
Pod控制器:
ReplicationController:早期K8s只有这一个控制器,但后来发现让这一个来完成所有任务,太复杂.因此被废弃.
ReplicaSet: 它用于帮助用户创建指定数量的Pod副本,并确保Pod副本数量一直满足用户期望的副本数量。
副本数量"多退少补"等机制。【它可认为就是ReplicationController的新版本。】
它由三个主要组件组成:
1. 用户期望的Pod的副本数量.
2. 标签选择器: 使用它来选择自己管理的Pod
3. Pod模板: 若标签选择器选择的副本数量不足,则根据Pod模板来新建.
Deployment: 它用于帮我们管理无状态Pod的最好的控制器.
它支持滚动更新,回滚,它还提供了声明式配置的功能,它允许我们将来根据声明的配置逻辑来定义,
所有定义的资源都可随时进行重新声明,只要该资源定义允许动态更新。
DaemonSet:用于确保集群节点上只运行一个Pod的控制器。它一般用于构建系统级应用时使用。
它不能定义副本数量,副本数量要根据集群的规模来自动创建, 即: 若集群中新加入了一个
node节点,DaemonSet将自动使用Pod模板在新节点上创建一个Pod,并精确保障每个节点上仅
运行一个Pod. 所以此控制器,必须要有Pod模板 和 标签选择器。
它还有另一个作用:就是用于控制Pod仅运行在指定满足条件的节点上,并精确确保其只运行一个Pod.
它所管理的Pod:
1. 必须是守护进程,要持续运行在后台。
2. 它没有终止那一刻,即便不忙,它也监听文件的变动 或 用户对某套接字的请求
Job: 主要用于创建一个完整指定任务的Pod,一旦任务完成,就会退出;但是若任务未完成,则会重新启动,直到任务完成.
Cronjob: 它是定义一个周期性任务,Pod启动后,和Job启动的Pod类似,也是任务执行完成后才会终止重启。
同时它还会自动处理一个任务还未完成,下一个启动时间已经到了的问题。
控制器示例:
ReplicaSet控制器示例:
#若想了解下面每个参数的含义,可查看 kubectl explain replicaset
vim replicaset.yaml
apiVersion: apps/v1 #一般来说,一个清单文件的基本格式:
kind: ReplicaSet #apiVersion,kind,metadata这是必须的,下面对 spec是replicaSet的一个必要参数.
metadata: #要查看spec支持那些参数: kubectl explain replicaset.spec 即可.
name: myapp
namespace: default
spec:
replicas: 2 #这里是定义ReplicaSet的副本数量.
selector:
matchLabels:
app: myapp
release: canary
template: #查看template支持那些参数: kubectl explain replicaset.spec.template即可查看.
metadata:
name: myapp-pod #通常Pod的名称空间必须和控制器的名称空间一致,故可省略.
labels: #这里创建Pod的标签必须和selector的标签符合,否则此Pod将永久被创建下去。
app: myapp
release: canary
spec:
containers:
- name: myapp-container
image: busybox
ports:
- name:http
containerPort: 80
#启动:
kubectl create -f replicaSet.yaml
kubectl get pods
kubectl get rs
kubectl delete pods PodName
kubectl get pods #可以查看控制器控制下的Pod个数少了,会自动被创建.
#接下来测试,控制器控制下的Pod多了会怎么
kubectl label pods PodName release=canary,app=myapp #给Pod添加标签
kubectl get pods --show-labels
注:
此测试也说明: 在定义控制器所管理的Pod时,一定要精确定义Pod的标签,
尽量避免出现,用户创建的Pod标签正好和你定义的控制器符合,产生悲剧!
另外:
service 和 控制器它们没有直接关系,只是它们都使用标签选择器来获取Pod,
这也意味着一个Service可管理多个控制器所创建的Pod.
#控制器的配置是支持动态更新的.
kubectl edit rs replicaset #将其副本数量修改一个再查看效果。
#它还支持动态更新Pod的镜像版本.
kubectl edit rs replicaset
kubectl get rs -o wide
注:
这里查看到Pod镜像版本修改了,但实际上正在运行的Pod的镜像版本并没有改变.
这时若你手动删除一个Pod,新建的Pod将使用新版本创建.
