
最近react个官方团队推出了最新的 React Server Components 这项技术。 这篇文章将对其相关知识点进行介绍。
那些常见的渲染模式
CSR
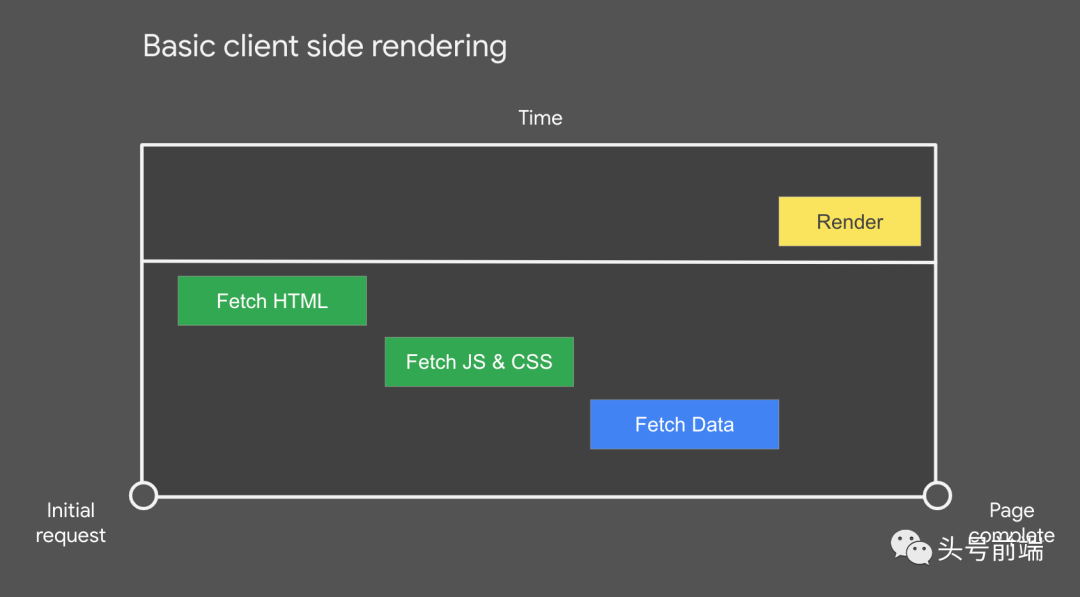
客户端渲染(Client Side Rendering) 应该是前端最熟悉的一种模式了。从前端的发展历程上看,富客户端目前也已经成为现代前端应用的主流架构。从jQuery到React, Vue框架,基本上所有的交互逻辑都在浏览器上得以实现。浏览器会先获取HTML文档、再走完JS、CSS等资源的加载,最后获取数据渲染到页面上,这一整个流程走完在时间上相对来说就比较长。所以,后面衍生出了很多按需加载、预加载等技术来优化前端页面的性能。
静态渲染
静态渲染发生在构建阶段(build time), 通常应用于博客、新闻页等有着大量静态内容的站点。由于不必动态生成页面,可以提前将页面静态渲染好后,部署在多个CDN上,从而加快响应速度。如果你用过Hexo等个人博客生成工具,就应该比较熟悉这种模式。需要提前将页面中所有的URL渲染成对应的HTML,再将这些HTML资源部署到静态服务器上。使用静态渲染的站点由于不需要执行很多的js代码,所以响应速度十分迅速,对于大访问量的博客、新闻等站点十分合适。在React 生态中, Gatsby 在静态渲染这块就完成得很出色。
SSR
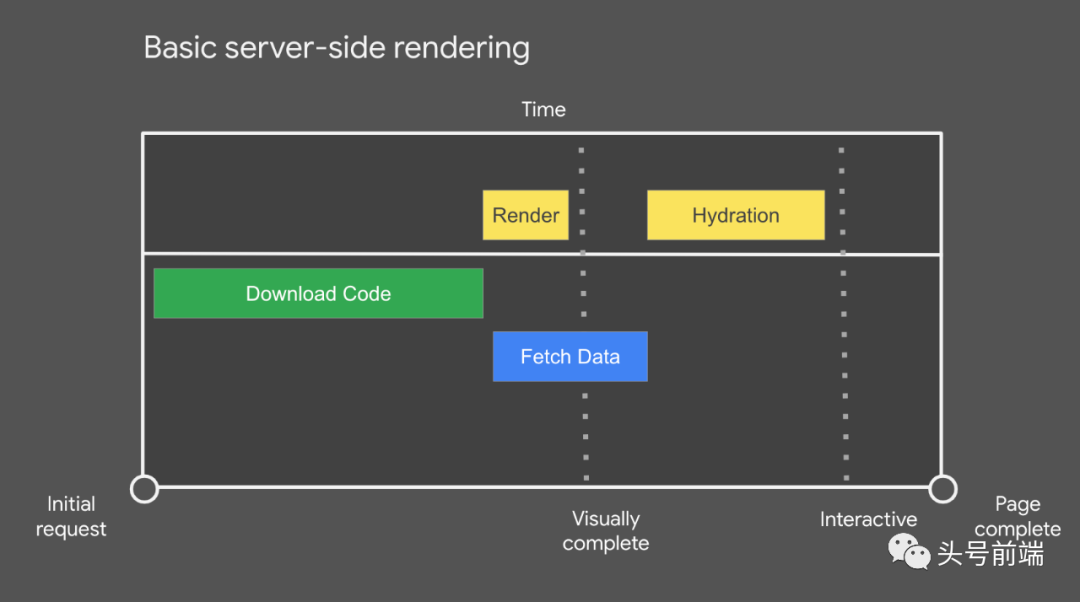
服务端渲染(SSR),也是业界常说的页面直出,通过直接在服务端上将页面渲染成静态HTML,然后分发给客户端从而提高首屏加载速度。但是服务器渲染页面也是需要时间的,虽然能提高TTI(time to interactive), 但也会延长TTFB(Time to First Byte)的时间。通常我们会将SSR和CSR进行结合使用,SSR可以用在landing page等需要首屏快速响应的页面上,而后续的交互应用可以使用CSR。在这个领域,成熟的Next.js成为了很多公司的首选。
预渲染( Prerendering)
采用纯客户端渲染的问题是浏览器需要在本地先进行复杂的运算后,页面才能开始工作。为了解决这个问题,后来又有了预渲染的技术。它同SSR十分类似,也是通过让服务端在构建阶段预先生成静态的HTML、CSS和JS文件,然后在客户端通过注水(hydrated)的方式获得可交互的页面。从技术实现上,可以借助PhantomJS这种无头浏览器来提前渲染好页面。然后让代理服务器将用户请求指向这些预渲染的页面。如果需要应对SEO的需要,也可以借助 https://prerender.io 这种在线服务,可以提前将动态页面保存起来提供给爬虫使用。在服务端使用中间件,一旦检测到是来自爬虫的请求,就让其访问预渲染的页面版本。比起SSR来说,使用客户端预渲染的好处就是不需要借助Node.js服务器,就可以实现较快的首屏渲染速度。但是由于需要提前编译页面,因此页面一旦有更新,就得调用预渲染方法。另外,还需要处理路由信息,来告诉代理服务器哪些路由需要使用预渲染的页面。
流式渲染
在实践过程中,我们通常会将SSR和CSR结合使用,但是纯粹的SSR在首屏渲染性能上还是可能存在缺陷。为了进一步减少TTFB的时间,还可以采用流式渲染的策略,通过将页面分割成小的chunk的形式来发送HTML,浏览器就可以更快时间地接受到响应,并逐块开始渲染。在React中, 可以借助 renderToNodeStream 这个API来进行处理。
`import { renderToNodeStream } from 'react-dom/server';
import MyApp from './MyApp';
const header = "
const root = "
const footer = "
app.get('/', (req, res) => {
res.write(header);
res.write(root);
const stream = renderToNodeStream(
stream.pipe(res, {end: false});
stream.on('end', () => {
