
在本系列的第三章中介绍了 clickhouse 通过 block 和 lsm 来减少磁盘读取的数据量。严谨的逻辑应该时 clickhouse 通过 lsm 算法来实现数据预排序,从而减少了磁盘读取的数据量,本章番外主要为读者介绍什么是 LSM 算法,对 LSM 算法已经有了解的读者可以跳过本章。
LSM 算法最早出现在 1991 年的 ACM 期刊上,之后其思想在各大大数据存储系统中被广泛使用,例如 LevelDB,HBase,Cassandra……LSM 算法由于适应的场景不同,存在很多的变体,clickhouse 也使用 lsm 算来实现其预排序的功能,本文将着重介绍 clickhouse 中的使用,同时也会适当涉及一些其他系统的使用用以让读者体会架构设计的随心所欲。
我们都知道,用户在调用 insert 向 clickhouse 插入数据时,数据不一定是按已经按照排序键排序好的数据,大概率是乱序数据。那么这种乱序的请求如何做到写入磁盘时变得有序呢?这个就是 LSM 算法实现的。
LSM 算法的几个核心步骤:
- 在于数据写入存储系统前首先记录日志,防止系统崩溃
- 记录完日志后在内存中以供使用,当内存达到极限后写入磁盘,记录合并次数 Level 为 0(L=0)。已经写入磁盘的文件不可变。
- 每过一段时间将磁盘上 L 和 L+1 的文件合并
我们用一个示例来展示下整个过程
T=0 时刻,数据库为空。
T=1 时刻,clickhouse 收到一条 500 条 insert 的插入请求,这 500 条数据时乱序的。此时,clickhouse 开始插入操作。首先将 500 条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时 L=0;
T=2 时刻,clickhouse 收到一条 800 条 insert 的插入请求,这 800 条数据时乱序的。此时,clickhouse 开始插入操作。首先将 800 条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时 L=0;
T=3 时刻,clickhouse 开始合并,此时此刻,磁盘上存在两个 L=0 的文件。这两个文件每个文件内部有序,但可能存在重合。(例如第一批 500 条的范围是 300-400,第二批 800 条数据的范围是 350-700)。因此需要合并。clickhouse 在后台完成合并后,产生了一个新的 L=1 的文件。将两个 L=0 的文件标记为删除。
T=4 时刻,clickhouse 开始清理,将两个被标记为删除的文件真正地物理删除。
T=5 时刻,clickhouse 收到一条 100 条 insert 的插入请求,这 100 条数据时乱序的。此时,clickhouse 开始插入操作。首先将 100 条插入请求一次性写入日志。接着在内存中进行排序,排序完成后将有序的结果写入磁盘,此时 L=0;
T=6 时刻,clickhouse 开始合并,此时此刻,磁盘上存在 1 个 L=0 的文件和 1 个 L=1 的文件。这两个文件每个文件内部有序,但不存在重合。(例如 L0 文件的范围是 100-200,L1 文件的范围是 300-700)。因此不需要合并。clickhouse 在后台将 L=0 的文件升级成 L=1,此时数据库内存在两个 L=1 的互不重合的文件。
……
以上就是 LSM 算法在 clickhouse 上的应用,我们总结一下,clickhouse 使用 LSM 算法将乱序的数据在内存中排序为有序的数据,然后写入磁盘保存,并且定期合并有重合的磁盘文件。
