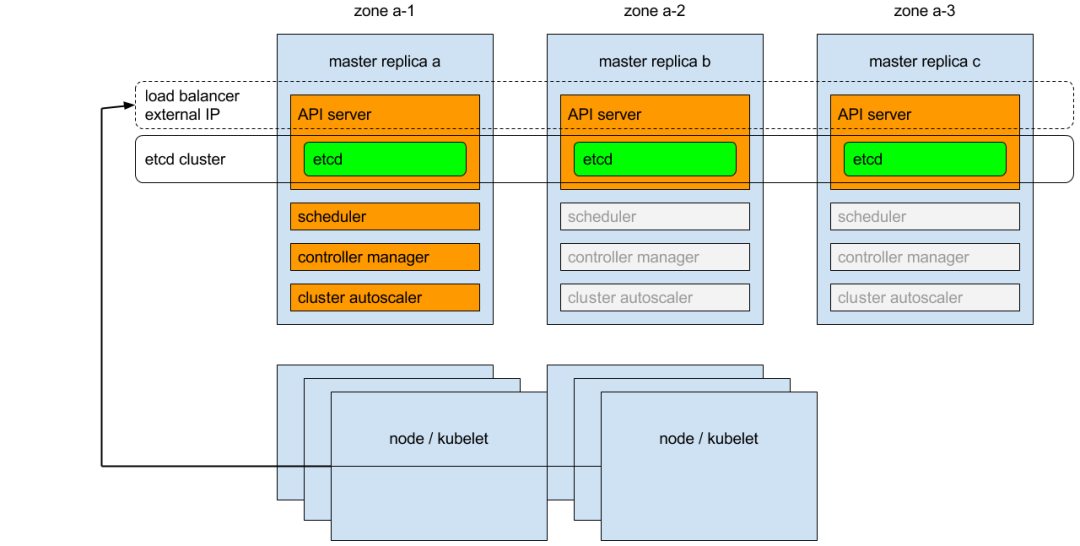
Kubernetes高可用架构说明:etcd做集群模式,对apiserver做负载均衡。Kubelet、kube-proxy的请求,通过负载均衡发送至apiserver。
整体请求流程图:

应用部署实例
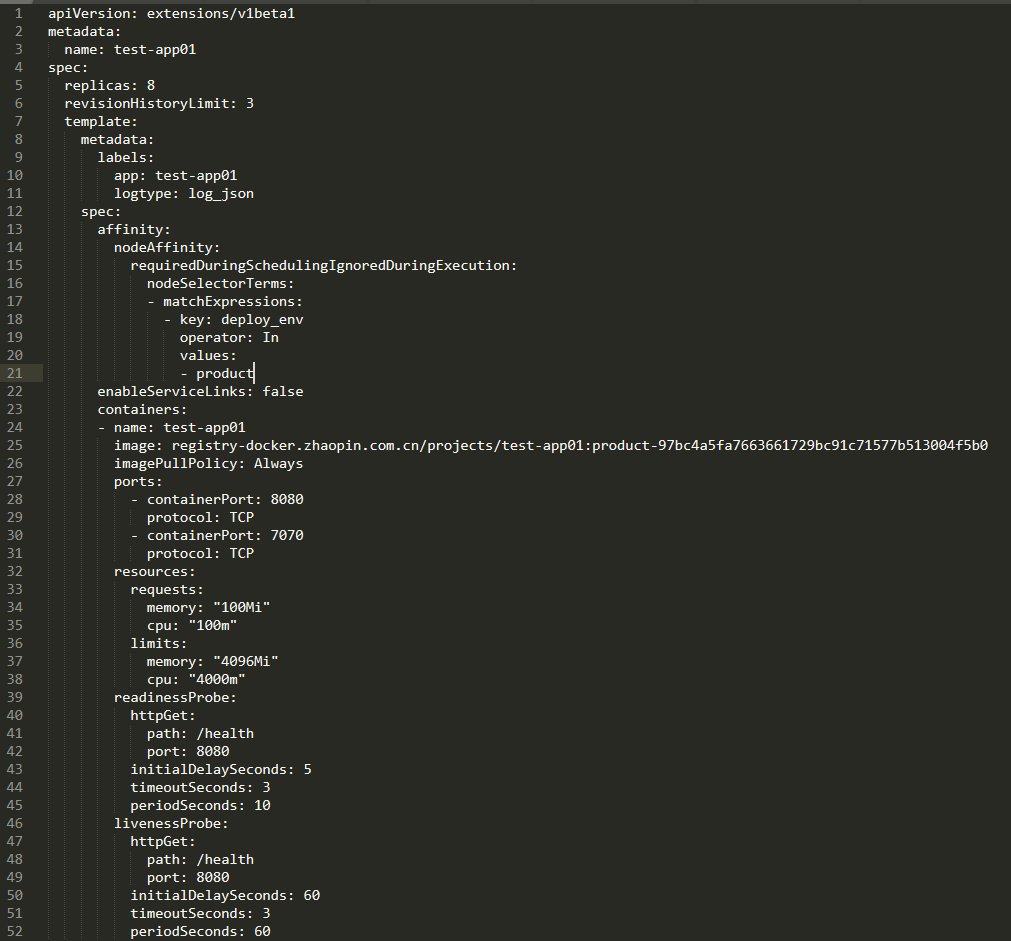
部署一个Java应用至Kubernetes集群:
创建deployment示例yaml文件。
创建service yaml示例。7070端口主要是为了获取JVM相关的Prometheus数据。
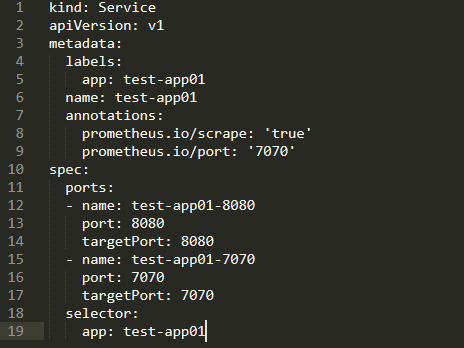
服务暴露实例
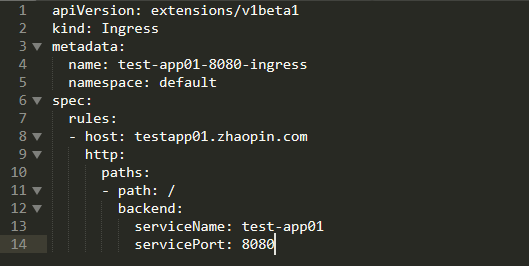
使用Ingress暴露test-app01服务至集群外部并提供域名访问(testapp01.zhaopin.com)。
日志收集
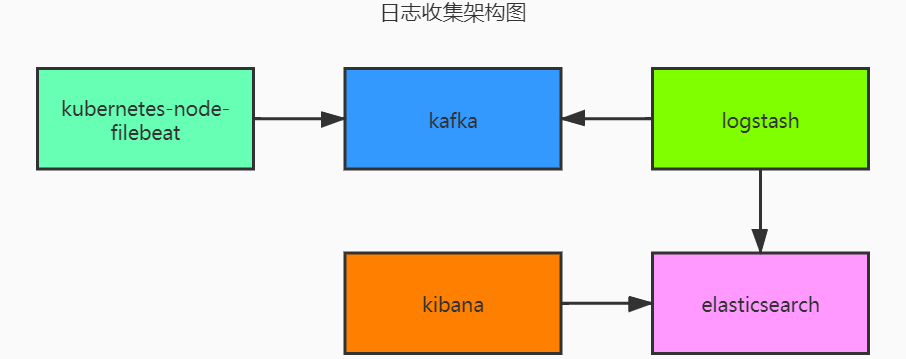
容器日志收集使用DeamonSet的方式部署至Kubernetes集群里的每个Node节点。将容器日志发送至Kafka。Logstash启动消费Kafka进程并格式化输出至Elasticsearch。参考下面架构图。
收集逻辑:
