
K8s容器编排
Kubernetes(k8s)****具有完备的集群管理能力:
- 包括多层次的安全防护和准入机制
- 多租户应用支撑能力
- 透明的服务注册和服务发现机制
- 内建智能负载均衡器
- 强大的故障发现和自我修复能力
- 服务滚动升级和在线扩容能力
- 可扩展的资源自动调度机制
- 以及多粒度的资源管理能力
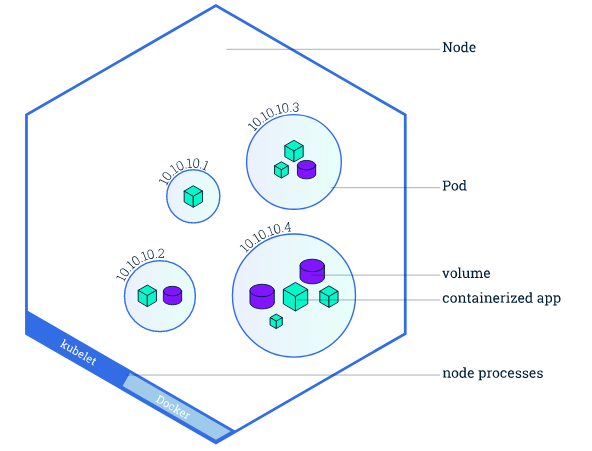
Pod是在K8s集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod的设计理念是支持多个容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。Pod对多容器的支持是K8s最基础的设计理念。Pod是K8s集群中所有业务类型的基础,可以看作运行在K8s集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。
在K8s中,所有的容器均在Pod中运行,一个Pod可以承载一个或者多个相关的容器,同一个Pod中的容器会部署在同一个物理机器上并且能够共享资源。
一个Pod也可以包含0个或者多个数据卷组(volumes),这些卷组将会以目录的形式提供给一个容器,或者被所有Pod中的容器共享,对于用户创建的每个Pod,系统会自动选择那个健康并且有足够容量的机器,然后创建类似容器的容器,当容器创建失败的时候,容器会被node agent自动的重启,这个node agent 叫 kubelet,但是,如果是Pod失败或者机器它不会自动的转移并且启动,除非用户定义了 replication controller。
用户可以自己创建并管理Pod。K8s将这些操作简化为两个操作:可以基于相同的Pod配置文件部署多个Pod复制品;
创建可替代的Pod,当一个Pod挂了或者机器挂了的时候。而K8s API中负责来重新启动,迁移等行为的部分叫做“replication controller”,它根据一个模板生成了一个Pod,然后系统就根据用户的需求创建了许多冗余,这些冗余的Pod组成了一个整个应用或者服务或者服务中的一组。
一旦一个Pod被创建,系统就会不停的监控Pod的健康情况以及Pod所在主机的健康情况,如果这个Pod因为软件原因挂掉了或者所在的机器挂掉了,replication controller 会自动在一个健康的机器上创建一个一摸一样的Pod,来维持原来的Pod冗余状态数量不变,一个应用的多个Pod可以共享一个机器。
Kubernetes直接管理Pod而不是容器:一个pod可以是一个容器,也可以是多个容器,例如你运行一个服务项目,其中需要使用nginx、mysql、tomcat,可以将这三个应用在同一个pod中,对他们提供统一的调配能力。一个pod只能运行在一个主机上,而一个主机上可以有多个pod。
1、复制控制器(Replication Controller,RC)
RC是K8s集群中保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动运行新的Pod副本;多于指定数目,RC就会杀死多余的Pod副本。即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有1个Pod在运行。RC只适用于长期伺服型的业务类型,比如控制小机器人提供高可用的Web服务。
2、副本集(Replica Set,RS)
RS是新一代RC,提供同样的高可用能力,区别主要在于RS后来居上,能支持更多种类的匹配模式。副本集对象一般不单独使用,而是作为Deployment的理想状态参数使用。
3、部署(Deployment)