这样就可以轻松实现 金丝雀 发布更新了,即: 先删除一个,让一个Pod使用新版本,使用新版本Pod
会得到一部分流量,这一部分流量就可以作为测试流量,若2天后,没有发现用户抱怨Bug,则可以
手动将Pod一个一个删除,并替换成新版本的Pod。
Deployment:
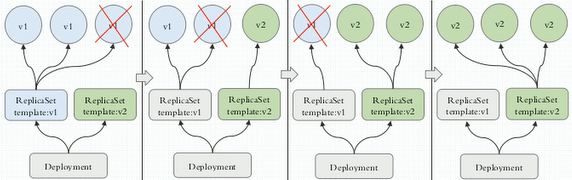
它是ReplicaSet控制器的控制器,即: Deployment控制器它不直接用于管理Pod,它是用来管理
ReplicaSet控制器的,这样做的好处是,可实现动态更新和回滚,如上图所示,它能实现
多种更新方式,上图显示的是 灰度更新 过程,它将ReplicaSetV1控制的Pod,每次一个的
删除,并在ReplicaSetV2上重建,若ReplicaSetV2上线后,有问题,还能快速回滚到V1.
通常来说Deployment不会直接删除ReplicaSet,它会保留10个版本,以便回滚使用。
它通过更新Pod的粒度来实现 灰度更新,金丝雀更新,蓝绿更新。
它控制Pod创建粒度是 比如:
1.在删除时,必须保障有5个Pod,但可临时多一个Pod,则它会创建一个,删除一个. 直到全部替换。
2.必须保障有5个,但可临时少一个Pod,则它会先删除一个,在创建一个,直到全部替换。
3.必须保障有5个,但可多一个,也可少一个,此时它会创建一个,删除两个,再创建2个,再删除2个,直到全部替换。
4.还有一种是允许临时多出一倍,则它会一次性创建5个,然后直接替换使用新的Pod,在把老的Pod删除。
Deployment控制参数:
strategy: #设置更新策略
type <Recreate|RollingUpdate> #指定更新策略类型.Recreate: 它是删除一个,重建一个.
RollingUpdate: 这是滚动更新。
rollingUpdate:
maxSurge: 用于定义滚动更新时,副本最多允许增加几个. 它支持两种值:
5: 表示副本数最多增加5个。
20%: 若你有10个Pod副本, 20%就是最多增加2个副本.
maxUnavailable: 最多允许几个不可用.它也支持整数 或 百分比.
revisionHistoryLimit
paused
vim myapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app:myapp
release: canary
template:
metadata:
labels:
app:myapp
release: canary
spec:
cantainers:
- name: myapp
image: busybox
ports:
- name:http
containerPort: 80
#编写以上清单文件后,就可以执行:
kubectl apply -f deploy-demo.yaml
kubectl get deploy
kubectl get rs
vim deploy-demo.yaml
#修改副本数量为4
kubectl apply -f deploy-demo.yaml #修改后再次apply是运行,apply可应用配置多次,并且它会自动反映出清单的变化.
kubectl describe deploy myapp-deploy #查看Annotaions,RollingUpdateStrategy.
#测试动态滚动更新
vim deploy-demo.yaml
修改镜像的版本为新版本.
终端2:
kubectl get pods -l app=myapp -w
终端1:
kubectl apply -f deploy-demo.yaml
再到终端2上查看滚动更新的效果。
kubectl get rs -o wide #可查看到多了一个rs,而且旧版rs的数据都是0.
kubectl rollout history deployment myapp-deploy #查看滚动更新的历史
#通过给配置文件打补丁的方式来动态更新:
kubectl patch deployment myapp-deploy -p '{"spec":{"replicas":5}}'
注: 这样也可以动态修改 myapp-deploy这个Deployment控制器的参数.
kubectl get pods #可看到Pod个数已经动态创建了。
#动态修改Deployment控制器滚动更新的策略:
kubectl patch deployment myapp-deploy -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":0}}}}'
kubectl describe deploy myapp-deploy #查看更新策略
#修改Deployment控制器下Pod的镜像为新版本,然后实现金丝雀更新.
终端1:
kubectl get pods -l app=myapp -w
终端2:
kubectl set image deployment myapp-deploy myapp=busybox:v3
kubectl rollout pause deployment myapp-deploy
终端3:
kubectl rollout status deployment myapp-deploy
终端2:
kubectl rollout resume deployment myapp-deploy
kubectl get rs -o wide
#回滚到指定版本
kubectl rollout history deployment myapp-deploy
deployment.extensions/myapp-deploy
REVISION CHANGE-CAUSE
0
2
3
4
5
kubectl rollout undo deployment myapp-deploy --to-revision=3
kubectl rollout history deployment myapp-deploy #可以看到第一版成为第四版.