Filebeat将不同的应用基于项目名+环境的方式输出至Kafka的对应topic内,Logstash分组消费,将不同格式的日志做对应的处理。日志格式的定义我们在部署应用的yaml文件内增加了一个label log_type。处理完成后按项目名+环境+日期的格式存入Elasticsearch内供Kibana做查询展示。
监控
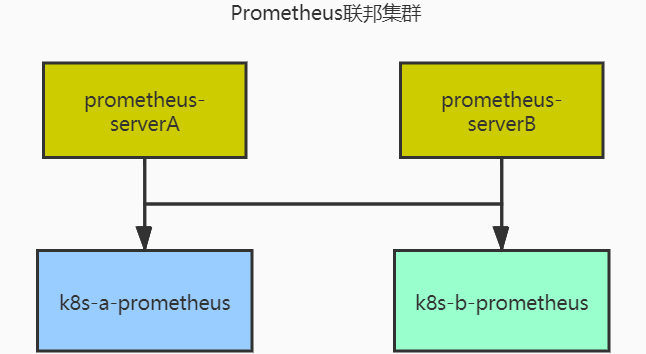
因为我们这边生产有多组集群,所以采用Prometheus的联邦集群收集Kubernetes节点以及应用容器的一些指标,比如JVM/Tomcat等等。并采用多组prometheus-server拉取这些指标,保证监控的可用性。
监控逻辑:
Kubernetes各集群内部署单独的Prometheus收集对应指标(etcd/Master/Node/Service/Pod/Ingress/apiserver等)
Prometheus-server联邦集群收集Metric并做TSDB的存储
Promethes-alertmanager通过Webhook的方式发送报警
Grafana配置Prometheus数据源并做对应的指标展示
踩坑分享
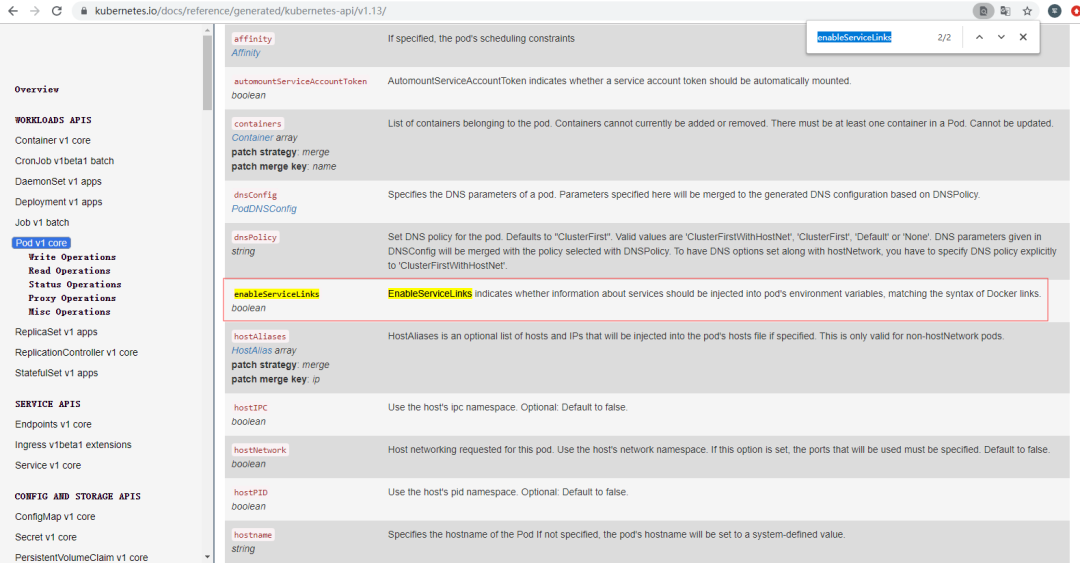
生产环境Node项目启动异常排查
报错日志:Trace: { [Error: spawn E2BIG] code: 'E2BIG', errno: 'E2BIG', syscall: 'spawn' }
