
【摘要】根据业界知名分析机构的调查发现,在机器学习日常开发工作中,数据预处理和特征工程(涉及数据的分析和处理)约占工作量的60%以上,对于机器学习来说至关重要。
数据分析和处理的问题与挑战
近年来,越来越多的企业使用机器学习技术进行智能化的决策支持。机器学习通过使用算法来识别数据中的模式,并使用这些模式创建一个可以进行预测的数据模型,这个流程通常包含数据预处理,特征工程,算法开发,模型评估等多个环节。根据业界知名分析机构的调查发现,在机器学习日常开发工作中,数据预处理和特征工程(涉及数据的分析和处理)约占工作量的60%以上,对于机器学习来说至关重要。
1.1质量参差不齐的数据
数据质量是数据管理中的一个非常重要的问题,因为脏数据通常会导致不精确的数据分析,从而引发不正确的业务决策。脏数据通常来源于数据录入过程中的人工错误或系统信息变化数据未及时更新的一些过期数据。多项调查显示脏数据是数据科学家普遍面临的障碍,毫无疑问,提供有效的数据清洗解决方案十分具有挑战,往往需要较深的理论知识和工程经验。
1.2 数据的可视化探索分析
相比于原始的数据,数据的可视化的图表可以更好的提供解释和理解。数据的可视化不仅可以提供快速清晰的信息理解,还可以用于识别数据变化的趋势及数据资产之间的关系和模式。虽然数据可视化十分有用,手工构建图表往往十分耗时和繁琐。
1.3 多样化的特征工程
特征工程是将原始数据转换成特征的数据处理过程,其目的是为了更好的表征数据和模型,提升模型预测和评估的精度。转换形成的特征好坏与数据/模型密切相关,由于数据和模型的多样性,因此很难提取出通用的特征工程技术,适用于所有的项目。数据科学家往往需要结合应用领域及数据的特点,反复不断的迭代开发,验证,形成特定于具体数据和模型的特征工程。
1.4 容纳大规模的数据分析处理平台
随着数据规模的不断扩大,现有的数据分析和处理能力受限于单机的内存容量,很难进行伸缩。如何将开发探索阶段的小样本数据分析和处理能力伸缩到产品化场景下的大数据样本,是越来越多企业面临的巨大的挑战。
NAIE交互式特征工程介绍
为了应对数据分析和处理的挑战,华为NAIE产品基于开源jupyterlab项目,沉淀内部多年的数据分析和处理经验,打造了NAIE交互式特征工程。NAIE交互式特征工程旨在降低数据分析处理的门槛,提升数据分析处理的效率。
2.1 零编码的数据可视化探索
数据探索部分主要包含数据的描述性统计分析,数据的可视化图表分析,数据的特征关系分析三大部分。
通过数据的描述性统计分析可以进行数据的基础统计量分析,数据的空值和无效值的分布分析,原始数据的表格预览。
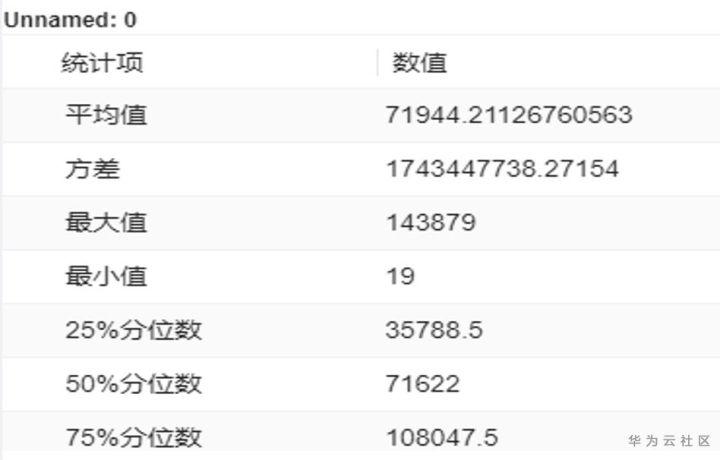
基础统计量分析
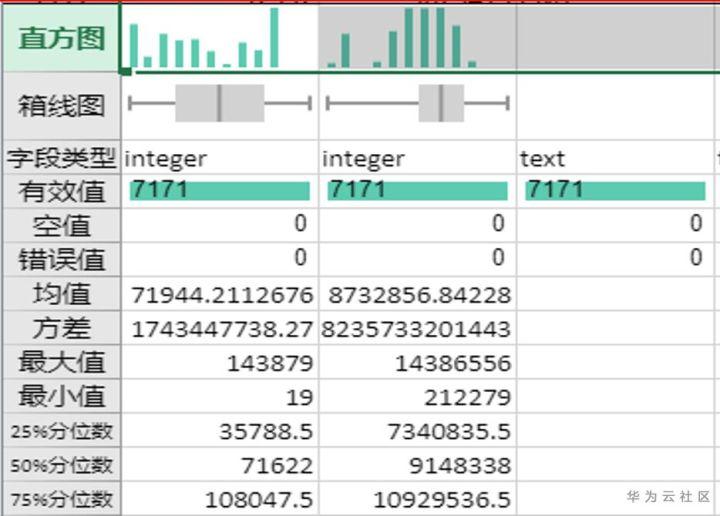
数据空值无效值分布分析
原始数据在线表格预览
通过数据的可视化图表分析可以根据数据一键式生成散点图,折线图,直方图,箱线图等多种图表,通过图表直观辅助分析。