部署表示用户对K8s集群的一次更新操作。部署是一个比RS应用模式更广的API对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。
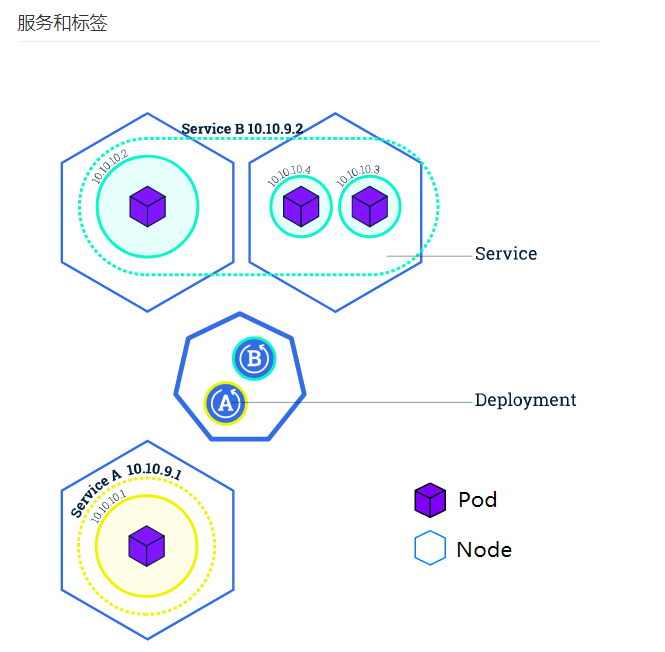
4、服务(Service)
RC、RS和 Deployment只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。
一个Pod只是一个运行服务的实例,随时可能在一个节点上挂掉,在另一个节点以一个新的IP启动一个新的Pod,因此不能以固定的IP和端口号对外提供服务。要稳定地提供服务需要服务发现和负载均衡能力。每个Service会对应一个集群内部有效的虚拟VIP,集群内部通过VIP访问一个服务。在K8s集群中微服务的负载均衡是由Kube-proxy负载均衡器来实现的。它是一个分布式代理服务器,在K8s的每个节点上都有一个。
5、名称空间(Namespace)
名称空间为K8s集群提供虚拟的隔离作用,K8s集群初始有两个名称空间:默认名称空间 default、系统名称空间 kube-system。
除此以外,管理员可以创建新的名称空间满足需要。
6、存储卷(Volume)
K8s集群中的存储卷跟Docker的存储卷有些类似,只不过Docker的存储卷作用范围为一个容器,而K8s的存储卷的生命周期和作用范围是一个Pod。
每个Pod中声明的存储卷由Pod中的所有容器共享。
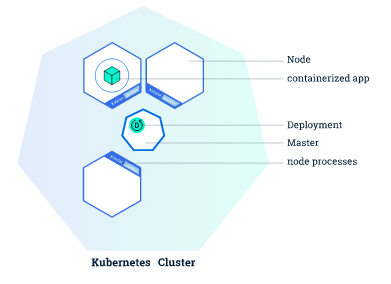
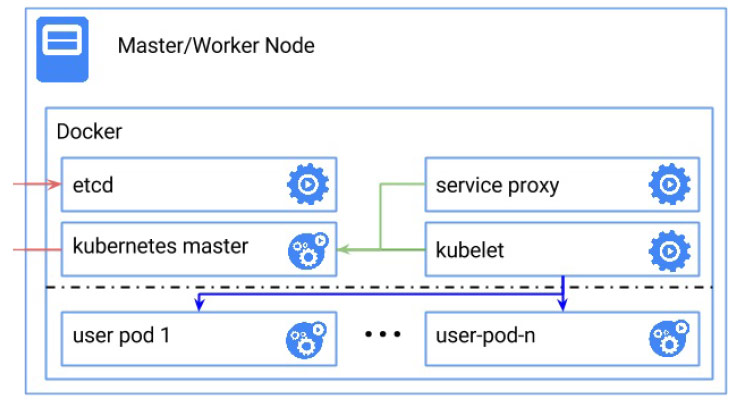
集群中 master 节点上运行三个进程:
分别是:kube-apiserver,kube-controller-manager和kube-scheduler。
群集每个node节点都运行两个进程:
kubelet,与Kubernetes Master进行通信。
kube-proxy,一个网络代理,反映每个节点上的Kubernetes网络服务。
https://kubernetes.io/docs/tutorials/kubernetes-basics/
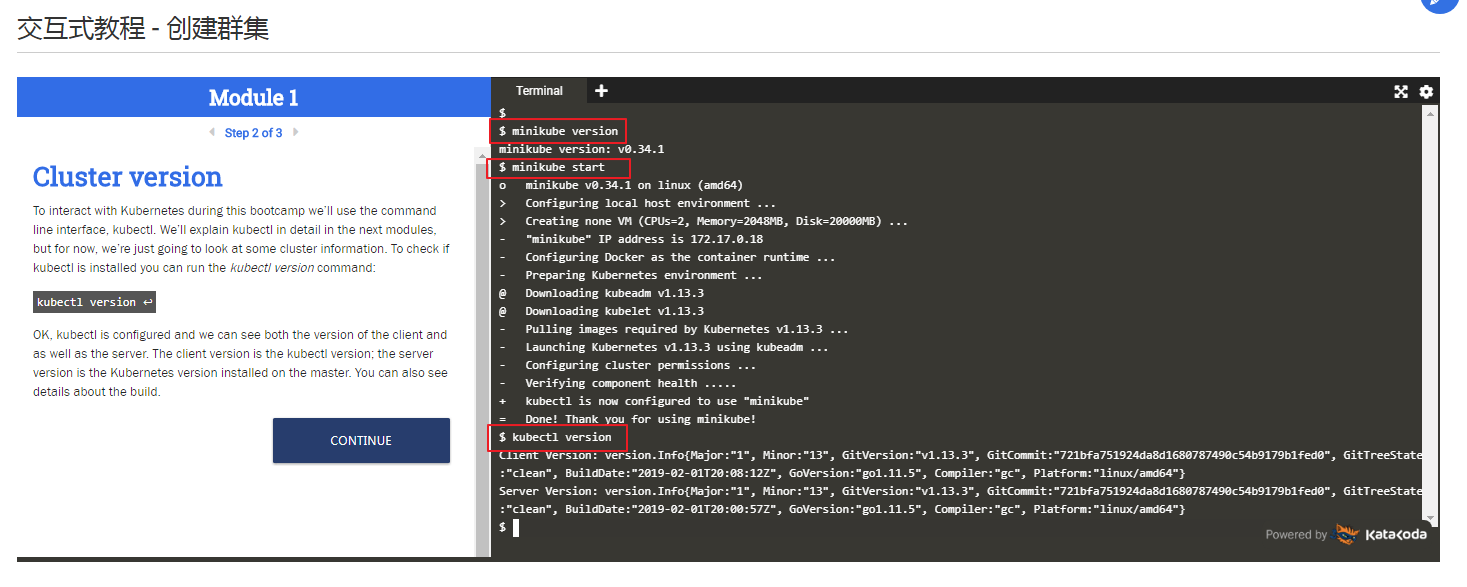
使用Katacoda在运行Minikube的Web浏览器中运行虚拟终端,这是一个可以在任何地方运行的Kubernetes的小规模本地部署。
无需安装任何软件或配置任何东西; 每个交互式教程都直接从您的Web浏览器本身运行。在命令行进行单击就可以,无需手动输入
中文文档:http://docs.kubernetes.org.cn/
在Kubernetes上部署您的第一个应用程序
使用Kubernetes命令行界面Kubectl创建和管理部署,创建部署时,您需要指定应用程序的容器映像以及要运行的副本数。
`kubectl run kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1 --port=8080
kubectl get deployments
kubectl proxy
curl http://localhost:8001/version
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}') echo Name of the Pod: $POD_NAME
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME/proxy/
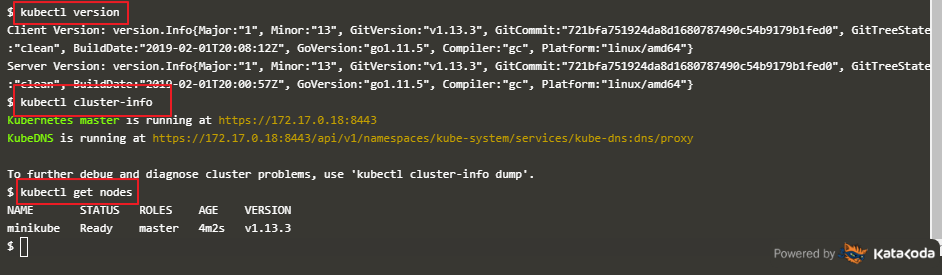
查看节点信息和pod信息`