经过搜索得知,是由于容器启动后系统变量过多导致的问题(Kubernetes环境服务数量过多会产生这个问题,因为容器在启动时,Kubernetes会加载服务变量至实例)
解决方式:1.13版本之后增加了开关EnableServiceLinks。相关文档链接https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.13.md#downloads-for-v1130。
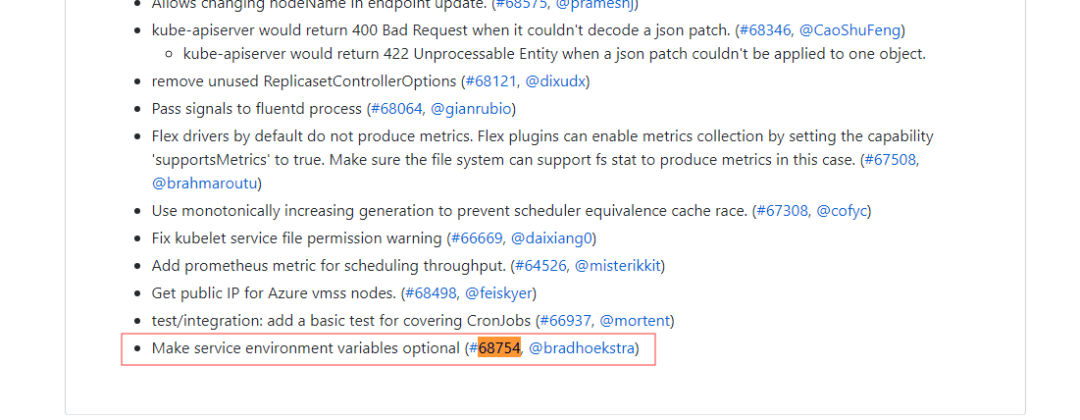
Kubernetes集群节点容器分配不均衡问题排查
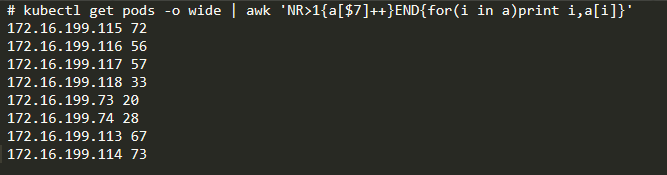
当前问题描述:
通过kubectl获取Pod的分布情况,发现172.16.199.73和172.16.199.74节点分配的Pod资源较少。但是新的Pod也不会主动分配至这两个节点。
现象:
排查思路:
查看当前172.16.199.73和172.16.199.74的节点资源使用情况,和172.16.199.115的对比。
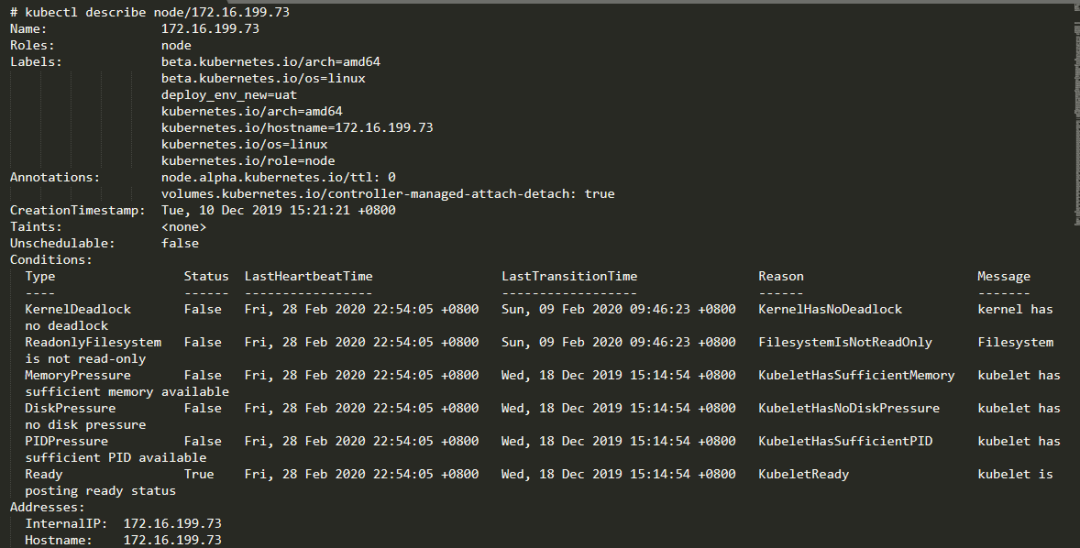
初步怀疑是由于当前requests CPU资源导致(172.16.199.73 38%, 172.16.199.115 16%)但是没有证据。
将kube-scheduler的日志级别调整为10。