可视化图表分析
通过数据的特征关系分析可以使用卡方检测,F检验,信息增益,递归消除特征等多种算法进行特征选择分析,通过ACE算法分析特征和标签之间的非线性关系。

特征关系分析
2.2 丰富多样的数据处理能力
NAIE交互式特征工程内置了数据采样,数据增强,数据清洗,特征转换,特征选择,特征提取等常用的数据处理算子,用户可以根据需要通过界面点击操作即可完成常用的数据处理。
通过数据采样在不引入外部数据的情况下调整数据样本数目和类分布。

通过数据增强引入外部数据扩展当前数据集的样本数目或字段数目。

通过数据清洗对数据进行审查和校验,删除重复信息,纠正错误,处理无效值和缺失值,提供数据的一致性。

通过特征转换对现有的特征进行归一化或编码等变换操作,便于更好的表征学习的问题。

通过特征选择剔除不相关或冗余的特征,提高模型精度,减少模型运行时间,增强模型的可解释性。
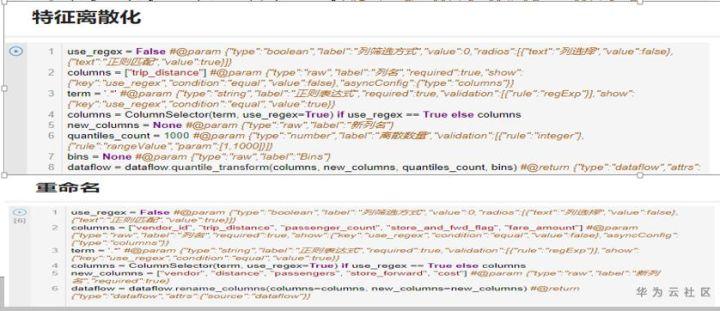
通过特征提取从原始数据中构建出富含信息且不冗余的特征。
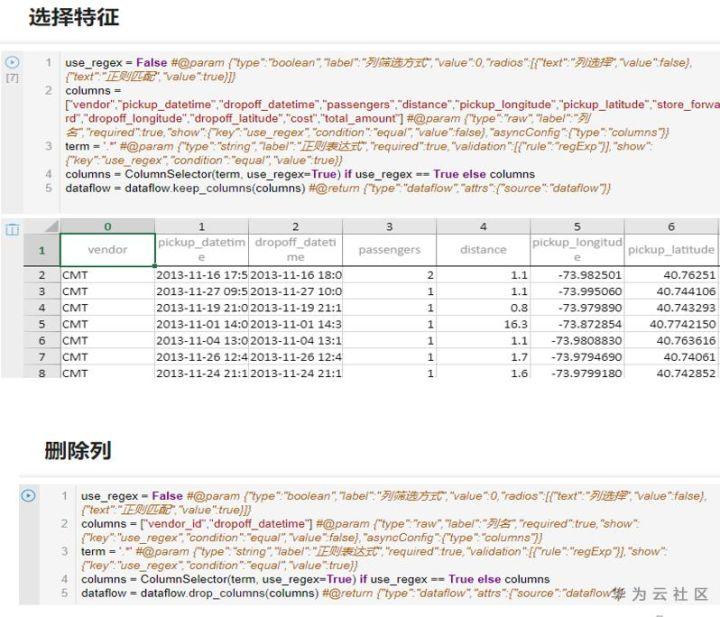
2.3 可伸缩的数据处理引擎
NAIE交互式特征工程预置python3和pyspark两种数据处理引擎,python3引擎使用开源pandas数据处理框架进行数据处理,一般用于中小规模(10G以下)的数据处理。pyspark使用开源spark大规模数据(10G-500G)处理引擎进行数据处理,通过分布式数据处理能力,支持可伸缩的大数据处理。NAIE特征工程内置的数据处理算子使用统一的对外SDK,适配不同的数据处理实现,可以满足在探索阶段使用python处理引擎,在产品阶段大数据场景下代码不做任何修改无缝适配到spark处理引擎下进行大规模可伸缩的数据处理。
NAIE交互式特征工程的应用
在日常出行时,当打开某款打车软件的时候,输入起始地点和结束地点,打车软件系统会自动估算出一个价格,用户可以根据价格选择是否乘坐或选择乘坐哪种类型。
车费除了依赖于乘车距离,还与乘车时间,乘车地点等多种因素有关,没有一个精确的公式可以计算。
通过机器学习学习历史数据训练模型进行预测是越来越流行的做法,通常的机器学习工作流中包含数据的预处理,模型训练,模型评估,模型部署预测等几个环节,其中数据预处理环节对于整个过程来说至关重要,以下展示如何使用NAIE交互式特征工程进行出租车乘车记录数据的预处理过程。
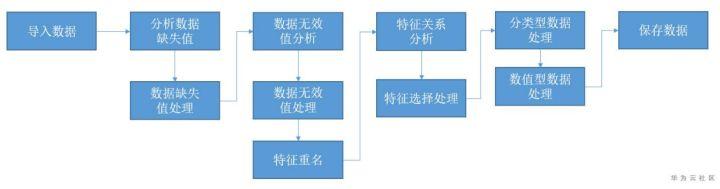
通过使用NAIE交互式特征工程,用户可以通过界面操作一键式完成数据的可视化探索,了解数据的统计分布,质量情况,特征间的关系等,从而直观的获取数据的洞察结果。结合NAIE交互式特征工程沉淀的多种开箱即用的数据处理能力,用户只需要通过菜单选择相关的数据处理算子,即可完成复杂的数据处理任务。相比于传统的开发代码进行数据分析和处理方式,NAIE交互式特征工程极大的降低了数据分析处理的门槛,通过复用华为工程师在此领域沉淀的专家经验,对数据分析和处理的效率也有极大的提升。