不难发现,上述所有的过程对于磁盘的来说都是顺序写,因此这个也是 LSM 算法的一个特点——可以将大量的随机写入转换为顺序写入从而减少磁盘 IO 时间。leveldb 就借助了 lsm 的这个特性。当然,clickhouse 并没有使用到这个特性。下面会将简单介绍下 leveldb 是如何使用 LSM 的。
clickhouse 借助 LSM 实现了预排序的功能,提高了磁盘的利用率,但也同时带来了一些牺牲。再次强调,没有完美的架构,当架构解决一个问题的同时,一定会带来一个全新的问题。
对于 clickhouse 也一样,读者们已经知道了,clickhouse 会在多次 insert 请求时创建独立的数据文件。虽然 clickhouse 会在合适时间进行合并,但如果查询发生在合并前,就有可能数据分布在两个数据文件内。此时 clickhouse 默认会返回两个列表,这两个列表内部有序,但相互之间却会有重合。这就给用户使用带来了不便,下图展示了这种情况。
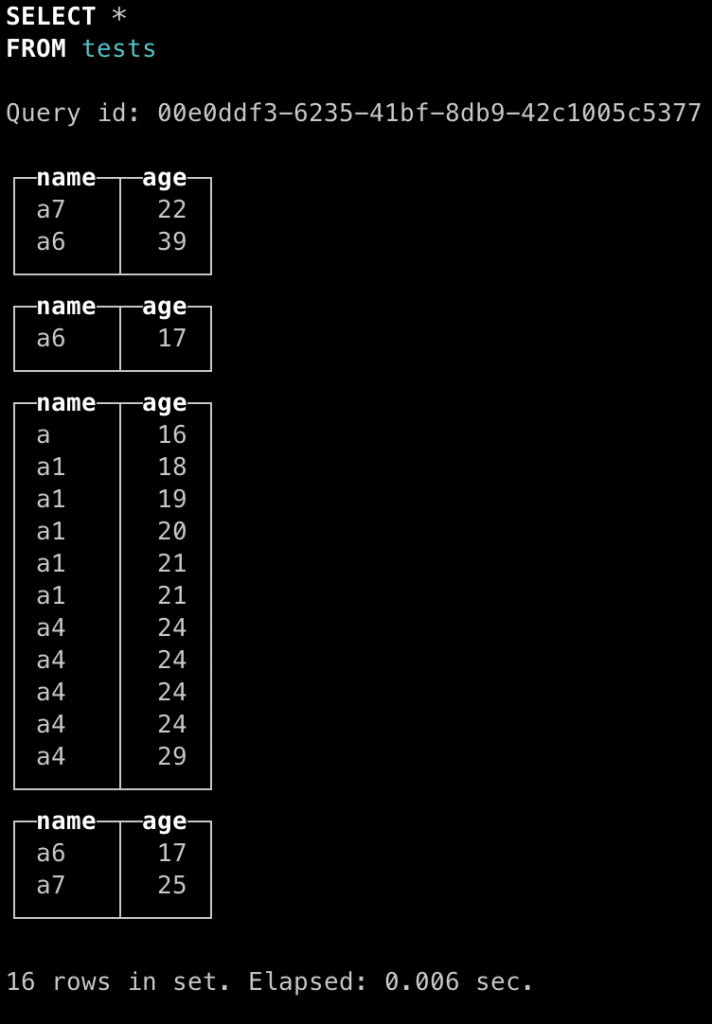
可以看出,此时 clickhouse 未合并时查询结果分成了 4 个独立的结果,每个结果内部有序,但相互之间存在重合,也就说对于这种情况需要用户自行合并。我们等待其合并后再次查询,结果如下:
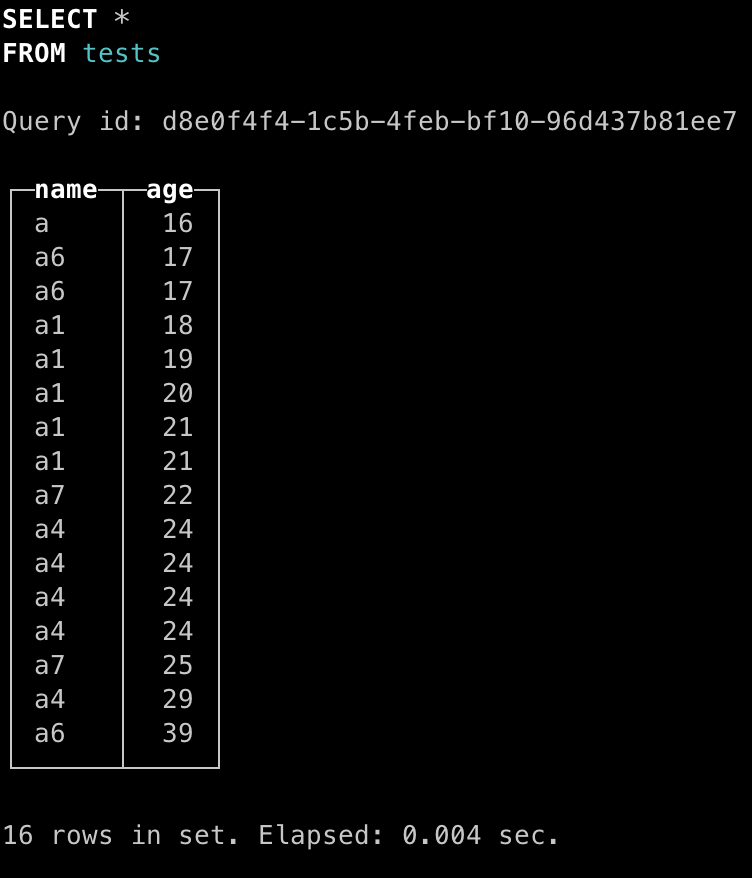
clickhouse 合并后就能解决该问题。
LevelDB 的用法
leveldb 是一个允许修改的数据库,因此其对于 LSM 的使用和 clickhouse 类似,主要的不同在于写入日志后的操作不同。
clickhouse 在记录日志后,会直接在内存中进行排序,从而写入磁盘。此时如果 clickhouse 又接到一条写入情况,会重新开启一个新的进程。
而 leveldb 在记录日志后,会将数据首先缓存在内存中,等待后续操作继续操作这块内存,直到这块内存被填满,才会一次性将数据写入磁盘。
这个差异主要时两个数据库面向的场景不同,clickhouse 主要面向读多写少的分析场景,强调大批量一次性写入增加吞吐量。而 leveldb 主要面向写多读少的业务场景,强调低延时。
吞吐量和延时一向是互相对立的两个指标,不同系统都在这两个指标之间存在取舍。后续有机会我也会写一篇关于这两个指标之间的相爱相杀,以及知名开源软件在这两个指标之间的思考。
感想
扯回来,正因为面向的场景不同,clickhouse 和 leveldb 对 LSM 的使用存在着不同。这也给了我们一个启发,作为架构师,我们要做到运用之妙存乎一心。要能够了解我们正在设计的业务的需求是什么,然后进行符合需求的修改。而不是无脑地认为 LSM 一定是用在写多读少的场景。
做到这一点会有点难,但幸好我们可以站在前人肩膀上,多体会一下前人设计的精妙绝伦的架构。有了这样的经验和思考,我们在遇到相同问题的时候就能做到更深的思考。
这也是我写这个系列的原因,clickhouse 真的是工程师设计的典范之作,整个 clickhouse 没有发明新的科学理论,但却让我们看到了借助已有的理论也能将性能在某一方面发挥到极致,这种追求极致的工程师精神让我深深着迷,我觉得我需要将这种精妙的设计思想的传递给大家。希望有朝一日,我们中国的工程师也能将极致的产品带给世界。因为有你,因为有我,许许多多平凡而伟大的工程师的共同努力,这一天一定能够到来。向 clickhouse 的研发团队致敬。