res.write(footer);
res.end()
})
});
`
RSC
什么是React Server Components
这是一个React即将推出的一个新特性,可以让我们只在服务器端就可以渲染组件。在官方提供的 演讲 的开头,Dan为我们介绍了React框架主要试图解决的三个限制,一个是良好的用户体验,第二个是极低的维护成本,第三个是更好的性能。这三个约束在以往的实践过程当中,我们通常都只能被迫选择其中的两个。所以为了同时得到这三个好处,React Server Components这项技术就应运而生了。那么它要怎么在这三大方面发力呢? 从用户体验上来看,服务器组件同之前介绍的使用SSR不同的是,每次需要更新的时候,浏览器都会请求服务器,然后服务器会将更新后的组件以流(Stream)的形式下发给浏览器,从而可以获得渐进式渲染的能力。同时由于下发的是已经渲染好的中间状态的数据格式,也不会丢失客户端组件的状态。从迁移成本上来说,你可以将原有的应用以部分或者全部的形式无缝切换到服务器组件上,而无需大量重写原有的代码。最后一方面就是性能了,也是它的主打卖点。利用服务器组件可以极大地减少最终应用打包后的体积。开发过程中,我们常常需要引入第三方库,而这些第三方库都会无形中增加最终打包代码的体积。而通过服务器组件,这些第三方库的代码并不会包含在最终的bundle.js文件中。浏览器也不会下载任何服务器组件的js代码,这也包括了它们的依赖性。这样对于那些在服务器当中使用大量依赖项的组件来说,这是一个特别好的策略。因为这代表着服务器下发给客户端的,仅仅只是经过渲染后的元数据。浏览器拿到这些元数据,直接渲染到页面上就可以了。由于打包体积的减小,顺其自然的,应用的性能势必会得到提升。同时,服务器组件还可以让我们直接访问服务器的资源,这也比直接通过C/S模式来访问资源有着更好的性能。
工作原理
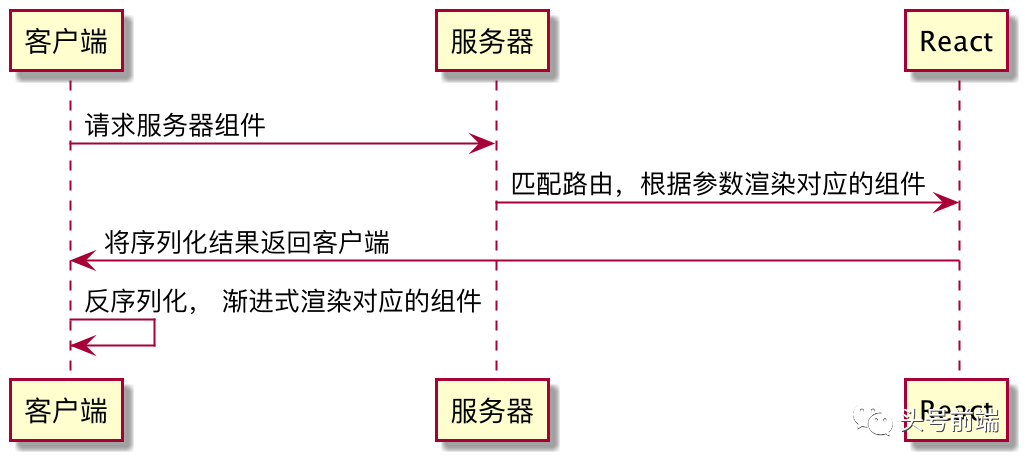
RSC的工作流程,本质上和传统的C/S模式是比较类似的,都是客户端发起请求,然后服务器匹配路由,并根据对应的参数(在这里指RSC的Props)来渲染对应的组件。服务器会将渲染后的组件以元数据的形式下发到客户端中去。以官方提供的例子为例,最终服务器下发的数据就是以序列化后的JSON形式存在(该协议在后续官方可能会进行修改)。
M1:{"id":"./src/SearchField.client.js","chunks":["client5"],"name":""} S3:"react.suspense" J0:["$","div",null,{"className":"main","children":[["$","section",null,{"className":"col sidebar","children": [...]}}]]
其中,J开头的指代Server组件实体,就是在Server执行React.createElement(Server组件)的JSON序列化结果。而M开头的组件则代表了客户端组件,其中的数据是webpack打包后的引用路径,客户端拿到这些引用信息后直接可以拿到对应的客户端模块,接着直接在本地渲染即可。而S表示Suspense组件,用来处理应用的过渡状态,可以理解为程序中的占位符。E是Error组件,处理错误。浏览器拿到这些序列化后的数据后,就可以开始渲染对应的组件了。React框架层在后续客户端更新渲染过程(reconciliation)中,也可以选择直接跳过服务器组件,从而大大提高性能。
接着,在后续应用更新过程中,浏览器需要触发服务器组件更新的时候,会重新构造请求,获取对应的序列化结果,而这些序列化结果会同现有的UI树进行合并渲染,从而触发更新。同时,旧的浏览器状态也不会丢失。

日常使用
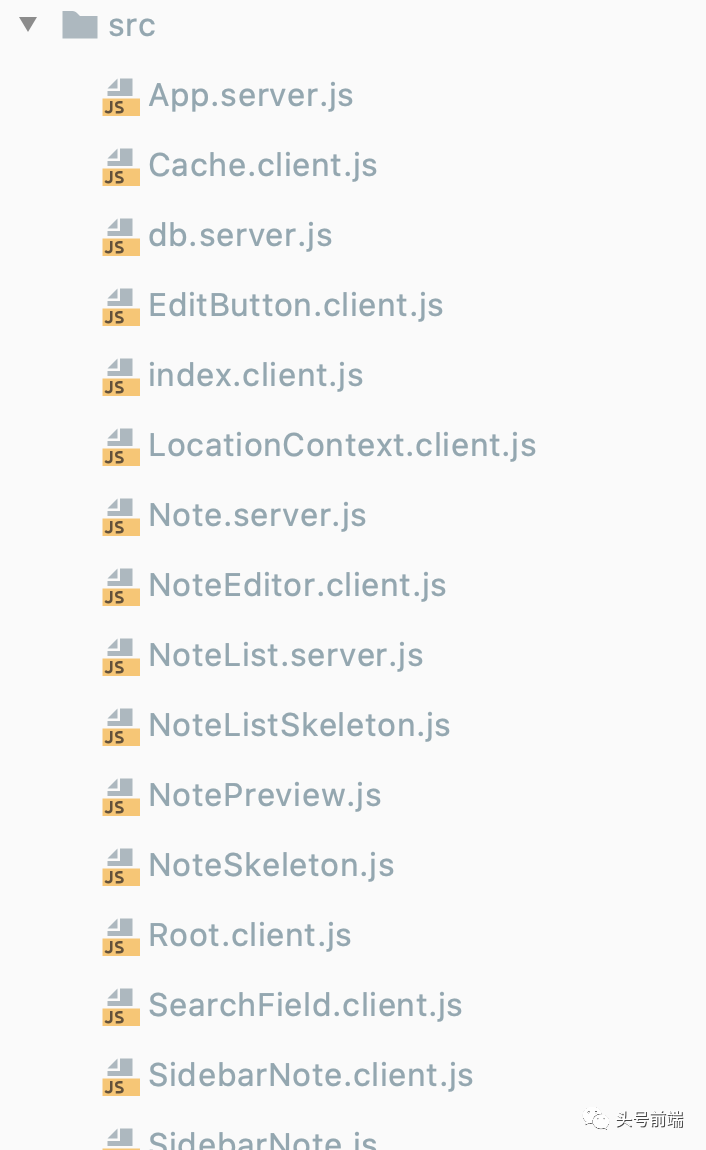