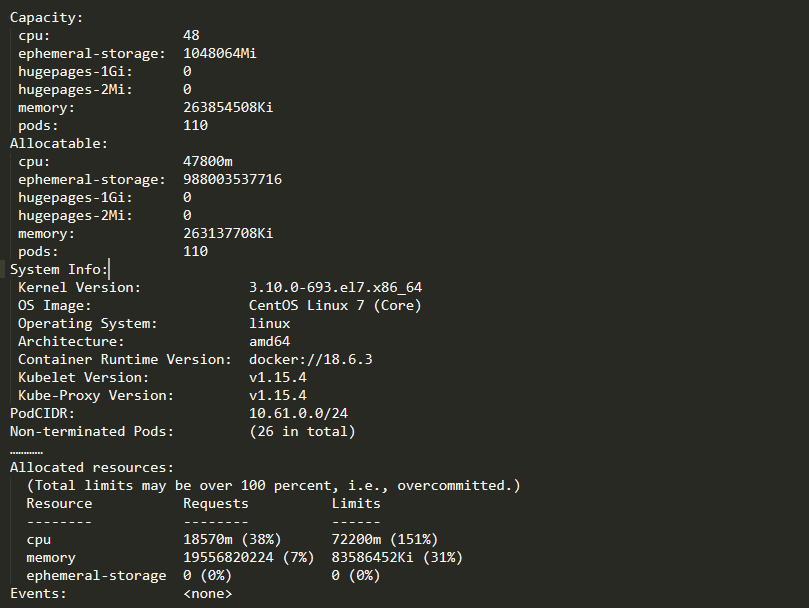
查看kube-scheduler日志:发现172.16.199.73和172.16.199.74的评分都很低为6(BalancedResourceAllocation这一项策略的评分较低),其他节点均高于这两个节点。
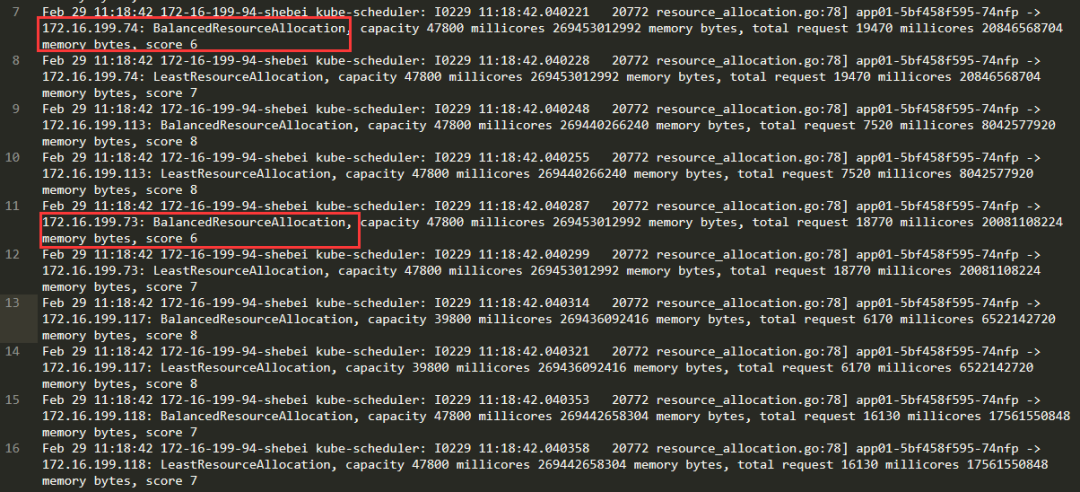
开发同学帮忙分析了一下源码。
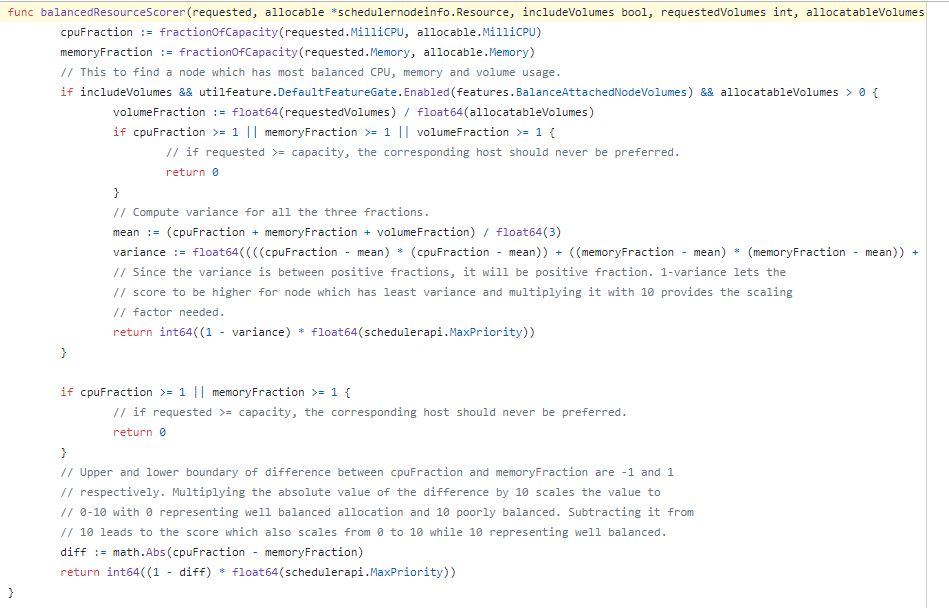
BalancedResourceAllocation评分的计算方式:
(1 - |(( 7670/47800 ) - (8095006720/269473853440))|)*10 = 8.6957979408882655071065000308418 #### 100.115 去除小数后 score为8(1 - |(( 18770/47800 ) - (20081108224/269453012992))|)*10 = 6.8184763010001194498089721709342 #### 100.73 去除小数后 score为6
这个指标是评估CPU和内存使用比率是否均衡,比如CPU使用70%,内存使用70%,评分是10;CPU使用10%,内存使用60%,对应评分是5。
解决问题:
查看172.16.199.73和 172.16.199.73上的requests CPU占用都是固定几个应用带来的,将这几个Pod分散至其他节点,即可提升对应的评分。
经过调整逐步观察发现评分基本一致了。
总结
Kubernetes集群在生产环境运行三年来,集群相对比较稳定,后续也将会陆续引入Istio/Helm等周边成熟开源产品。中间踩了一些坑,在解决这些问题中也成长了不少。
给一些待引入Kubernetes的同学一些建议:
etcd是Kubernetes的大脑,定期备份是救命稻草
集群升级时一定要看官方的发布文档(API版本变化,功能取消都很快)
Q&A
Q:管理存储(PVC/PV)创建容量相关实践是怎么样的?如何进行限制应用部署随便创建超级大的存储?A:目前我们生产环境并未使用PVC/PV。这两种存储方式,仅仅是在验收环境做过一些功能测试。生产环境主要是状态应用。后期可能会使用这两种方式做部署有状态应用的服务。调研过Ceph/GlusterFS,估计会采用Ceph做PVC/PV的应用。
Q:Kubernetes调度策略是怎样的?有没有出现调度不均衡问题?比如有些服务器内存剩余不多了,还频繁调度过去。A:Kubernetes的调度策略是Scheduler这个组件完成的,里面有多种评分方式,根据节点的评分去做Pod的资源调度,这个问题再踩坑分享里有介绍部分,如果感兴趣,可以看看相关的调度算法源码。
