
原文出处:https://bohutang.me/2020/08/18/clickhouse-and-friends-merge-tree-wal/
最后更新: 2020-09-18
数据库系统为了提高写入性能,会把数据先写到内存,等“攒”到一定程度后再回写到磁盘,比如 MySQL 的 buffer pool 机制。
因为数据先写到内存,为了数据的安全性,我们需要一个 Write-Ahead Log (WAL) 来保证内存数据的安全性。
今天我们来看看 ClickHouse 新增的 MergeTreeWriteAheadLog (https://github.com/ClickHouse/ClickHouse/pull/8290) 模块,它到底解决了什么问题。
高频写问题
对于 ClickHouse MergeTree 引擎,每次写入(即使1条数据)都会在磁盘生成一个分区目录(part),等着 merge 线程合并。
如果有多个客户端,每个客户端写入的数据量较少、次数较频繁的情况下,就会引发 DB::Exception: Too many parts 错误。
这样就对客户端有一定的要求,比如需要做 batch 写入。
或者,写入到 Buffer 引擎,定时的刷回 MergeTree,缺点是在宕机时可能会丢失数据。
MergeTree WAL
1. 默认模式
我们先看看在没有 WAL 情况下,MergeTree 是如何写入的:

每次写入 MergeTree 都会直接在磁盘上创建分区目录,并生成分区数据,这种模式其实就是 WAL + 数据的融合。
很显然,这种模式不适合频繁写操作的情况,否则会生成非常多的分区目录和文件,引发 Too many parts 错误。
2. WAL模式
设置SETTINGS: min_rows_for_compact_part=2,分别执行2条写 SQL,数据会先写到 wal.bin 文件:

当满足 min_rows_for_compact_part=2 后,merger 线程触发合并操作,生成 1_1_2_1 分区,也就是完成了 wal.bin 里的 1_1_1_0 和 1_2_2_0 两个分区的合并操作。当我们执行第三条 SQL 写入:
insert into default.mt(a,b,c) values(1,3,3)
数据块(分区)会继续追加到 wal.bin 尾部:
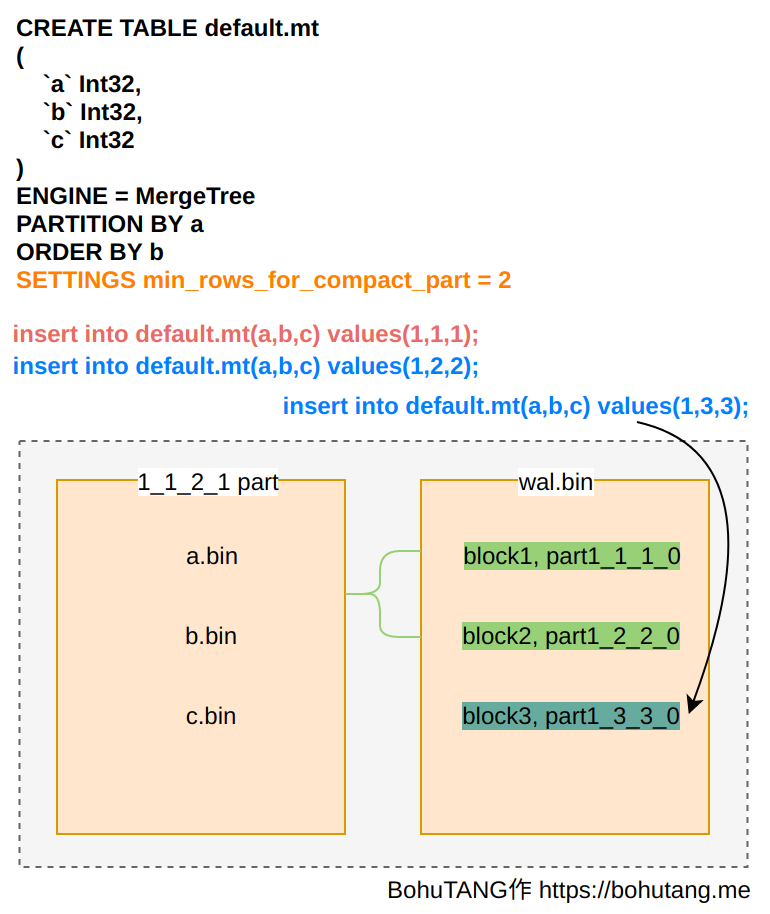
此时,3 条数据分布在两个地方:分区 1_1_2_1, wal.bin 里的 1_3_3_0。
这样就有一个问题:当我们执行查询的时候,数据是怎么合并的呢?
MergeTree 使用全局结构 data_parts_indexes 维护分区信息,当服务启动的时候,MergeTreeData::loadDataParts方法:
1. data_parts_indexes.insert(1_1_2_1)2. 读取 wal.bin,通过 getActiveContainingPart 判断分区是否已经merge到磁盘:1_1_1_0 已经存在, 1_2_2_0 已经存在,data_parts_indexes.insert(1_3_3_0)3. data_parts_indexes:{1_1_2_1,1_3_3_0}
这样,它总是能维护全局的分区信息。
总结
WAL 功能在 PR#8290 (https://github.com/ClickHouse/ClickHouse/pull/8290) 实现,master 分支已经默认开启。
MergeTree 通过 WAL 来保护客户端的高频、少量写机制,减少服务端目录和文件数量,让客户端操作尽可能简单、高效。
全文完。
Enjoy ClickHouse :)
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧

本文分享自微信公众号 - 老叶茶馆(iMySQL_WX)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