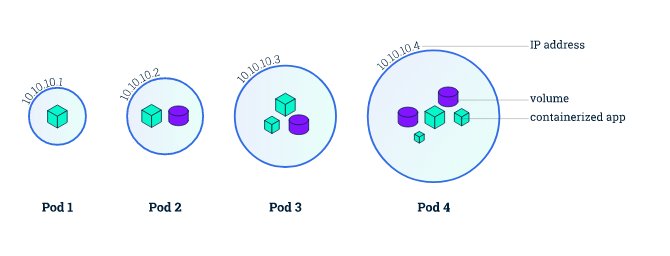
一个node节点可以部署多个pod,一个pod可以部署一个或多个app和volume
kubectl get pods 获取列表资源
kubectl describe pods 显示有关资源的详细信息
kubectl logs $POD_NAME 从pod中的容器打印日志
kubectl exec $POD_NAME env 在pod中的容器上执行命令
kubectl exec -ti $POD_NAME bash
cat server.js
curl localhost:8080
exit
您可以使用这些命令查看应用程序的部署时间,当前状态,运行位置以及配置。
如何对外暴露我们的应用(通过service服务)
Kubernetes服务是一个抽象层,它定义了一组逻辑Pod,并为这些Pod启用外部流量暴露,负载平衡和服务发现。
不同方式公开服务:
ClusterIP(默认) - 在群集中的内部IP上公开服务。此类型使服务只能从群集中访问。
NodePort - 使用NAT在集群中每个选定节点的同一端口上公开服务。使用可从群集外部访问服务<NodeIP>:<NodePort>。ClusterIP的超集。
LoadBalancer - 在当前云中创建外部负载均衡器(如果支持),并为服务分配固定的外部IP。NodePort的超集。
ExternalName - externalName通过返回带有名称的CNAME记录,使用任意名称(在规范中指定)公开服务。没有代理使用。此类型需要v1.7或更高版本kube-dns。
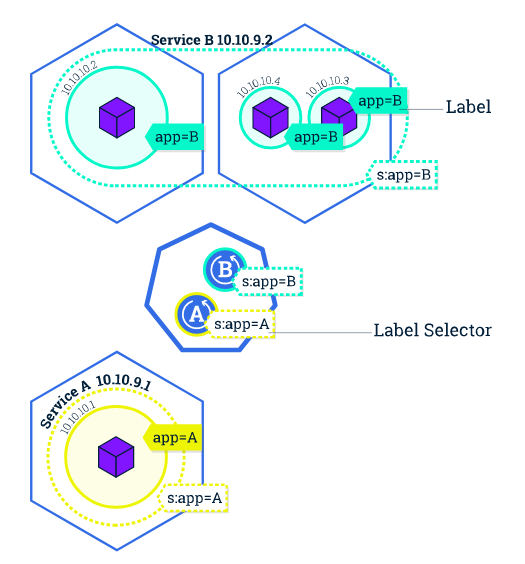
服务使用标签和选择器匹配一组Pod,这是一个允许对Kubernetes中的对象进行逻辑操作的分组。标签是附加到对象的键/值对,可以以多种方式使用:
- 指定用于开发,测试和生产的对象
- 嵌入版本标签
- 使用标记对对象进行分类
kubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080
kubectl get services
kubectl delete service -l run=kubernetes-bootcamp

Pod数量的扩容和缩容
您可以使用kubectl run命令的--replicas参数从头开始创建具有多个实例的Deployment
kubectl get deployments
kubectl scale deployments/kubernetes-bootcamp --replicas=4
kubectl get pods -o wide
kubectl describe deployments/kubernetes-bootcamp
kubectl describe services/kubernetes-bootcamp
kubectl scale deployments/kubernetes-bootcamp --replicas=2
滚动更新:
*滚动更新允许通过使用新的实例逐步更新Pods实例来实现部署的更新,从而实现0停机。新的Pod将在具有可用资源的节点上进行调度。*
滚动更新允许以下操作:
- 将应用程序从一个环境推广到另一个环境(通过容器映像更新)
- 回滚到以前的版本
- 持续集成和持续交付应用程序,无需停机
kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2
kubectl rollout status deployments/kubernetes-bootcamp