根据官方提供的Demo, 目前客户端组件和服务端组件主要是通过命名规范来区分(client.js代表客户端组件,server.js代表服务器组件),借助Webpack打包工具来完成客户端组件代码的打包。然后借助Node.js服务器,来渲染服务器组件。而对于很多只用来处理转换数据的组件来说,并不需要额外的状态或者说副作用。那么这些组件无论是在客户端还是服务端运行,本质是一样的,于是我们就可以将它们提取为共享组件(Shared Components)。并且这些共享组件可以根据引用它的位置来决定自身角色。如果是在服务端组件中被引用,那么它的行为就跟服务端组件一致,如果是在客户端组件当中被引用,那么它的行为就与客户端组件保持一致。
服务端方面,需要额外提供一个api, 用来下发渲染后的组件元数据:

主要源码解析
=========
服务端
Node.js服务端这边主要是需要提供一个/react接口,客户端获取对应的服务器组件的时候,利用这个接口来获取对应的元数据信息:
`app.get('/react', function(req, res) {
sendResponse(req, res, null);
});
// 处理参数、并根据参数来渲染对应的组件
function sendResponse(req, res, redirectToId) {
// 参数处理
const location = JSON.parse(req.query.location);
if (redirectToId) {
location.selectedId = redirectToId;
}
// 该值后续会用来做缓存的key
res.set('X-Location', JSON.stringify(location));
// 渲染react组件,并发送回浏览器
renderReactTree(res, {
selectedId: location.selectedId,
isEditing: location.isEditing,
searchText: location.searchText,
});
}
async function renderReactTree(res, props) {
// 获取客户端webpack打包模块信息
await waitForWebpack();
const manifest = readFileSync(
path.resolve(__dirname, '../build/react-client-manifest.json'),
'utf8'
);
const moduleMap = JSON.parse(manifest);
pipeToNodeWritable(React.createElement(ReactApp, props), res, moduleMap);
}
`
服务器在处理的时候,会附带上客户端webpack打包模块的信息,主要是因为服务器组件的子组件中可能也会包含客户端组件,此时就需要客户端模块信息来构造返回值。pipeToNodeWritable这个方法是服务器组件逻辑处理的入口函数:
function pipeToNodeWritable(model, destination, webpackMap) { // 参数为根元素,response, 客户端webpack模块信息 var request = createRequest(model, destination, webpackMap); // 绑定'drain'回调, 此处用于做限流处理 destination.on('drain', createDrainHandler(destination, request)); // 开始调度 startWork(request); }
首先会先生成request对象用来后续做处理:
function createRequest(model, destination, bundlerConfig) { // 创建基础的request对象,会从根节点开始解析 // pingedSegments数组用来存储需要处理的节点 var pingedSegments = []; var request = { destination: destination, bundlerConfig: bundlerConfig, cache: new Map(), nextChunkId: 0, pendingChunks: 0, pingedSegments: pingedSegments, completedModuleChunks: [], completedJSONChunks: [], completedErrorChunks: [], writtenSymbols: new Map(), writtenModules: new Map(), flowing: false, toJSON: function (key, value) { // 序列化方法,后面会介绍 return resolveModelToJSON(request, this, key, value); } }; request.pendingChunks++; var rootSegment = createSegment(request, function () { return model; }); pingedSegments.push(rootSegment); return request; }
核心原理是处理每一个子组件,然后利用scheduleWork方法来调度运行。
`// 每个组件在处理过程中会被当做是一个segment
function createSegment(request, query) {
var id = request.nextChunkId++;
var segment = {
id: id,
query: query,
ping: function () {
return pingSegment(request, segment);
}
};
return segment;
}
function pingSegment(request, segment) {
var pingedSegments = request.pingedSegments;
pingedSegments.push(segment);
if (pingedSegments.length === 1) {
scheduleWork(function () {
return performWork(request);
});
}
}
function performWork(request) {
var prevDispatcher = ReactCurrentDispatcher.current;
var prevCache = currentCache;
ReactCurrentDispatcher.current = Dispatcher;
currentCache = request.cache;
var pingedSegments = request.pingedSegments;
request.pingedSegments = [];
for (var i = 0; i < pingedSegments.length; i++) {
var segment = pingedSegments[i];
retrySegment(request, segment);
}
if (request.flowing) {
flushCompletedChunks(request);
}
ReactCurrentDispatcher.current = prevDispatcher;
currentCache = prevCache;
}
`
在调度过程中,进行节点解析。此时可以看到,会根据React DOM树上的节点信息来判断组件类型,并生成对应的元数据,最终返回给浏览器。
`function retrySegment(request, segment) {
// 开始解析组件
var query = segment.query;
var value;
try {
value = query();
while (typeof value === 'object' && value !== null && value.$$typeof === REACT_ELEMENT_TYPE) {
var element = value;
segment.query = function () {
return value;
};
// 根据组件类型尝试渲染