Q:请问一下智联内部是怎么做集群升级的?是原地升级还是迁移升级,如何做到对业务的影响最小化?A:升级方式我们采用比较安全的做法。多集群滚动升级,比如生产有两套集群,我们从前端的流量内取出一套集群做完升级后,做流量的平滑切换。
Q:请问一下智联内部有没有做多AZ多活架构,流量分发策略是什么?A:当前使用到的是A/B集群的模式,前端流量做轮询至两套集群,如果要做灰度级别的应用发布,采用cookie的方式,从前端的Nginx做流量的负载。
Q:请问智联内部基于哪些因素来选型容器网络插件的?过程有没有踏过哪些坑? A:我们从最早使用的Flannel网络切换至Calico网络。选型主要是考虑网络的稳定及吞吐量。Calico主要是解决业务系统排查问题,找不到真实容器的IP才做的切换。
Q:想问一下内部API接口请求是直接用的Kubernetes的Service吗?A:内部服务之间,我们采用的是Service的方式调用。因为如果使用域名的方式,相当于流量要再绕一圈。但是部分业务也是需要走域名的方式调用,这个取决于应用自身。
Q:我想问下如何部署几百个服务保证高可用,机器有限情况下?A:想要在机器有限的情况下保证多个服务的高可用可以从以下几个方面考虑。1. 应用自身的消耗,比如CPU/MEM等,基于这个真实的使用做好资源的限制。2. 最少提供2个及以上的副本数保证服务的可用性,利用Kubernetes的探针去做服务高可用。