kubectl rollout undo deployments/kubernetes-bootcamp
如何通过Docker创建一个单机、单节点的Kubernetes集群
解决方案:docker本地服务器方案、托管方案、全套云端方案、定制方案
如果你只是想试一试Kubernetes,我们推荐基于Docker的本地方案。
基于Docker的本地方案是众多能够完成快速搭建的本地集群方案中的一种,但是局限于单台机器。
Vagrant 是一款用来构建虚拟开发环境的工具,非常适合 php/python/ruby/java 这类语言开发 web 应用,“代码在我机子上运行没有问题”这种说辞将成为历史。
我们可以通过 Vagrant 封装一个 Linux 的开发环境,分发给团队成员。成员可以在自己喜欢的桌面系统(Mac/Windows/Linux)上开发程序,代码却能统一在封装好的环境里运行,非常霸气。
Vagrant的安装
本文教程的虚拟机是基于VirtualBox的(VMWare也可以,但是需要破解),下面来介绍安装VirtualBox和Vagrant的安装。
1、VirtualBox的安装
下载地址:https://www.virtualbox.org/wiki/Downloads
历史版本:https://www.virtualbox.org/wiki/Download_Old_Builds_4_3_pre24
2、Vagrant的安装
https://www.vagrantup.com/downloads.html
3. centos7.box:
http://cloud.centos.org/centos/7/vagrant/x86_64/images/

3、版本兼容性
VirtualBox:自版本4.3.12后启动虚拟机会存在各种问题,因此建议安装4.3.12版本。
Vagrant:从1.0.x可以直接升级到1.x版本,Vagrant向后兼容Vagrant1.0.x,但是1.1+版本不在支持1.0.x版本的插件,因此插件也要做相应升级。
4、其他安装建议
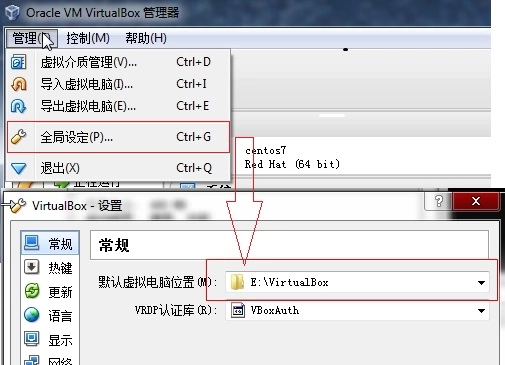
建议安装好之后将VirtualBox的虚拟机位置设置到其他盘,否则占用默认C盘空间较大,已安装的虚拟机需要移动到新的目录下,具体设置办法请见下图:
Vagrant启动
简单来说,使用以下两条命令就可以启动一个Vagrant环境了:
$ vagrant init hashicorp/precise32 $ vagrant up
通过上面两个命令,就可以在VirtualBox中启动并运行Ubuntu 12.04 LTS 32-bit了,可以使用命令vagrant ssh登录到这台虚拟机上,当完成一切操作之后,可以使用vagrant destroy命令来销毁它。
下面我们分步骤来介绍怎么配置并且启动一个基于VirtualBox虚拟机的Vagrant环境:
1、建立工程(Project)
开始任何一个项目需要一个名为Vagrantfile的文件来配置Vagrant,这个文件的作用有一下两个:
- 标识Vagrant项目的根目录,后续的大部分Vagrant配置都与此目录有关。
- 描述工程启动所需的虚拟机类型和资源,以及需要安装的软件和你的访问方式。
可以使用命令vagrant init来初始化项目目录,可以按照以下步骤操作
$ mkdir vagrant_project $ cd vagrant_project $ vagrant init
这样在当前目录下就会生成名为Vagrantfile的文件,当然也可以在已有的工程目录下执行vagrant init命令来初始化生成这个文件。
2、添加虚拟机(Boxes)
可以使用命令vagrant box add来添加虚拟机,例如要添加Ubuntu12.04,我们可以使用:
$ vagrant box add hashicorp/precise32
在不进入虚拟机的情况下,还可以使用下面的命令对 虚拟机进行管理:
vagrant up (启动虚拟机)
vagrant halt (关闭虚拟机——对应就是关机)
vagrant suspend (暂停虚拟机——只是暂停,虚拟机内存等信息将以状态文件的方式保存在本地,可以执行恢复操作后继续使用)
vagrant resume (恢复虚拟机 —— 与前面的暂停相对应)
vagrant destroy (删除虚拟机,删除后在当前虚拟机所做进行的除开Vagrantfile中的配置都不会保留)
当在启动Vagrant后,对于虚拟机有进行过安装环境相关的配置,如果并不希望写在Vagrant的启动shell里面每次都重新安装配置一遍,可以将当前配置好的虚拟机打包成box,
vagrant package --output NAME --vagrantfile FILE
先决条件
1. 你必须拥有一台安装有Docker的机器。
2. 你的内核必须支持 memory内存 和 swap交换分区 accounting 。确认你的linux内核开启了如下配置:
CONFIG_RESOURCE_COUNTERS=y
CONFIG_MEMCG=y
CONFIG_MEMCG_SWAP=y
CONFIG_MEMCG_SWAP_ENABLED=y
CONFIG_MEMCG_KMEM=y
第一步:运行Etcddocker run --net=host -d gcr.io/google_containers/etcd:2.0.12 /usr/local/bin/etcd --addr=127.0.0.1:4001 --bind-addr=0.0.0.0:4001 --data-dir=/var/etcd/data
第二步:启动master
docker run -d \
--volume=/:/rootfs:ro \
--volume=/sys:/sys:ro \
--volume=/dev:/dev \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/var/lib/kubelet/:/var/lib/kubelet:rw \
--volume=/var/run:/var/run:rw \
--net=host \
--pid=host \
--privileged=true \
gcr.io/google_containers/hyperkube:v1.0.1 \
/hyperkube kubelet --containerized --hostname-override="127.0.0.1" --address="0.0.0.0" --api-servers=http://localhost:8080 --config=/etc/kubernetes/manifests
这一步实际上运行的是 kubelet ,并启动了一个包含其他master组件的[pod](../userguide/pods.md)。
第三步:运行service proxy
docker run -d --net=host --privileged gcr.io/google_containers/hyperkube:v1.0.1 /hyperkube proxy --master=http://127.0.0.1:8080 --v=2
如果你运行了不同的Kubernetes集群,你可能需要指定 -s http://localhost:8080 选项来访问本地集群。
运行一个应用