// 返回的数据结构类似于: [REACT_ELEMENT_TYPE, type, key, props]
value = attemptResolveElement(element.type, element.key, element.ref, element.props);
}
// 最后将处理完后的json中间数据结构保存起来,最后会返回给浏览器
var processedChunk = processModelChunk(request, segment.id, value);
request.completedJSONChunks.push(processedChunk);
} catch (x) {
if (typeof x === 'object' && x !== null && typeof x.then === 'function') {
// 先暂时挂起,后续再尝试重新渲染
var ping = segment.ping;
x.then(ping, ping);
return;
} else {
// 发送序列化过的错误组件chunk
emitErrorChunk(request, segment.id, x);
}
}
}
function attemptResolveElement(type, key, ref, props) {
// ...
// 构造最终返回的数据结构
if (typeof type === 'function') {
// This is a server-side component.
return type(props);
} else if (typeof type === 'string') {
// 原生节点,如html, div等
return [REACT_ELEMENT_TYPE, type, key, props];
} else if (typeof type === 'symbol') {
if (type === REACT_FRAGMENT_TYPE) {
return props.children;
}
return [REACT_ELEMENT_TYPE, type, key, props];
} else if (type != null && typeof type === 'object') {
// 客户端组件,type中会记录对应的文件路径等信息
if (isModuleReference(type)) {
return [REACT_ELEMENT_TYPE, type, key, props];
}
switch (type.$$typeof) {
case REACT_FORWARD_REF_TYPE:
{
var render = type.render;
return render(props, undefined);
}
case REACT_MEMO_TYPE:
{
return attemptResolveElement(type.type, key, ref, props);
}
}
}
`
function processModelChunk(request, id, model) { // 序列化服务器组件的model chunk var json = stringify(model, request.toJSON); var row = serializeRowHeader('J', id) + json + '\n'; return convertStringToBuffer(row); } function processModuleChunk(request, id, moduleMetaData) { // 序列化客户端组件的chunk var json = stringify(moduleMetaData); var row = serializeRowHeader('M', id) + json + '\n'; return convertStringToBuffer(row); }
来看一下具体的序列化过程:
`function resolveModelToJSON(request, parent, key, value) {
//....