deployment.extensions/myapp-deploy
REVISION CHANGE-CAUSE
0
4
5
6
7
daemonSet控制器:
#查看daemonSet控制器的语法
kubectl explain ds
kubectl explain ds.spec
vim ds-demo.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
namespace: default
spec:
selector:
matchLabels:
app:filebeat
release:stable
template:
metadata:
labels:
app: filebeat
release: stable
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env: #env的用法: kubectl explain pods.spec.containers.env
- name: REDIS_HOST
value: redis.default.svc.cluster.local
- name: REDIS_LOG_LEVEL
value: info
#接着使用apply来应用daemonSet控制器的配置清单创建Pod资源.
kubectl apply -f ds-demo.yaml
#将多个相关的资源定义在一起的方式,这是工作中常用的方式.
vim ds-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: redis
role: logstor
template:
metadata:
labels:
app: redis
role: logstor
spec:
containers:
- name: redis
image: redis:4.0-alpine
ports:
- name: redis
containerPort:6379
--- #这表示分隔符.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
namespace: default
spec:
selector:
matchLabels:
app:filebeat
release:stable
template:
metadata:
labels:
app: filebeat
release: stable
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env:
- name: REDIS_HOST
value: redis.default.svc.cluster.local
#fiebeat通过环境变量找到redis的前端service,注意这里指定的名字是redis的前端服务名,而非随意写!
- name: REDIS_LOG_LEVEL
value: info
#因为此前通过daemonSet创建了两个Pod资源,为了避免冲突,先删除Pod资源.
kubectl delete -f ds-demo.yaml
#接着再同时创建redis和fliebeat两个Pod资源.
kubectl apply -f ds-demo.yaml
#接着为redis创建一个服务,来暴露redis的服务端口,以便filebeat可以将日志发送给服务,服务再将日志转发给redis.
kubectl expose deployment redis --port=6379
kubectl get svc #查看创建的service
#验证redis是否可以收到filebeat的日志.
kubectl get pods #等redis处于running状态就可以登陆查看了.
kubectl exec -it redis-5b5d.... -- /bin/sh
/ data # netstat -tnl
/ data # nslookup redis.default.svc.cluster.local #解析redis的域名.
/ data # redis-cli -h redis.default.svc.cluster.local #验证能否通过域名直接登陆redis
/ data # keys * #登陆redis成功后,查看是否有key被创建.
#登陆filebeat查看状态
kubectl exec -it filebeat-ds-h776m -- /bin/sh
/ # ps uax
/ # cat /etc/filebeat/filebeat.yml #查看其配置文件中redis的定义.
/ # printenv #查看环境变量.
/ # kill -1 1 #使用-1信号 让filebeat重读配置文件,这会导致Pod重启,不过没事.
#另外,通过-o wide 可以看到daemonSet定义的Pod一定是一个节点上运行一个Pod.
kubectl get pods -l app=filebeat -o wide #daemonSet定义的Pod不运行在主节点上,
#主要是因为前面部署时,定义了Master节点是不调度的.
#测试时,发现以下问题:
# kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.111.80 Ready node 2d21h v1.13.5
192.168.111.81 Ready node 2d21h v1.13.5
192.168.111.84 Ready,SchedulingDisabled master 2d21h v1.13.5 #主节点配置了,不调度,即污点.
192.168.111.85 NotReady,SchedulingDisabled master 2d21h v1.13.5
# kubectl get pod -l app=filebeat -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
filebeat-ds-8gfdr 1/1 Running 0 13m 10.10.171.2 192.168.111.81
filebeat-ds-ml2bk 1/1 Running 1 13m 10.10.240.193 192.168.111.84
filebeat-ds-zfx57 1/1 Running 0 13m 10.10.97.58 192.168.111.80
#从运行状态上看, 符合DaemonSet的特性,每个节点都运行一个. 但为啥它能运行在Master上,原因不明?
#daemonSet也是支持滚动更新的,怎么更新?
kubectl explain ds.spec.updatestrategy.rollingUpdate #它只支持先删一个在创建一个, 因为一个节点只能运行一个Pod.
#定义daemonSet控制器filebeat-ds 滚动更新其下管理的Pod的image 升级到filebeat:5.6.6-alpine
kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine
#查看Pod的更新过程
kubectl get pods -w
DaemonSet的更新策略:
updateStrategy:
type <RollingUpdate |OnDelete> #OnDelete: 即删除时创建。
#动态更新DaemonSet:
kubectl get ds
kubectl set image daemonSets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpine
终端2:
kubectl get pods -w
#让pod和宿主机的共享名称空间:
Pods:
hostNetwork
hostPID
hostIPC