Q:四套Kubernetes集群是指4套环境,每套环境对应一套Kubernetes集群吗?监控系统几套?是否做了监控系统的高可用,如何做的?A:4套集群,我们这边是根据环境划分的。验收1套,预上线1套,生产2套。监控系统在各自集群都有指标采集器,这个在分享内有架构说明。监控系统的高可用也是采用的Prometheus的多机方式做的。
Q:请问你们Kubernetes集群安装是用什么方式的呢?可不可以分享一下么?A:目前采用的是二进制包的方式安装,利用Ansible去做的。随着kubeadm的稳定,后期可能会采用kubeadm的方式做部署。跟你分享一个比较不错的开源部署解决方案:https://github.com/easzlab/kubeasz。
Q:你们的ES集群配置是多少?高峰期有没有统计过每分钟或者每秒写入日志的量,也就是能承载多少QPS?A:目前我们ES集群共有13个Node,不过配置不太高,因为磁盘不好。如果你们要生产级别使用,建议用SSD的磁盘,这样会好很多。QPS在峰值基本可以到8000-1W。
Q:请问Filebeat怎么在节点收集应用系统日志?A:我们是挂载物理节点的容器日志,使用Filebeat的Kubernetes模块去做的收集,具体可以参考Filebeat的官方Kubernetes部署方案,里面有比较详细的介绍。
Q:你们Node节点内核是3.10版本,是否考虑升级内核版本,来优化性能?A:之前做过升级至CentOS 8的尝试,发现不行。主要是因为防火墙这里的功能升级导致。后面估计会考虑升级系统内核的方式去做一些性能优化。