// 服务器组件
switch (value) {
case REACT_ELEMENT_TYPE:
return '$';
}
while (typeof value === 'object' && value !== null && value.$$typeof === REACT_ELEMENT_TYPE) {
var element = value;
try {
// 尝试直接渲染服务器组件,递归处理
value = attemptResolveElement(element.type, element.key, element.ref, element.props);
} catch (x) {
if (typeof x === 'object' && x !== null && typeof x.then === 'function') {
// 挂起处理,后续再渲染
request.pendingChunks++;
var newSegment = createSegment(request, function () {
return value;
});
var ping = newSegment.ping;
x.then(ping, ping);
return serializeByRefID(newSegment.id);
} else {
request.pendingChunks++;
var errorId = request.nextChunkId++;
emitErrorChunk(request, errorId, x);
return serializeByRefID(errorId);
}
}
}
if (value === null) {
return null;
}
if (typeof value === 'object') {
if (isModuleReference(value)) {
// 客户端组件
var moduleReference = value;
var moduleKey = getModuleKey(moduleReference);
var writtenModules = request.writtenModules;
var existingId = writtenModules.get(moduleKey);
if (existingId !== undefined) {
if (parent[0] === REACT_ELEMENT_TYPE && key === '1') {
return serializeByRefID(existingId);
}
return serializeByValueID(existingId);
}
try {
// 直接从webpack的文件中获取对应的元数据信息
var moduleMetaData = resolveModuleMetaData(request.bundlerConfig, moduleReference);
request.pendingChunks++;
var moduleId = request.nextChunkId++;
emitModuleChunk(request, moduleId, moduleMetaData);
writtenModules.set(moduleKey, moduleId);
if (parent[0] === REACT_ELEMENT_TYPE && key === '1') {
return serializeByRefID(moduleId);
}
return serializeByValueID(moduleId);
} catch (x) {
request.pendingChunks++;
var _errorId = request.nextChunkId++;
emitErrorChunk(request, _errorId, x);
return serializeByValueID(_errorId);
}
}
}
// 其他组件类型
if (typeof value === 'string') {
return escapeStringValue(value);
}
if (typeof value === 'boolean' || typeof value === 'number' || typeof value === 'undefined') {
return value;
}
//...
if (typeof value === 'symbol') {
var writtenSymbols = request.writtenSymbols;
var _existingId = writtenSymbols.get(value);
if (_existingId !== undefined) {
return serializeByValueID(_existingId);
}
var name = value.description;
}
`
做序列化,生成最终要返回给浏览器的JSON元数据:
流式渲染的处理逻辑
在阅读源码的过程中,可以注意到,RSC使用了流式渲染的处理逻辑。此处,主要将组件数据以chunk的形式下发给浏览器,从而提高页面性能:
`function pipeToNodeWritable(model, destination, webpackMap) {
// 携带了节点信息,response, 客户端webpack模块信息
var request = createRequest(model, destination, webpackMap);
// 绑定'drain'回调, 此处用于做限流处理
destination.on('drain', createDrainHandler(destination, request));
// 开始调度
startWork(request);
}
// 大数据量的时候,当写入数据超出缓存区阈值时,会用到drain事件,
// drain的回调用来继续将数据返回给客户端
function createDrainHandler(destination, request) {
return function () {
return startFlowing(request);
};
}
function startFlowing(request) {
request.flowing = true;
// 将处理完成的chunk分发到客户端
flushCompletedChunks(request);
}
// 用一个flag来标志该函数是否已经在调用过程中了
var reentrant = false;
function flushCompletedChunks(request) {
// 如果已经在处理中的话就返回
if (reentrant) {
return;
}
reentrant = true;
var destination = request.destination;
beginWriting(destination);
try {
// 先处理客户端组件的chunk,这样可以尽快渲染
var moduleChunks = request.completedModuleChunks;
var i = 0;
// 模块分发出去
for (; i < moduleChunks.length; i++) {
request.pendingChunks--;
var chunk = moduleChunks[i];
// 数据返回
if (!writeChunk(destination, chunk)) {
request.flowing = false;
i++;
break;
}
}
// 将已处理的模块清掉
moduleChunks.splice(0, i);
// 处理服务端组件的chunk
var jsonChunks = request.completedJSONChunks;
i = 0;
for (; i < jsonChunks.length; i++) {
request.pendingChunks--;
var _chunk = jsonChunks[i];
if (!writeChunk(destination, _chunk)) {
request.flowing = false;
i++;
break;
}
}
jsonChunks.splice(0, i);
// 最后再处理错误的chunk
var errorChunks = request.completedErrorChunks;
i = 0;
for (; i < errorChunks.length; i++) {
request.pendingChunks--;
var _chunk2 = errorChunks[i];
if (!writeChunk(destination, _chunk2)) {
request.flowing = false;
i++;
break;
}
}
errorChunks.splice(0, i);
} finally {
reentrant = false;
completeWriting(destination);
}
flushBuffered(destination);
if (request.pendingChunks === 0) {
// We're done.