kubectl -s http://localhost:8080 run nginx --image=nginx --port=80
运行 docker ps 你应该就能看到nginx在运行。下载镜像可能需要等待几分钟。
暴露为service
kubectl expose rc nginx --port=80
运行以下命令来获取刚才创建的service的IP地址。有两个IP,第一个是内部的
(CLUSTER_IP),第二个是外部的负载均衡IP。
kubectl get svc nginx
同样你也可以通过运行以下命令只获取第一个IP(CLUSTER_IP):
kubectl get svc nginx --template={{.spec.clusterIP}}
通过第一个IP(CLUSTER_IP)访问服务:
curl <insert-cluster-ip-here>
关于关闭集群的说明
上面的各种容器都是运行在 kubelet 程序的管理下,它会保证容器一直运行,甚至容器意外退出时也不例外。所以,如果想关闭集群,你需要首先关闭 kubelet 容器,再关闭其他。
可以使用 docker kill $(docker ps -aq) 。注意这样会关闭Docker下运行的所有容器,请谨慎使用。
CentOS部署Kubernetes集群
前提条件
你需要3台或以上安装有CentOS的机器
启动一个集群
Kubernetes包提供了一些服务:kube-apiserver, kube-scheduler, kube-controller-manager,kubelet, kube-proxy。这些服务通过systemd进行管理,配置信息都集中存放在一个地方:/etc/kubernetes。我们将会把这些服务运行到不同的主机上。第一台主机,centosmaster,将是Kubernetes 集群的master主机。这台机器上将运行kube-apiserver, kubecontroller-manager和kube-scheduler这几个服务,此外,master主机上还将运行etcd。其余的主机,fed-minion,将是从节点,将会运行kubelet, proxy和docker。
单机部署方案 Minikube。kubectl
启动k8s集群:minikube start
命令:a.启动:vagrant up
b. 关机:vagrant halt
c. 重启:vagrant reload
d. 查看运行状态:vagrant status
e. 销毁:vagrant destroy
搭建集群的Kubeadm、kops、play with k8s
环境规划
主机名
操作系统
IP地址
master
Centos 7.4-x86_64
192.168.1.100
node1
Centos 7.4-x86_64
192.168.1.102
node2
Centos 7.4-x86_64
192.168.1.104
临时关闭swap ,永久关闭直接注释fstab中swap行
swap off -a
中文文档:https://www.kubernetes.org.cn
资料:https://idc.wanyunshuju.com/K8S/
Kubernetes提供在线培训的网站:
https://kubernetes.io/docs/tutorials/online-training/overview/
使用交互式实践场景(Katacoda)学习Kubernetes
https://www.katacoda.com/courses/kubernetes/
国外视频教程:
https://linuxacademy.com/linux/training/course/name/kubernetes-quick-start