close(destination);
}
}
`
至此,服务端的大概处理逻辑就走完了。

接下来我们来看一下客户端的处理逻辑:
客户端逻辑
客户端在获取响应后,会开始反序列化,从根节点开始一个个进行处理返回的chunk,并渲染对应的组件:
function createResponse() { var chunks = new Map(); var response = { _chunks: chunks, readRoot: readRoot }; return response; }
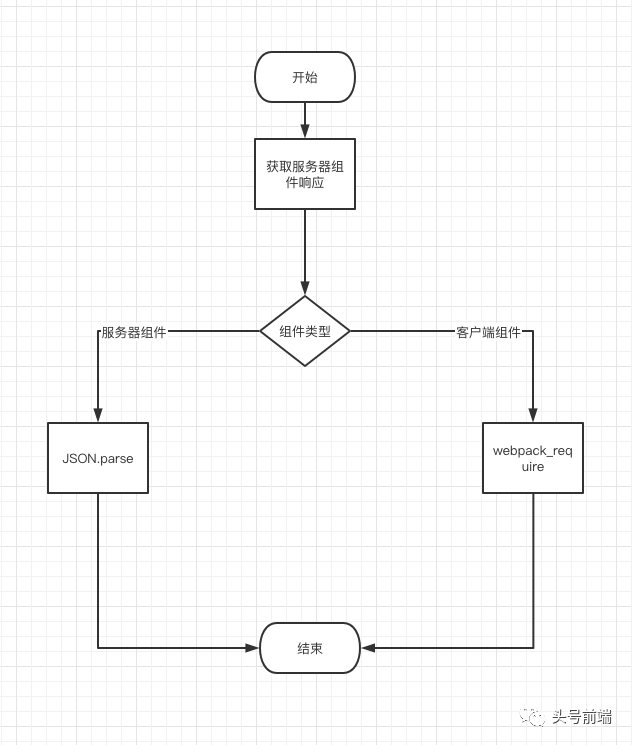
chunk在反序列化过程中,主要也是分为服务端组件和客户端组件。对于服务器组件来说,由于之前返回的数据已经是经过渲染过的JSON元数据,直接进行JSON.parse反序列化就可以了。
// 初始化服务端组件 function initializeModelChunk(chunk) { // 由于value是已经渲染好的中间状态数据,直接反序列化 // 如: ["$","div",null,{"className":"main","children":[["$","section",null,{"className":"col sidebar","children": [...]}}]] var value = parseModel(chunk._response, chunk._value); var initializedChunk = chunk; initializedChunk._status = INITIALIZED; initializedChunk._value = value; return value; }
而对于客户端组件,由于返回的是webpack中相对地址信息,则直接调用webpack中的`webpack_require去获取:
function initializeModuleChunk(chunk) { // 直接通过webpack获取客户端组件 var value = requireModule(chunk._value); var initializedChunk = chunk; initializedChunk._status = INITIALIZED; initializedChunk._value = value; return value; }
接下来是一个大概的一个流程图:
总结
优势
交互式富应用与能够快速响应的静态应用之间要如何选择,有时候难以抉择。但是有了RSC后,这两者似乎可以达到一个很好的平衡。目前已经的一些好处有:
打包体积大大减少,极好地提高页面加载性能。
借助RSC,可以消除客户端和服务器之间的边界。比方说常见的CMS应用,你可以选择在服务器上渲染文章,但是本地可以对其进行编辑。真正的让React做到“一统天下“。
在网速较慢的环境下,服务器组件会以suspense的形式下发给客户端,从而客户端能够得到过渡阶段的响应。
如果说之前使用SSR会存在状态丢失的问题,那么使用Server Components就可以完全避免这些问题了。
问题
RSC同SSR不同的是,它并不会将组件渲染成HTML的形式,因此对于SEO来说应该是无能为力的。所以它可能只适用于非首屏页面。
引入RSC后,服务端和客户端开始紧耦合,虽然利用命名规范可以区分服务器组件和客户端组件,但是在编码上容易造成额外的心智负担。
同时,因为服务器组件是无状态的,因此需要去思考新的编程范式和最佳实践。从目前的官方的实现方式上看,由于最终会涉及到JSON序列化,因此RSC必须足够简单,才能在反序列化的过程中不丢失信息。这可能也会限制其能力。
最后由于服务器组件涉及到服务端,调试似乎也会变得困难。
未来可能的实践与应用
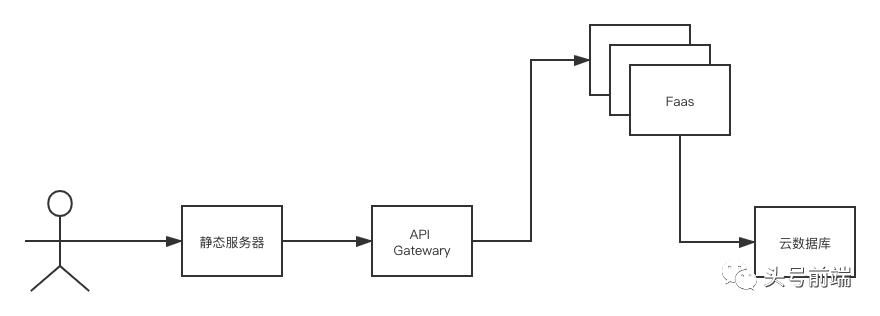
我们先来看一下在现有的前端应用中一个简单的无服务架构是怎么做的。首先,我们会将静态网页部署在云端存储中上,为了提高性能可能还会引入CDN加速等技术, 而这些静态资源在后续访问的API资源会通过网关(API Gateway)的形式访问无服务后端资源(Faas + Node.js),这些后端应用可以直接返回云数据库的数据内容。
那么在有了服务器组件后,我们可以在云端部署动态的服务器组件(可以作为Faas应用存在),以服务的形式提供给前端。
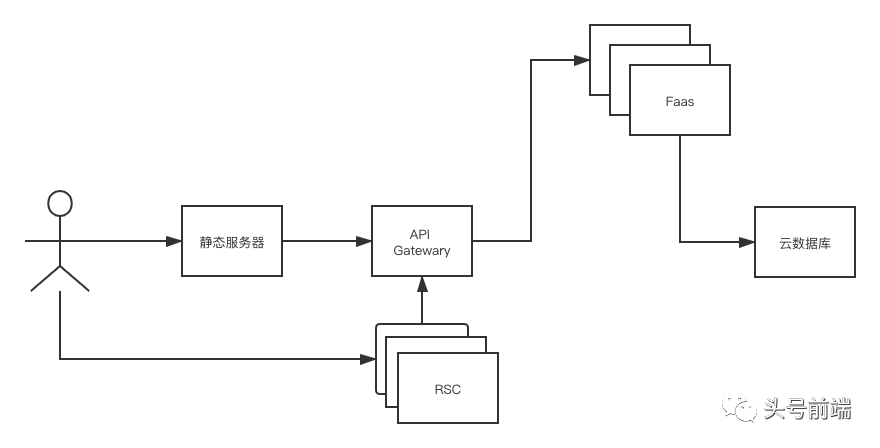
目前已经有人对RSC的Serverless模式进行了实验,感兴趣的可以参考 https://github.com/sw-yx/amplify-react-serverless-components 这个项目。未来更多的可能发展方向:
React Components as a Service:组件即服务
Server React Components Marketplace:组件市场
Server React Components Theme Marketplace:组件主题市场
之后可以借助云端基础设施,应用在可扩展、灾备上也能够得到进一步提升。

参考文档
https://github.com/josephsavona/rfcs/blob/server-components/text/0000-server-components.md
https://github.com/reactjs/server-components-demo
https://reactjs.org/blog/2020/12/21/data-fetching-with-react-server-components.html
https://developers.google.com/web/updates/2019/02/rendering-on-the-web
转载请保留这部分内容,注明出处。
另外,头条号前端团队非常 期待你的加入
公众号:头号前端字节招聘 | 期待你的加入
本文分享自微信公众号 - 程序IT圈(DeveloperIT)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











